
•
LSTM이나 GRU를 쓰더라도 아주 긴 문장을 처리하는데는 문제가 있다. 이를 해결해 주는게 Attention Model
•
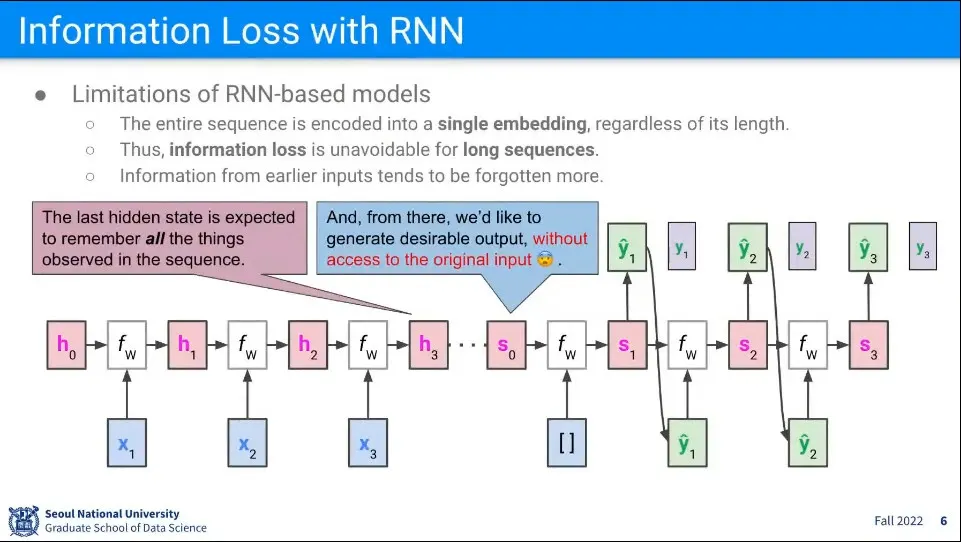
Hidden State의 크기는 몇 Dimension이라고 고정되어 있는데, 거기에 계속 문장을 집어 넣다보면 나중에 그걸 다 기억 못하는 문제가 발생할 수 있음. 이건 물리적인 한계이다.
•
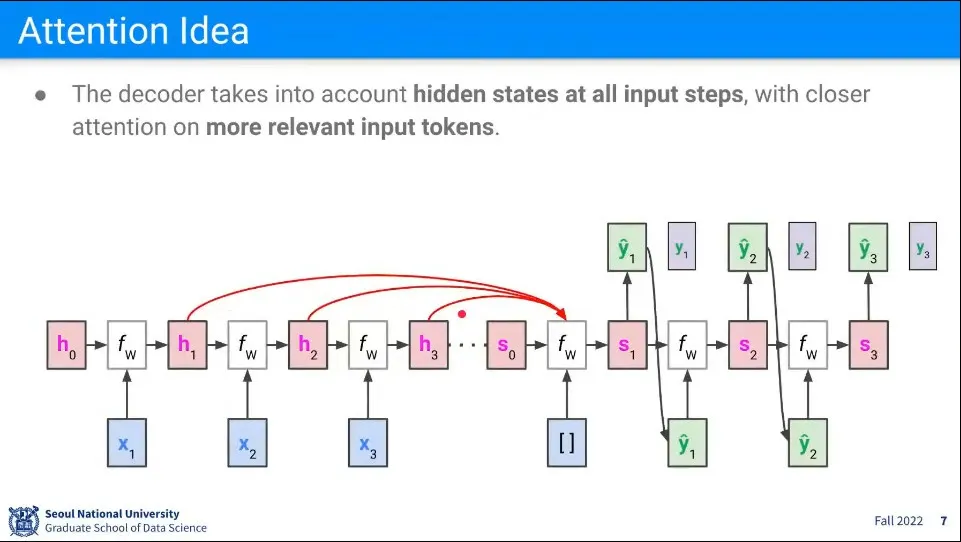
Attention의 아이디어는 Decoder가 Encoder의 마지막 state 뿐만 아니라 그 앞의 모든 hidden state에 대한 access를 가지고 Decoding 하자는 것이다.

•
앞의 hidden state 중에 어느 hidden state를 보는 게 좋을지를 학습하게 하는게 attention
◦
어느 state에 attention 하게 할지를 학습하는 것
•
Attention 함수는 Query, Key, Value로 구성됨. 이것들을 합쳐서 Attention Value를 만든다.
◦
예컨대 ‘나는 학생입니다’를 영어로 번역하는데 현재 ‘I am a’ 까지 번역이 되었다고 치면 그 다음 단어는 ‘학생’이라는 state에 집중해서 student라는 단어를 만들어 내게 된다. 왜냐하면 ‘나는’, ‘입니다’는 이미 ‘I am’를 만드는데 사용되었기 때문. 이미 생성된 것은 버린다.
◦
고로 현재 맥락(query)을 따져서 input(reference)들에 가중치(weighted average)를 준 value를 구해서 attention value로 정의한다.
•
Q는 현재 주어진 상황(context)
•
K는 Reference들의 대표자
•
Value는 Reference 본인
•
Q와 K는 유사도를 계산하는데 사용된다. 따라서 같은 Dimension을 가져야 함.
•
V와 Attention Value도 같은 Dimension을 가져야 함.
◦
대부분의 경우 굳이 다르게 할 필요 없어서 4개를 같은 것을 사용한다.
•
현재 사용하려는 모델에 대해
◦
Q는 현재 시점의 Decoder의 State가 된다. —앞선 이미지의 예에서 스테이트
◦
K는 Encoder의 Hidden State가 된다.
◦
V도 여기서는 K와 같다.

•
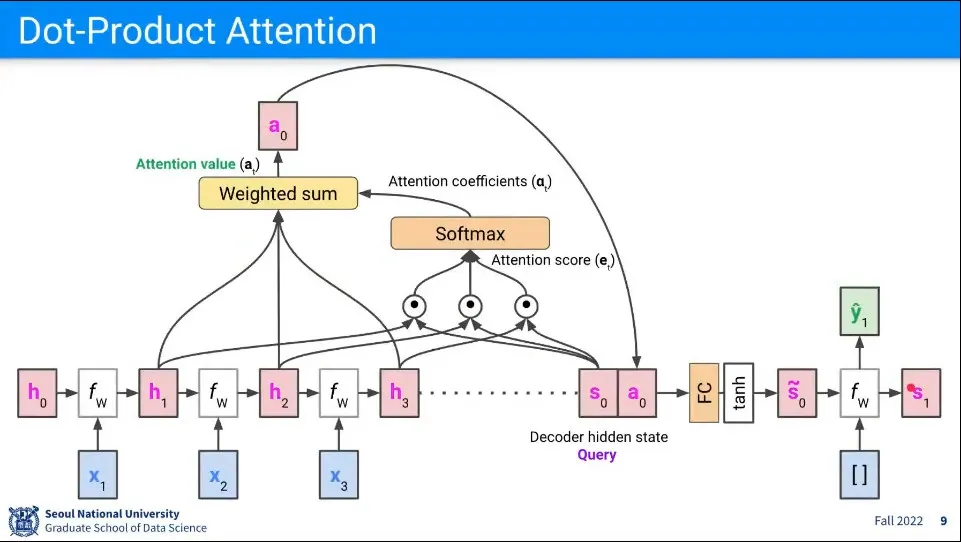
Attention 계산 흐름 예제
◦
Query는 주어진 상황으로 여기서는 Decoder의 hidden state가 된다. 현재는
◦
Key는 reference의 대표자로서 여기서는 Encoder의 hidden state가 된다. 여기서는
◦
유사도를 구하기 위해 와 를 각각 내적하고 그것을 합해서 Attention Score를 구한다.
•
Attention Score를 Softmax를 씌워서 확률로 만든다. 이렇게 된 것을 Attention Coefficients라고 한다.
•
이 예제에서 Value는 Key와 마찬가지로 이므로, 이것을 attention coefficients와 weighted sum을 한다. 그렇게 만들어진 값이 Attention Value가 된다.
•
그렇게 만들어진 Attention Value를 현재 Decoder의 hidden state인 와 합친다.
•
그것을 다시 fully-connected 한 후 tanh 함수를 씌워서 최종적으로 를 구한다.
•
그렇게 만들어진 를 원래 decoder에서 하던 것처럼 계산해서 output()을 만들고 그 다음 에 대해 위의 과정을 반복한다.

•
위 과정에 대한 수식

•
Attention 모델에서는 Query, Key, Value가 무엇이 되는지를 잘 이해해야 함.

•
유사도 구할 때 내적을 할 필요는 없다. 다양한 방법을 사용할 수 있지만 내적이 간편하므로 많이 사용한다.
•
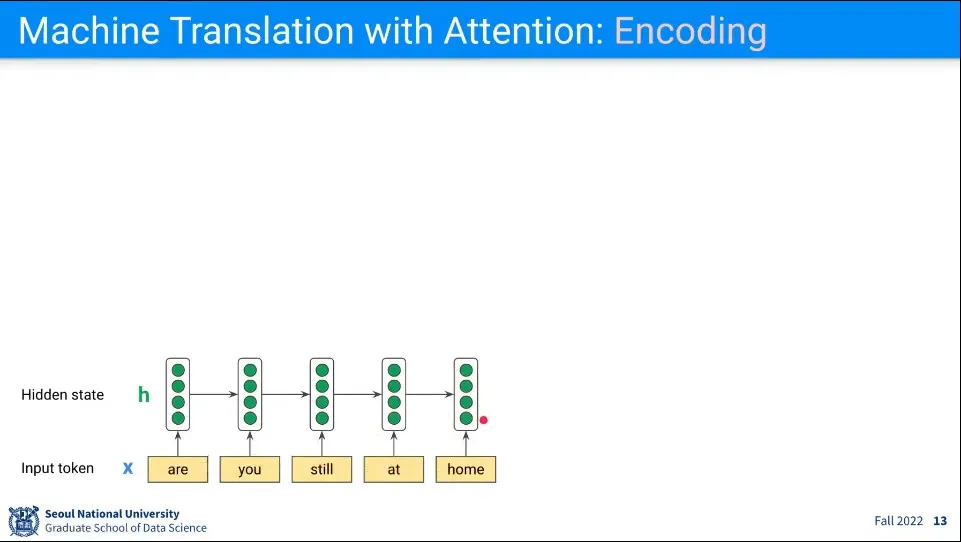
번역에서 Attention 모델을 사용하는 예
◦
우선 Encoding 단계에서는 기존과 동일하다.
•
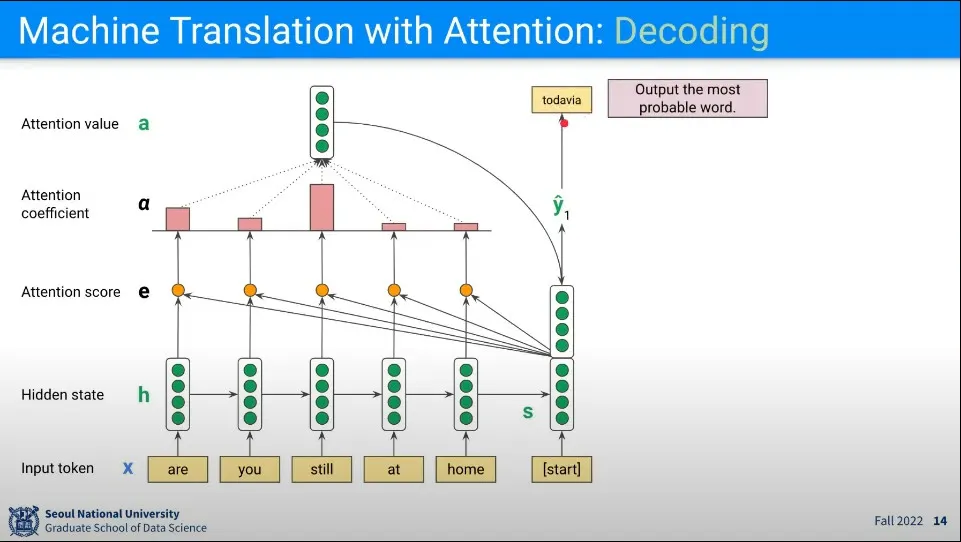
Decoding 단계에서 차이가 있다.
1.
Decoder의 첫 State는 Encoder의 마지막 State를 가져온다.
2.
Encoder의 State들과 유사도 계산(내적)을 해서 Attention Score를 구한다.
3.
전체 Attention Score를 이용해서 Attention Coefficient를 구한다.
4.
Attention Coefficient를 다시 Encoder의 State들과 Weighted Sum해서 Attention Value를 구한다.
5.
Attention Value를 Decoder의 첫 State와 합하고 Fully-Connected를 통과시켜서 를 구한다.
6.
로 을 구한다.
•
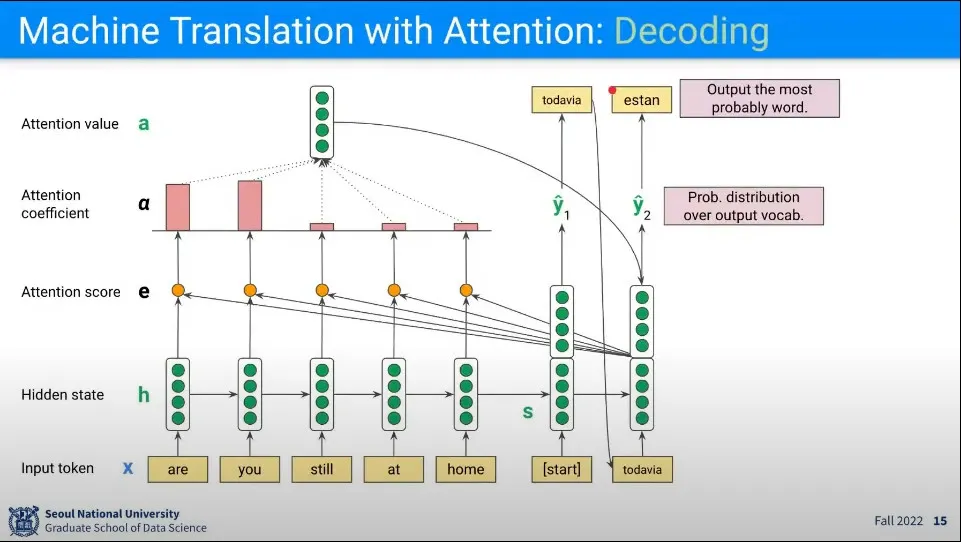
다음 단계에서 이전 Decoder State의 Output()을 Input으로 사용해서 앞선 과정을 반복해서 를 구한다.
•
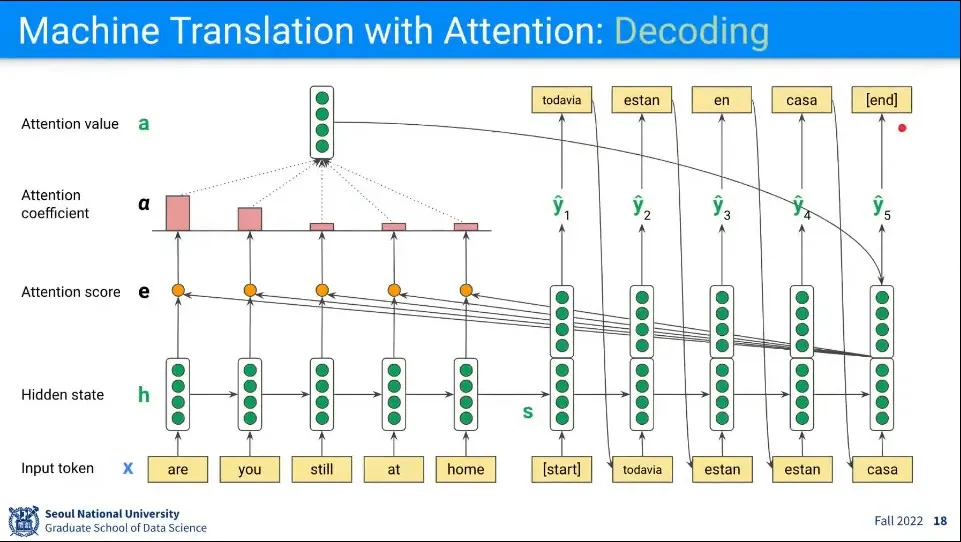
이 과정을 반복해서 최종적으로 [end]가 나오면 종료
•
이런 식으로 하면 긴 문장이 들어와도 이전 데이터를 잃어버리는 문제를 해결할 수 있다.
◦
단점은 계산량
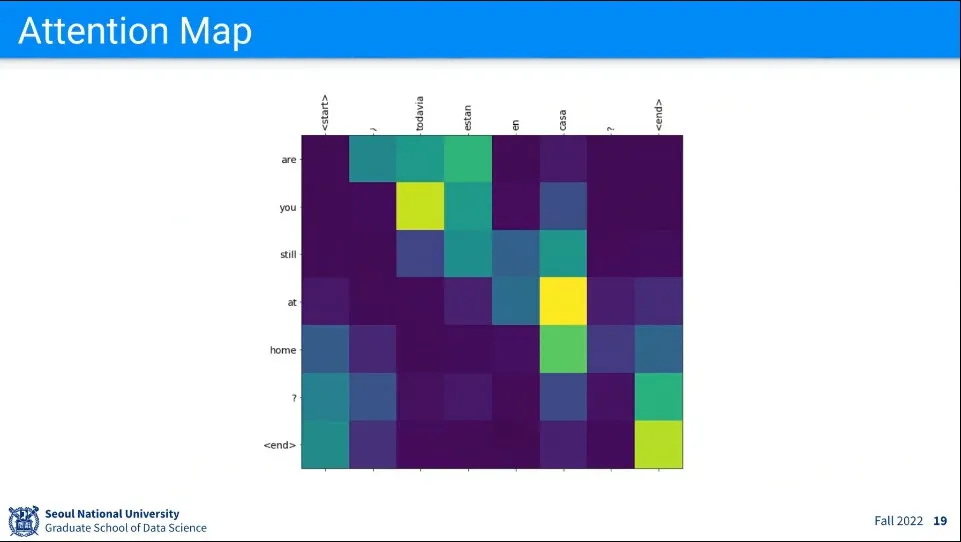
•
앞의 예에 대해 Attention Map을 그린 예

•
기존 머신러닝의 단점이 AI의 결과에 대해 해석이 어렵다는 점이 있는데, Attention은 그래도 해석이 수월함. 어느 부분에 Attention을 했는지를 알 수 있기 때문

•
Transfomers는 Attention을 이용한 구조. NLP는 이미 Transformer가 주류가 됨

•
트랜스포머는 Multi-Headed Self-Attention
•
모델 그림의 왼쪽은 Encoder 부분이고, 오른쪽은 Decoder 부분에 해당한다.
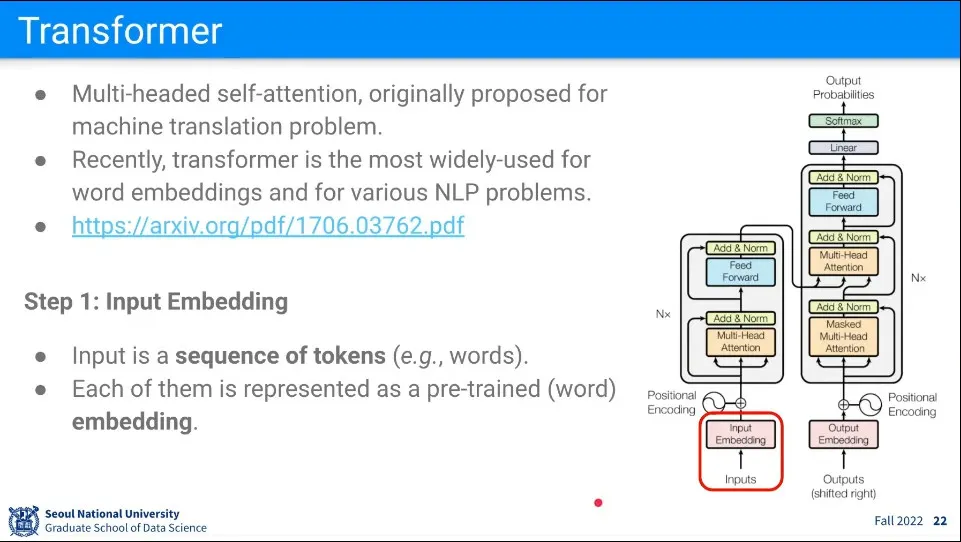
•
첫 단계로 input을 embedding 한다.
◦
트랜스포머는 RNN과 달리 단어를 하나씩 받지 않고 전체를 한 번에 받는다. token들의 sequence이고 token은 무엇이든 될 수 있음
◦
seqeunce를 가진 전체 input을 한 번에 받는다.
◦
단어라면 GloVe 같은 것을 이용한 벡터 형태가 들어오게 됨
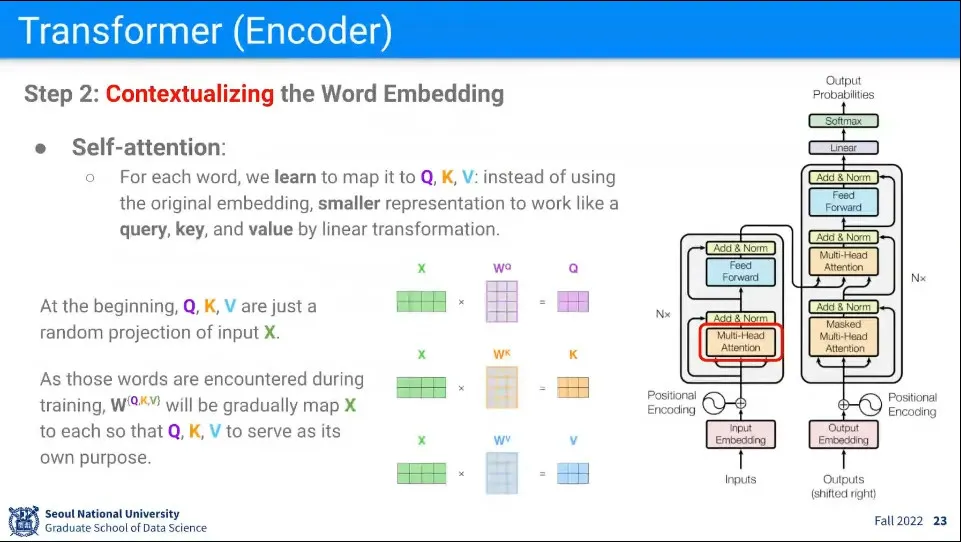
•
다음 단계로 self-attention을 수행한다.
◦
앞선 Encoder-Decoder 예에서와 달리 Inuput에 대해 스스로 Attention을 수행한다.
◦
앞선 예에서 Decoder에서 Q가 Decoder의 State 였던 것에 반해 여기서는 모든 Input이 한 번씩 Q가 되어서 Attention을 수행한다.
◦
모든 Input에 대해 를 곱해서 를 만들어 준다. 는 선형 맵퍼이고 트랜스포머에서는 학습이란 결국 이 배우는 것이 됨.
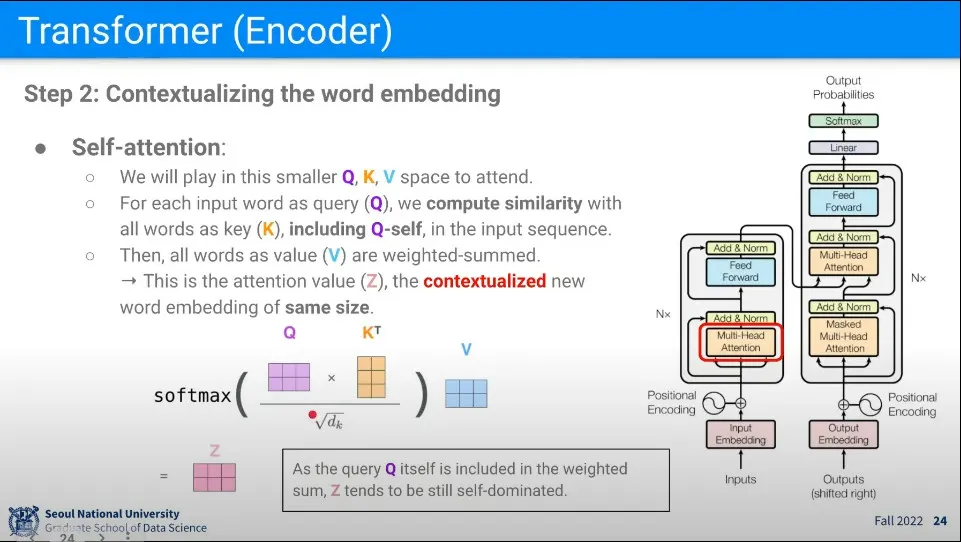
•
모든 단어에 대해 다음의 계산을 수행한다.
1.
자기 자신을 Q로 변환한 것과 전체 단어들을 K로 변환한 것을 내적 해서 유사도를 구한다. 이때 K에는 자기 자신도 포함되게 된다.
•
Input이 N개 일 때 NxN 행렬이 나오게 됨. K에 자기 자신도 포함되기 때문에 NxN 행렬에서 자기 자신끼리 곱한 결과인 주대각선이 아무래도 값이 높게 나오게 됨.
2.
1의 결과에 대해 로 나누고 softmax를 씌운다.
•
는 의 dimension. 로 나누는 이유는 scaling의 목적이다. Q, K의 곱이 매우 커질 수 있기 때문.
3.
2의 결과에 대해 전체 단어들을 V로 변환한 것과 곱해서 Weighted Sum을 구한다. 그 결과를 Z라고 한다.
•
이거는 개념을 분해한 것이지만, 실제로는 행렬끼리 곱이기 때문에 아래의 과정은 반복이 아니라 한 번에 수행된다. 행렬끼리 곱이라 K는 전치행렬을 사용하게 된다.
◦
이렇게 만들어진 Z는 여전히 자기 자신의 점수가 높긴 하지만, 다른 단어들과의 연관도 스며들어 있는 결과가 된다.
•
최초 Input을 Input 내 다른 단어들과 연관시킨 형태로 바꿔주기 때문에 Transformer라고 한다.
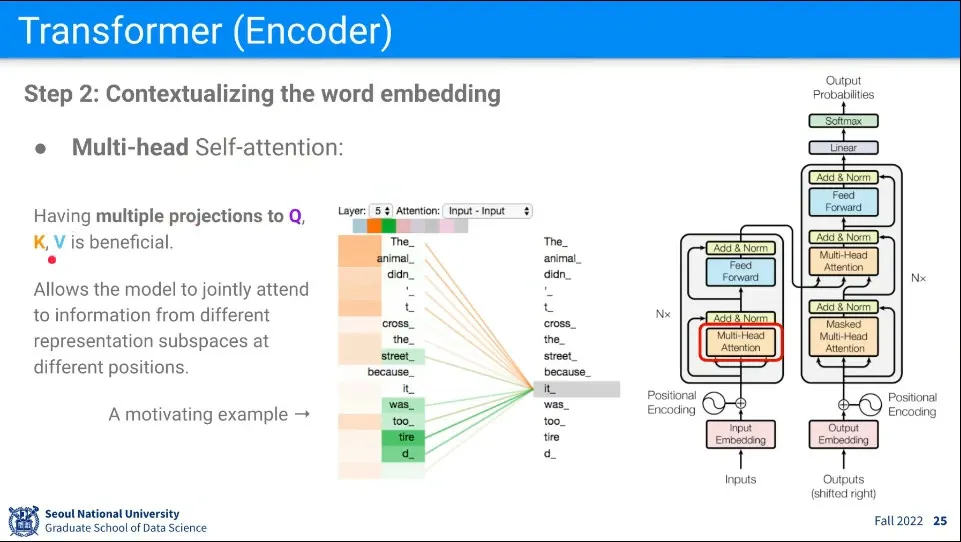
•
위와 같이 사용되는 를 1개만 만들지 않고 여러 개를 만들기 때문에 Multi-Head 라고 한다.
•
여러 개를 쓰는 이유는 하나의 단어가 여러 개의 의미를 갖기 때문에 그것을 표현하는 방법이다.
•
위의 예시에서 It은 문맥 상 Animal을 의미하는데, 이유는 tire라는 단어가 등장하기 때문이다. 만일 narrow라는 단어가 나왔다면 It은 Bridge가 되었을 것이다.

•
를 여러 개 쓰기 때문에 Z 또한 여러 개가 만들어진다.
◦
그 갯수는 사람이 정한다.
•
Z가 여러 개가 되면 처음 Input의 크기와 달라지기 때문에 이것을 처음 크기와 같게 만들어 주는 라는 것을 만들어서 선형 맵핑을 한 번 더 수행해 준다.
•
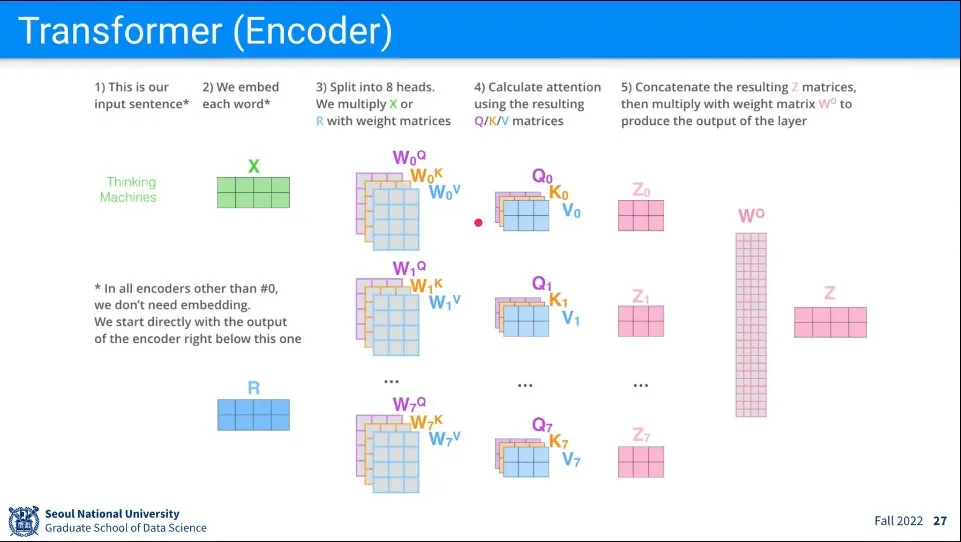
지금까지의 절차
1.
Input Sentence를 벡터로 Embedding 한다.
2.
Input에 대해 를 곱해 를 만든다.
•
가 여러개 있기 때문에 로 표현된다.
3.
Input에 대해 Self Attention을 수행해서 Z를 계산한다.
•
Z도 여러개 있기 때문에 로 표현된다.
4.
각 Z에 대해 를 곱해서 최초 Input의 크기와 같은 크기인 Z를 만든다.
•
이렇게 만들어진 Z는 Input 내 다른 단어들의 의미가 묻어 있게 된다.
•
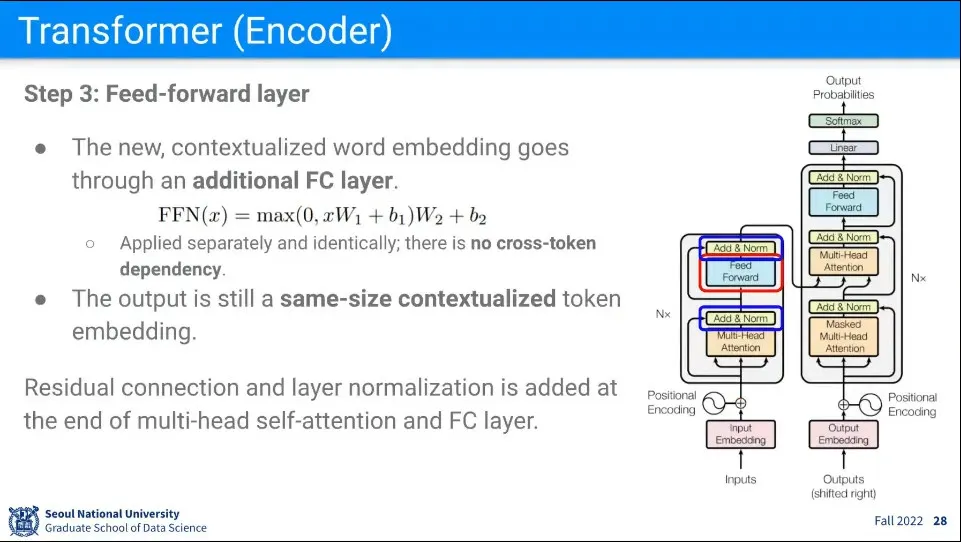
그렇게 만들어진 Z에 Fully-Connected 연산을 해준다.
◦
이때 fully-connected는 자기 자신에 대해서만 수행한다.
•
추가로 Fully-Connected를 하기 전(attention 수행 후)과 후에 Residual connection과 layer normalization(잔차 연결과 정규화)를 해준다.
•
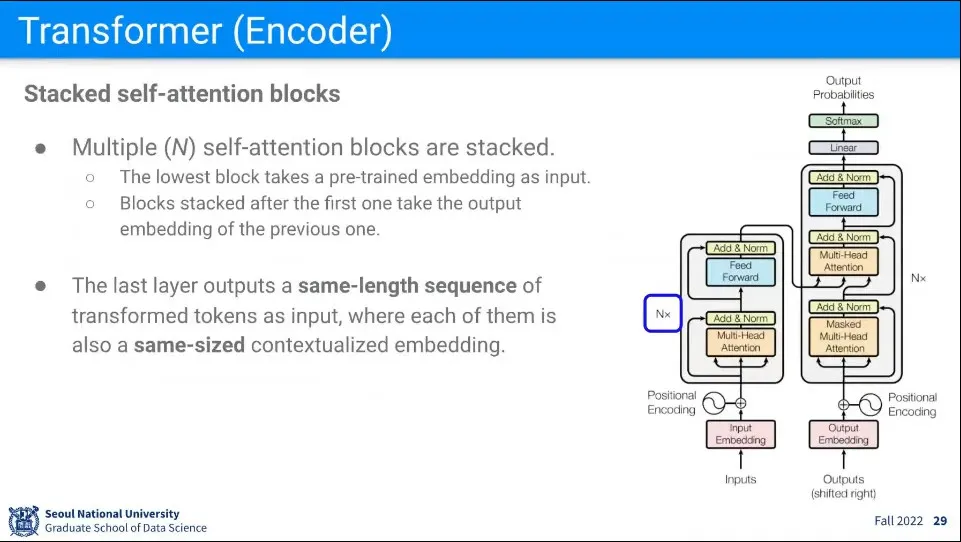
위와 같은 Self Attention과 Fully Connected를 N번 반복해 준다.
◦
반복할 때는 이전 단계의 output이 새로운 단계의 input으로 들어감
•
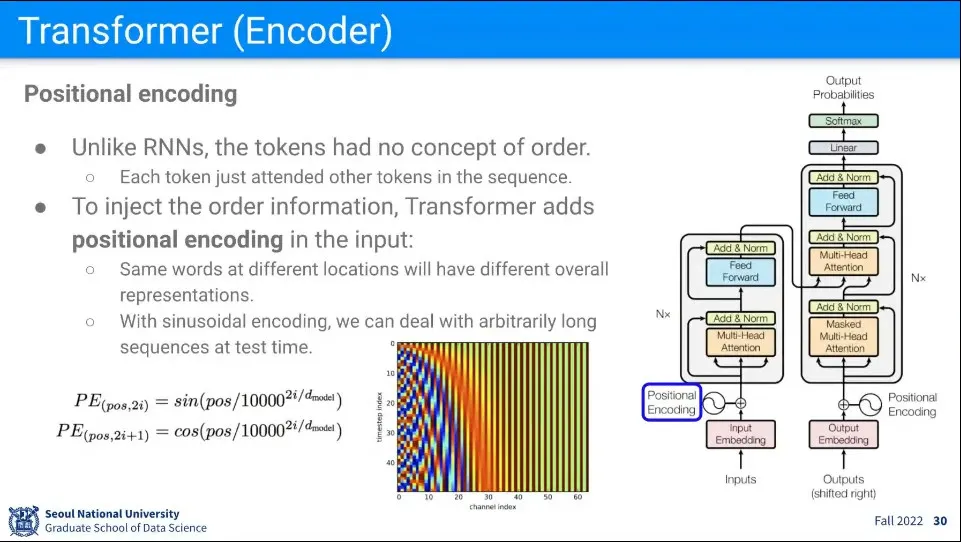
Encoding에 들어가기 앞서 Positional Encoding을 수행한다.
◦
단어가 차례로 들어가는 RNN과 달리 Transformer는 단어를 한 번에 넣고, 각 단어에 대해 다른 단어들과 유사도를 계산하는데, 이렇게 되면 단어의 순서 의미가 없어짐.
◦
여기에 단어 순서의 의미를 만들어 주기 위해 Positional Encoding을 더해 준다. —정말로 산술적으로 더해준다.
•
위치는 유니크하지만 인접한 위치에 있는 것은 값이 미세하게만 바꿔주기 위해 Sin, Cos 함수를 사용한다.
•
이렇게 계산된 값을 Input에 그냥 더해주면 그걸 알아서 잘 배워서 사용하게 됨
•
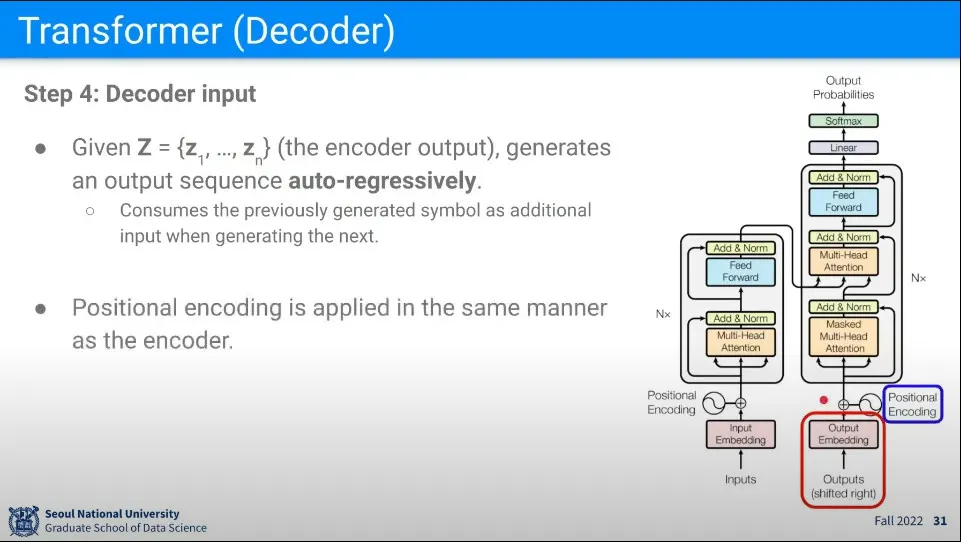
처음 Encoder의 Output Z를 입력으로 받고 단어를 하나씩(shifted right) auto-regressive —이전 output이 다음 input으로 활용— 하게 생성해낸다.
◦
이때 단어의 순서의 의미가 중요하므로 Encoder에서와 같이 Positional Encoding을 해준다.
◦
Decoder의 최초 state는 encoder를 갖고 있고, 다음 state는 이전 state를 포함하므로 —이전 state와 input을 결합하여 새로운 output 생성— Encoder는 유지가 된다.
◦
그래서 Encoder 정보를 Decoder의 중간에서 사용할 수 있는 것
•
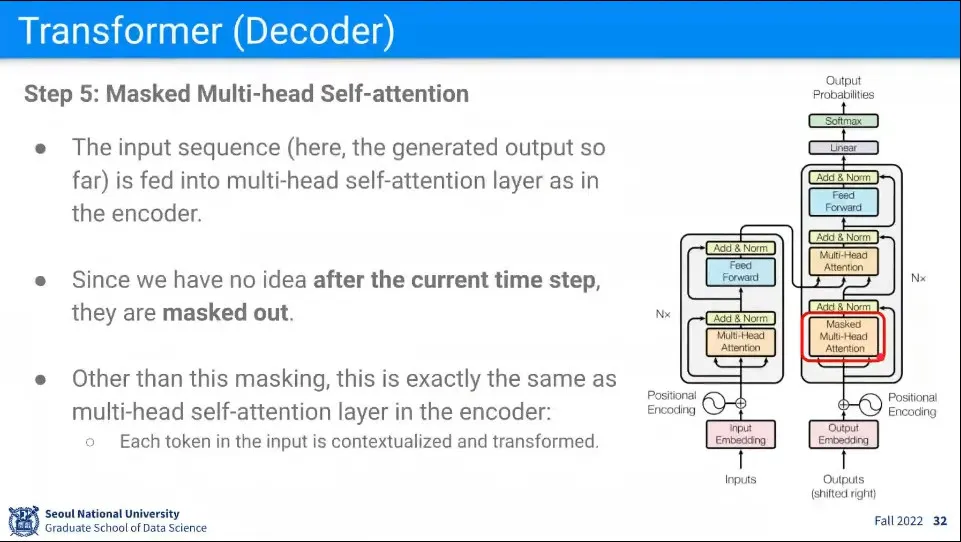
Decoder의 Input에 대해 Encoder와 마찬가지로 Multi Head Self Attention을 수행하는데, 이때 Masked Token을 넣어서 일부 데이터를 가린 채로 수행한다.
◦
현재까지 만들어진 Input 이외의 것은 안 쓰도록 Mask를 씌운다.
◦
Encoder에서 모든 문장을 한 번에 받아오기 때문에 —RNN과 달리— Decoder에도 모든 문장이 존재하는데, 이것은 순차적으로 문장을 만드는데 방해가 되기 때문에, 마치 RNN처럼 순차적으로 단어가 추가되어서 output을 만드는 것처럼 Input에 대해 Mask를 씌운다.
◦
현재까지 사용된 것들만 남기고 나머지를 Mask 씌우고, 현재까지 사용된 것들을 이용해서 Output을 만든다.
•
이렇게 만든 결과에 대해 Encoder에서와 같이 Add & Norm(잔차 연결과 정규화)을 수행해서 다음 단계로 넘어가게 한다.
•
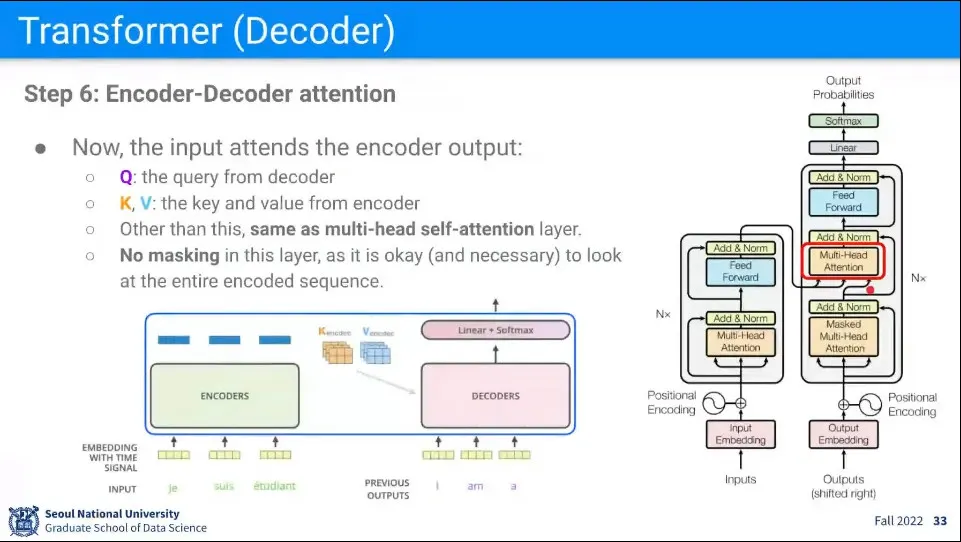
Decoder의 두 번째 단계에서는 첫 번째 Self Attention 했던 결과의 Q만 받아오고, K, V는 Encoder의 Input을 받아와서 Attention을 수행한다. —이거는 self attention이 아님
◦
Q는 내 현재 상태가 들어오고 K, V는 Original Input 이므로
◦
Original Input과 현재 상태를 Weighted Sum 해서 새로운 output을 생성한다는 개념
◦
예시에서 현재 I am a 까지 생성된 상태이고 이것을 오리지널 데이터의 프랑스어와 Weighted Sum을 하면 Student가 생성되게 된다.
•
encoder에 들어왔던 원래 문장이 뭐였는지를 봐야 하기 때문에 이 단계에서는 Mask 없이 수행한다.
•
그렇게 만들어진 결과는 다시 Add & Norm(잔차 연결과 정규화)을 수행해서 다음 단계로 넘어가게 한다.
•
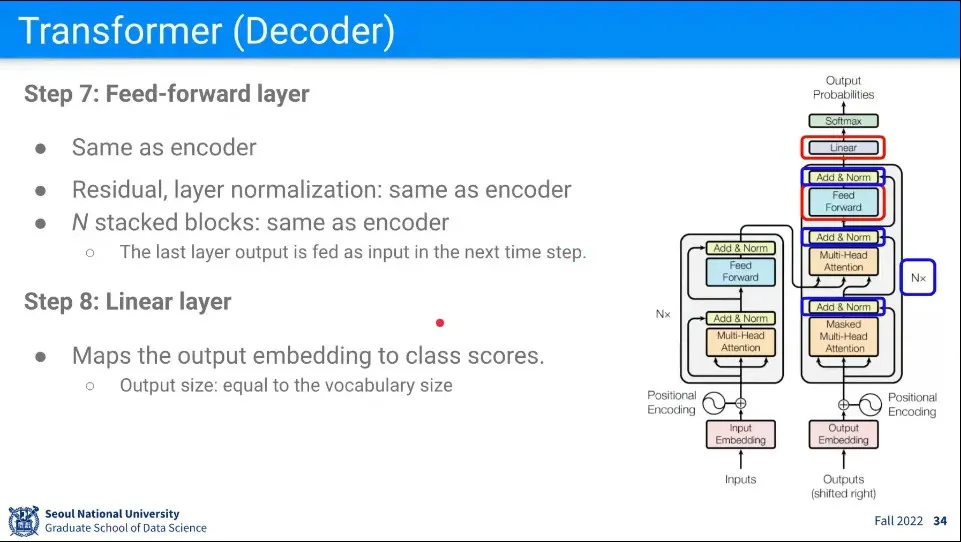
Encoder의 마지막과 마찬가지로 Feed Forward를 수행하고 그 결과를 Add & Norm하고 Decoder 전체를 N번 반복한다.
◦
여기서의 N은 Encoder의 N과는 다른 숫자이다.
•
반복이 끝난 결과는 Linear Layer를 통과시킨다.
•
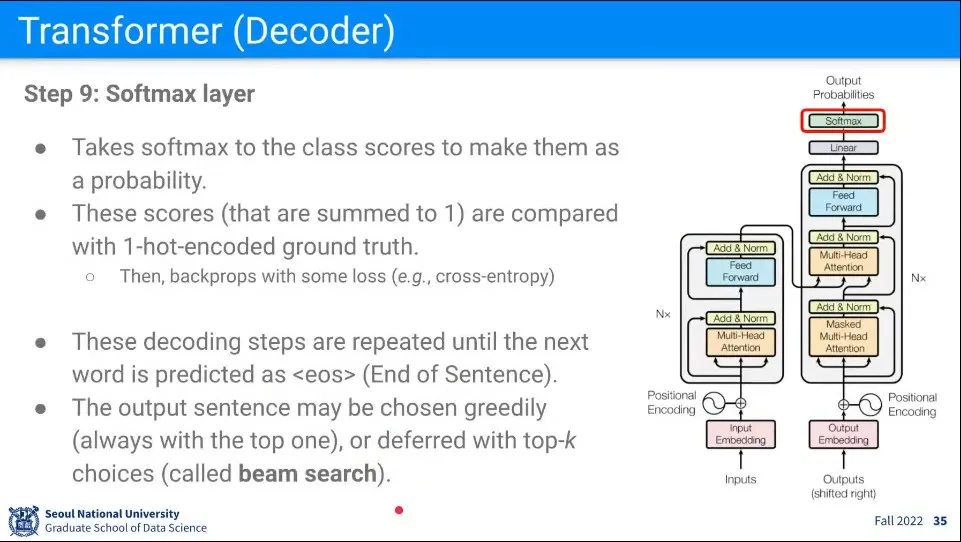
최종 결과는 Softmax를 통과시켜 얻는다.
•
그렇게 얻은 output은 다시 다음 input으로 넣어서 반복된다.

•
BERT는 트랜스포머의 encoder 부분을 이용한 언어 모델
◦
word embedding을 Transformer의 encoder 부분을 이용함
◦
사람이 개입하지 않고도 self-supervised가 됨
•
요즘 NLP는 BERT에서 나온 Word Embedding을 기본으로 사용함
•
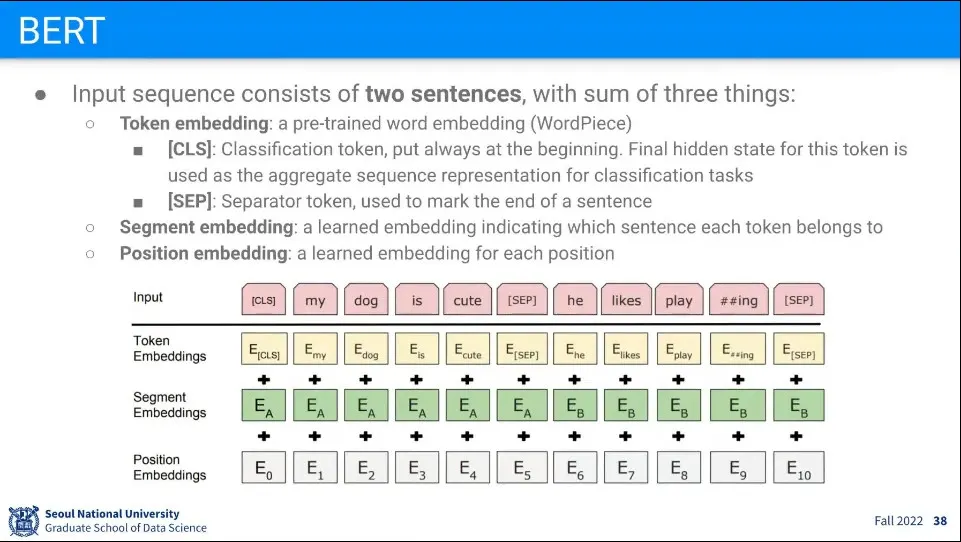
BERT는 2개의 문장을 넣는게 특징
◦
문장이 연결되는 위치에 [SEP] 토큰을 넣는다.
◦
맨 앞에는 [CLS] (classifier) 토큰을 넣는다.
•
Input으로 3개의 Embedding —Token Embedding, Segment Embedding, Position Embedding— 을 만들고 이것들을 합해서 넣음
◦
Token Embbeding은 Word Piece라는 pre-trained 모델을 사용함
◦
Segment Embedding은 현재 단어가 두 문장 중 어느 문장에 위치한 것인지를 표현
◦
Position Embedding은 현재 단어의 순서를 표현

•
BERT를 이용하면 전체 문장에 빈칸을 생성하고 그 위치에 어떤 단어가 들어갈지를 맞추는 것을 학습 할 수 있다.
◦
이 방법을 Masked Language Modeling(MLM)이라고 한다.
◦
이렇게 하면 사람이 라벨링 할 필요 없이 데이터만으로 학습이 가능하다. —빈칸은 랜덤으로 생성

•
BERT는 문장을 2개씩 넣었기 때문에 다음 문장 예측을 학습 할 수 있다.
◦
Input으로 넣을 때 넣었던 [CLS] 토큰을 이용해서 두 문장이 연속된 것인이 아닌지를 배운다.
•
그러나 이것은 이후에 빈칸 채우기에 비하면 덜 중요하다는 것이 밝혀짐
•
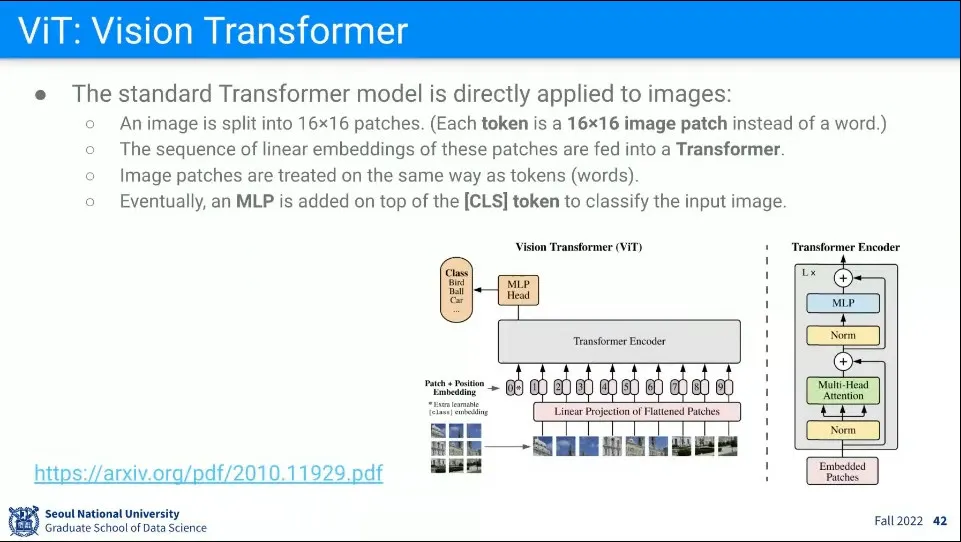
Transformer를 Vision에 사용한 예
◦
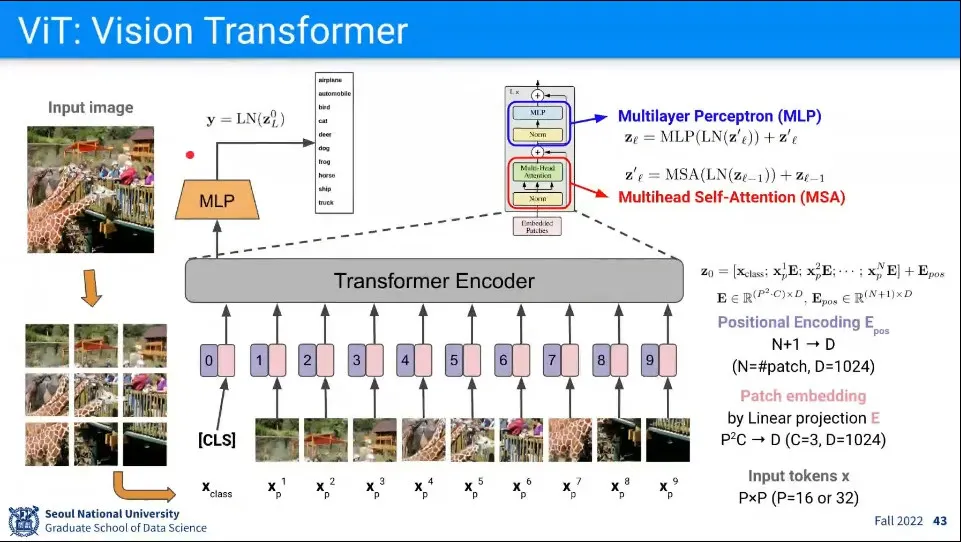
16x16 패치를 문장에서 단어처럼 생각해서 트랜스포머를 적용함
•
이미지를 16x16 패치로 쪼깨고, 시퀀스를 구성한 후에 트랜스포머처럼 학습 시킴
◦
구조가 나와 있지만 트랜스포머랑 완전히 같지는 않음
•
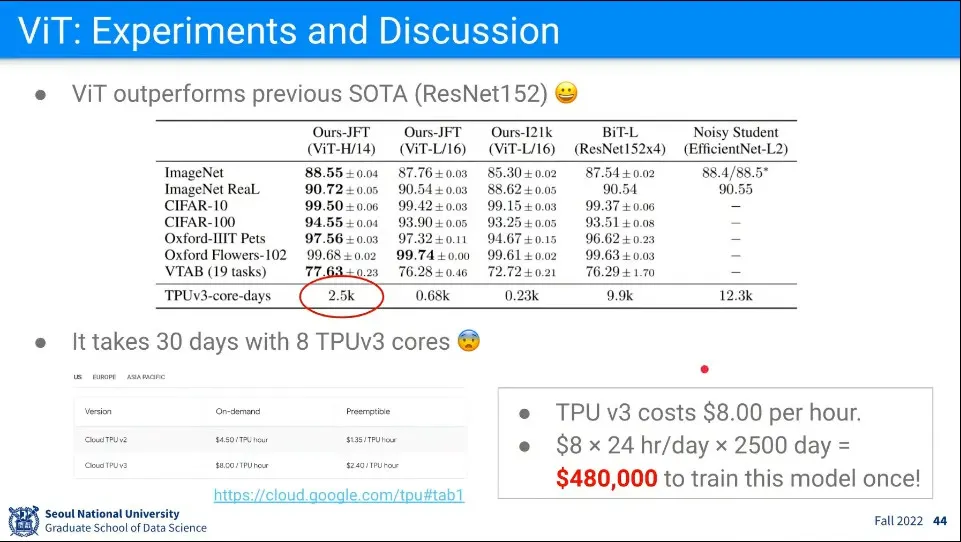
기존 Vision 모델에 비해 성능은 좋았지만, 학습 비용이 매우 비쌈
◦
표 보면 사실 성능 차이도 압도적이지 않음. 살짝 높음
•
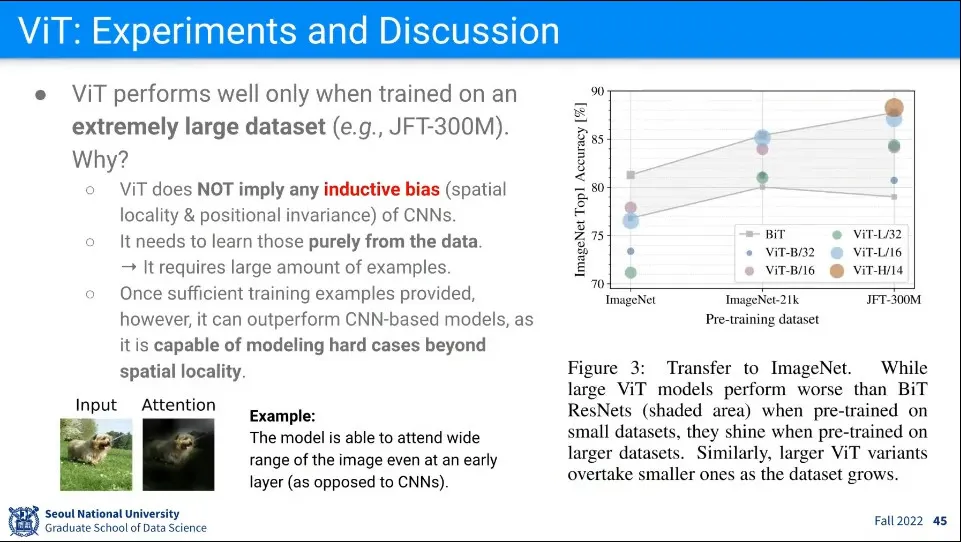
ViT는 주변 정보만 활용하는 기존 CNN과 달리 이미지 전체를 보고, 그 이미지 내에서 Attention 해야 하는 부분을 찾아냄.
•
이걸 이용하면 멀리 있는 거를 봐야 하는 경우 잘 함.
◦
CNN은 가까이 있는 거만 봐야 해서 못하는 것을 했다는 것.
•
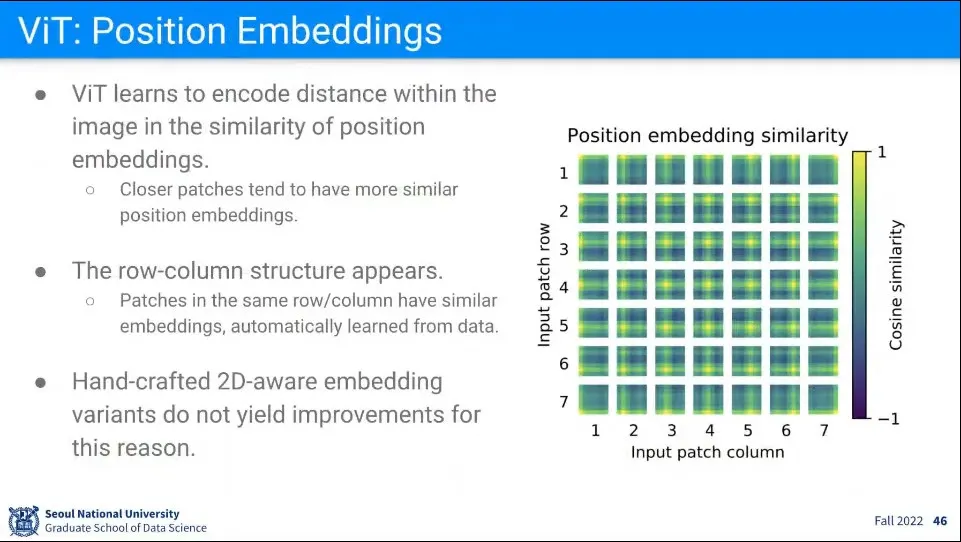
트랜스포머에서 Positional Encoding은 그냥 sin, cos 식을 넣어서 했는데, ViT에서는 Positional Encoding을 직접 학습하도록 했음.
