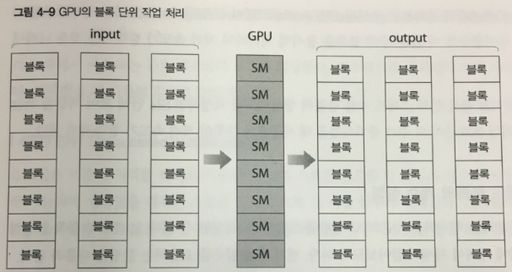
아래의 참조 자료(https://karl6885.github.io/cuda/2018/11/08/NVIDIA-CUDA-tutorial-1/)에 기본적인 튜토리얼이 모두 나와 있으니 아래 자료 참조
아래 내용은 필자가 공부하고 테스트하면서 알게 된 내용을 keyword 중심으로 정리한 내용이라 다소 맥락이 없게 느껴질 수 있다. 향후 더 공부하고 실제 프로그래밍하면서 더 업데이트될 수 있음
Kernel
CUDA는 C++ 프로젝트와는 독립적으로 돌아가는 코드이며, C++과는 사전에 협의된 —인터페이스된— 방법을 통해 명령과 데이터를 주고 받는다고 이해하면 된다. —CUDA는 C라고 이해하면 쉽다.
그러나 코드 자체는 C++ 프로젝트 내에 작성되기 때문에 일반적인 C++ 코드와 구별해 줄 필요가 있는데, __global__ 이라는 키워드가 그러한 역할을 해준다. 이렇게 __global__ 키워드가 붙은 함수를 일반적으로 커널(kernel)이라 부른다.
// __global__ 키워드가 붙은 함수는 C++ 컴파일러가 아니라 NVIDIA CUDA Compiler가 컴파일한다.
__global__ void CudaHello()
{
printf("Hello CUDA");
}
// __global__ 키워드가 없는 함수는 C++ 컴파일러가 컴파일한다.
int main()
{
CudaHello<<<1, 1>>>()
}
C++
복사
C++ 코드에서 CUDA 함수를 호출할 때는 그냥 함수명만 쓰는게 아니라 <<<(blockSize), (threadSize)>>> 을 통해 호출한 함수를 몇 개의 block과 block당 몇 개의 thread로 병렬 처리할 것인지를 알려주어야 한다.
위 코드는 1개의 block에 1개의 thread만 사용한다고 알려줬기 때문에 결과는 다음과 같다.
Hello CUDA
C++
복사
만일 blockSize와 threadSize를 2, 3로 지정했다면, 다음과 같이 총 6(=2x3)개가 출력될 것이다.
Hello CUDA
Hello CUDA
Hello CUDA
Hello CUDA
Hello CUDA
Hello CUDA
C++
복사
Thread Hierarchy
앞선 예제와 같이 동일한 작업을 병렬로 수행하기 위해 CUDA를 쓰는 경우는 없을 것이고, 실제 CUDA를 사용하는 것은 로직은 동일하지만 Input이 다르고 그에 따라 Output이 다른 작업을 병렬로 수행해서 빠르게 결과를 얻기 위함일 것이다.
예컨대 0-9999까지의 값을 갖고 있는 10,000개의 배열이 있고, 해당 배열 원소들의 값을 모두 2배씩 증가시키는 로직을 짠다고 가정하자. 이것을 CPU를 통해 로직을 짜면 아래와 같이 10,000번의 반복을 수행하는 코드가 필요하다 —물론 parallel을 쓸 수도 있지만 일단 논외
for (int i = 0; i < a.length; i++)
{
a[i] *= 2;
}
C++
복사
CUDA를 사용하면 이 10,000개의 배열에 대해 단 1번에 연산을 마칠할 수 있는데, 이는 각 연산을 10,000개의 Thread에 나눠서 처리할 수 있기 때문이다.
// 10,000개의 Thread가 아래의 연산을 수행하면 결과를 1번에 얻을 수 있다.
a[index?] *= 2;
C++
복사
그런데 이것이 가능하려면 10,000개의 Thread에 대해 배열의 각 index를 부여할 수 있어야 한다. 만일 위의 코드에서 배열의 index 자리에 0과 같은 특정한 상수를 넣는다면 10,000개의 Thread가 모두 배열의 0번 값만 바꿀 것이기 때문이다.
이와 같이 배열의 Index를 부여하기 위해 CUDA는 4가지 형태의 값을 제공하는데 그것이 바로 gridDim, blockIdx, blockDim, threadIdx이다.
•
gridDim - grid 내에 있는 block의 개수
•
blockIdx - block의 Index
•
blockDim - block 내에 있는 thread의 개수
•
threadIdx - thread의 index
쉽게 요약해서 thread는 실제 작업 단위를 의미하며, block은 그러한 thread들의 모임을 의미하고, grid는 다시 그러한 block들의 모임을 말한다. thread → block → grid로 이어지는 이 구조를 'Thread Hierarchy'라고 한다.
block의 index는 고유하고, thread도 자신이 속한 block 내에서는 고유하기 때문에 배열에 접근하기 위한 Index는 다음과 같이 계산한다.
// blockDim은 block에 속한 thread의 개수이다. 이름 때문에 헷갈리지 말 것.
// 각 index와 dimension은 x, y, z 값을 가질 수 있는데 일단 무시한다. 이후에 설명
int index = blockIdx.x * blockDim.x + threadIdx.x;
a[index] *= 2;
// block이 개당 512개의 thread를 갖고 있고, block이 총 20개 있다고 가정할 때,
// 10번째 block의 20번째 thread의 index는 다음과 같다.
// 10 x 512 + 20 = 5140
C++
복사
그런데 위와 같이 코드를 작성하면 문제가 된다. block이 20개이고, block당 thread가 512개이므로, 총 생성되는 thread는 10,240개가 되는데, 배열의 총 길이는 10,000개이기 때문이다. 배열보다 index가 큰 240개의 thread는 배열에 없는 index를 참조할 것이고 프로그램은 에러를 발생시킬 것이다.
이와 같은 경우를 방지하기 위해 배열의 길이를 나타내는 값을 파라미터로 전달하고 그 값을 넘지 않을 때만 연산을 수행하는 식으로 코드를 작성하면 된다.
__global__ void Multiply(int* a, int N)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < N)
{
a[index] *= 2;
}
}
C++
복사
Grid-Stride Loops
앞선 코드는 데이터보다 thread의 수가 더 많은 예시를 들었는데, 그 반대의 경우도 있을 수 있다. thread보다 데이터가 많은 경우에는 다음과 같이 총 쓰레드 개수를 반복문에 더해주는 방법으로 처리할 수 있는데, 이를 grid-stride loops라고 한다.
// 데이터는 10000개인데, blockSize = 10, thread = 512로 thread가 총 5120인 경우
__global__ void Multiply(int* a, int N)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = gridDim.x * blockDim.x; // gridDim은 block의 전체 개수, blockDim은 thread의 전체 개수
// stride는 thread 전체의 개수로 N 보다 작다.
if (int i = index; i < N; i += stride)
{
a[i] *= 2;
}
}
C++
복사
DeviceQuery
잠시 다른 이야기로 새서, 위에 설명한 Thread와 Block은 CUDA 프로그래밍을 하는 프로그래머가 임의로 지정할 수 있는데, 물론 그 갯수에는 한계가 있다. 그 한계는 현재 사용자의 컴퓨터에 설치된 그래픽카드의 사양에 따라 다르다.
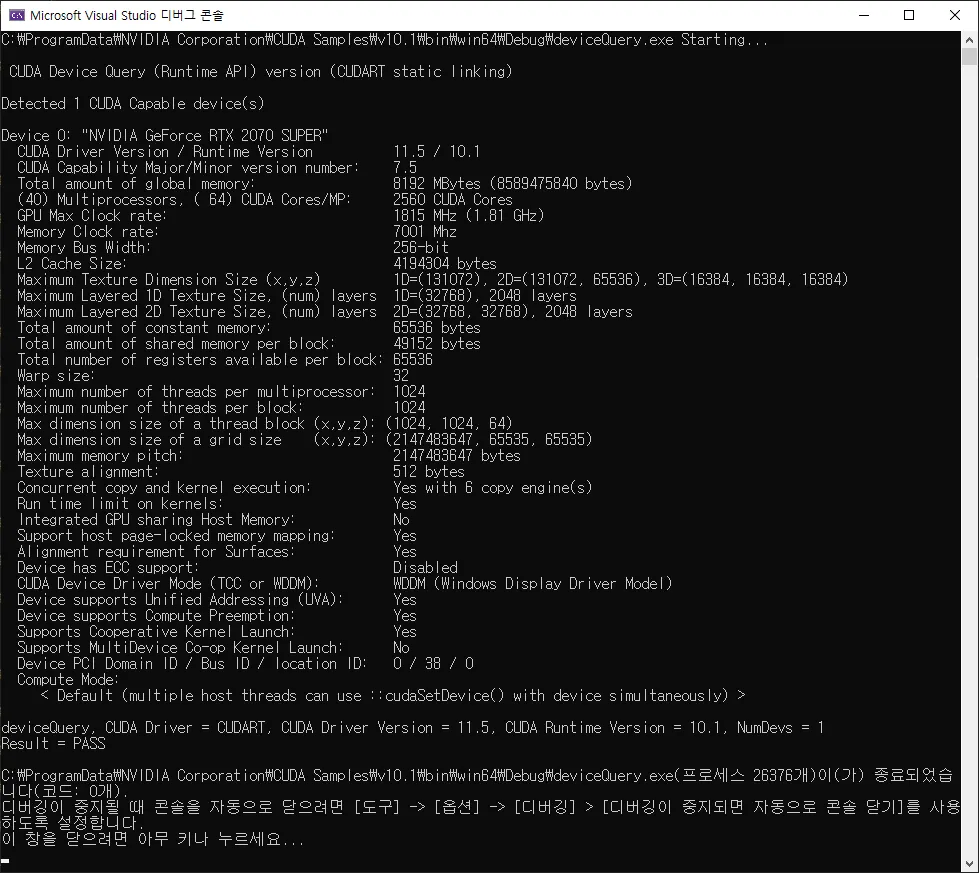
이 사양은 DeviceQuery라는 것을 통해 확인할 수 있는데, DeviceQuery를 실행 할 수 있는 경로는 CUDA가 설치된 위치를 통해 찾을 수 있다.
나는 'C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.1\1_Utilities\deviceQuery' 경로에 DeviceQuery를 실행할 수 있는 프로젝트가 있어서 해당 프로젝트를 실행하여 아래와 같이 사양을 확인할 수 있었다. —만일 그 위치에 exe 파일이 있으면 그것을 실행해서 바로 확인 가능하다.
RTS 2070 Super 기준 Block당 Thread는 1024개까지 가능하며, 3차원 기준 Grid에 대해 Block은 x - 1024, y - 1024, z - 64 개까지 가능하다.
cudaMalloc, cudaMemcpy, cudaFree
앞선 코드에서 변수를 kernel에 넘겼는데, 이것을 C++에서 하던 대로는 할 수 없다. 일반적인 기본타입 변수 —int, bool 등— 는 별다른 처리를 하지 않고도 kernel에 넘길 수 있지만, 배열 같은 데이터는 CUDA에서 처리할 수 있도록 데이터를 처리해줘야 하는데, 이 단계에서 사용하는 것이 cudaMalloc과 cudaMemcpy이다. —malloc이라는 이름만 봐도 CUDA가 C언어에 기반하고 있다는 것을 알 수 있다.
CUDA에서는 CPU에서 처리되는 것을 Host라고 하고, GPU에서 처리되는 것을 Device라고 하는데, Host에 존재하는 데이터를 Device로 복사해 줘야 CUDA가 데이터를 처리할 수 있다.
__global__ void Multiply(int* a, int N)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < N)
{
a[index] *= 2;
}
}
int main()
{
// cpu에서 사용하는 데이터 선언
int N = 10000;
int* host = new int[N];
for (int i = 0; i < N; i++)
{
host[i] = i;
}
// gpu에서 사용할 수 있도록 cpu와 동일한 변수 생성
size_t size = N * sizeof(int);
int* device;
cudaMalloc(&device, size);
// cpu의 데이터를 gpu에 복사
cudaMemcpy(device, host, size, cudaMemcpyHostToDevice);
// CUDA 실행
Multiply<<<20, 512>>>(device, N);
// 결과 값 사용하는 부분
// ...
// gpu에서 사용한 변수를 해제
cudaFree(device);
}
C++
복사
기본적인 흐름은 위 코드와 같다. GPU에서 사용할 수 있는 변수를 만들고, cudaMalloc를 수행하면, 해당 변수를 GPU에서 사용할 수 있게 된다. 그 후에 cudaMemcpy를 통해 값을 복사하고, 최종적으로 GPU에서 사용한 변수를 cudaFree를 통해 해제한다. —cudaMemcpyHostToDevice 부분을 보면 알 수 있지만 cudaMemcpyDeviceToHost도 존재한다. GPU의 결과값을 CPU로 가져오는 것도 가능하다는 것
위 코드에서 보면 알겠지만 배열이 아닌 int 형 데이터인 N은 cudaMalloc 같은 것을 하지 않고도 GPU에서 바로 사용할 수 있다.
Error Handling
CUDA를 수행하다가 에러가 난 경우 다음과 같은 inline 함수로 에러를 처리할 수 있다.
inline cudaError_t checkCuda(cudaError_t result)
{
if (result != cudaSuccess)
{
fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
return result;
}
C++
복사
이러한 inline 함수는 cuda 관련 함수에 감싸서 에러를 관리한다. 아래 코드 참조
inline cudaError_t checkCuda(cudaError_t result)
{
if (result != cudaSuccess)
{
fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
return result;
}
__global__ void Multiply(int* a, int N)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < N)
{
a[index] *= 2;
}
}
int main()
{
// cpu에서 사용하는 데이터 선언
int N = 10000;
int* host = new int[N];
for (int i = 0; i < N; i++)
{
host[i] = i;
}
// gpu에서 사용할 수 있도록 cpu와 동일한 변수 생성
size_t size = N * sizeof(int);
int* device;
checkCuda(cudaMalloc(&device, size));
// cpu의 데이터를 gpu에 복사
checkCuda(cudaMemcpy(device, host, size, cudaMemcpyHostToDevice));
// CUDA 실행
Multiply<<<20, 512>>>(device, N);
// 결과 값 사용하는 부분
// ...
// gpu에서 사용한 변수를 해제
checkCuda(cudaFree(device));
}
C++
복사
구조체 매개변수 전달
위의 예시는 일반 타입의 배열을 사용했지만, 실제 코드를 사용하면 좀 더 복잡한 데이터를 처리해야 하는 경우가 있다. 물론 처리해야 할 타입을 모두 배열로 선언하여 CUDA에서 처리할 수도 있겠지만, 만일 C++상에서 어떤 클래스나 구조체 형태로 되어 있던 데이터를 처리해야 한다면, '클래스 → 입력 배열 → CUDA → 결과 배열 → 클래스' 와 같이 중간에 변환 단계를 거쳐야 하기 때문에 성능상 불리할 수 있다.
실제 필자가 사용할 때 위와 같은 변환 단계를 거치면 그냥 C++에서 parallel로 돌리는 것에 비해 CUDA로 돌리는 것이 성능상 이점이 없는 경우도 있었다. 애초에 CUDA에 C++에서 사용하는 구조체나 클래스 데이터를 넘기고, 그 결과를 C++에서 사용하는 형태로 받아올 수 있다면 성능상 매우 유리할 것이다.
CUDA는 C언어이기 때문에 C++에서 사용하는 클래스를 그대로 넘기기는 어렵지만, default 생성자만 존재하고, CUDA 내에서 메서드가 아닌 접근 가능한 경로를 만들어주면 충분히 사용 가능하다. 아래 코드는 필자가 실제 사용한 코드의 일부분이다.
class PointCuda final : public IPoint<int>
{
public:
PointCuda() = default;
// C++에서도 사용 가능하게 클래스 메서드를 만든다.
int GetIndex() const override { return this->index; }
int GetX() const override { return this->x; }
int GetY() const override { return this->y; }
unsigned char GetBlue() const override { return this->blue; }
unsigned char GetGreen() const override { return this->green; }
unsigned char GetRed() const override { return this->red; }
int index, x, y;
unsigned char blue, green, red;
}
C++
복사
위 클래스는 파라미터를 전달 받는 생성자가 없으며, CUDA에서 접근 가능하도록 멤버 변수를 public으로 선언하였다. —개인적으로는 멤버 변수는 오로지 생성자에서만 set 가능하게 하는 것을 선호하지만
이렇게 선언한 클래스는 아래와 같이 사용할 수 있다.
__global__ void DetectPoint(unsigned char* source, PointCuda* result, int N)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < N)
{
// source를 갖고 연산을 수행
// 연산 결과를 구조체에 대입
result[index].index = index;
result[index].x = 0;
result[index].y = 0;
result[index].blue = 0;
result[index].green = 0;
result[index].red = 0;
}
}
int main()
{
// sourceHost, resultHost를 가져오는 부분 생략
// ...
// sourceHost를 GPU에서 사용할 수 있게 sourceDevice에 복사한다.
size_t sourceSize = N * sizeof(unsigned char);
int* sourceDevice;
checkCuda(cudaMalloc(&sourceDevice, sourceSize));
checkCuda(cudaMemcpy(sourceDevice, sourceHost, sourceSize, cudaMemcpyHostToDevice));
// 결과를 받을 result 선언
size_t resultSize = N * sizeof(PointCuda);
PointCuda* resultDevice;
checkCuda(cudaMalloc(&resultDevice, resultSize));
// 결과를 받아올 것이기 때문에 cudaMemcpy는 하지 않는다.
// thread의 총 개수가 N보다 크게 만든다.
size_t threadSize = 512;
size_t blockSize = (N + threadSize - 1) / threadSize;
// CUDA 실행
DetectPoint<<<blockSize, threadSize>>>(sourceDevice, resultDevice, N);
// 에러 체크
checkCuda(cudaGetLastError());
// device에 담아온 결과를 CPU에서 사용 가능하게 resultHost에 담는다.
checkCuda(cudaMemcpy(resultHost, resultDevice, resultSize, cudaMemcpyDeviceToHost))
// GPU에서 사용한 sourceDevice, resultDevice는 해제한다.
checkCuda(cudaFree(sourceDevice));
checkCuda(cudaFree(resultDevice));
// resultHost를 사용하거나 반환한다.
}
C++
복사
2차원 Block, Thread
경우에 따라 2차원으로 다루는게 더 직관적인 경우가 있다. 예컨대 이미지의 데이터를 다룬다면, x, y 좌표가 있는 것이 오히려 로직을 짜는데 더 직관적으로 느껴질 수 있다. 이런 경우 block과 thread를 2차원으로 처리하여 로직을 구성할 수 있다.
thread를 2차원으로 구성할 때는 CUDA 함수를 실행 할 때 dim3 타입의 변수를 넘겨주면 된다. —3차원으로 넣는데, z는 1로 넣는다
2차원으로 구성할 경우 thread는 한 차원에 16개까지만 가능하므로 주의 —2차원이므로 x 방향으로 16개, y 방향으로 16개면 총 256개의 thread가 한 block에 속하게 된다.
아래 코드는 위의 point 예제를 2차원으로 재구성한 것이다.
__global__ void DetectPoint(unsigned char* source, PointCuda* result, int columnCount, int rowCount, int N)
{
// block과 thread의 x, y를 이용해서 x, y 위치 값을 찾는다.
int posX = blockIdx.x * blockDim.x + threadIdx.x;
int posY = blockIdx.y * blockDim.y + threadIdx.y;
// x, y 를 넘어서면 처리하지 않는다.
if (posY < rowCount && posX < columnCount)
{
// source를 갖고 연산을 수행
// 연산 결과를 구조체에 대입
result[index].index = posY * columnCount + posX;
result[index].x = posX;
result[index].y = poxY;
result[index].blue = 0;
result[index].green = 0;
result[index].red = 0;
}
}
int main()
{
// sourceHost, resultHost, columnCount, rowCount를 가져오는 부분 생략
// ...
// sourceHost를 GPU에서 사용할 수 있게 sourceDevice에 복사한다.
size_t sourceSize = N * sizeof(unsigned char);
int* sourceDevice;
checkCuda(cudaMalloc(&sourceDevice, sourceSize));
checkCuda(cudaMemcpy(sourceDevice, sourceHost, sourceSize, cudaMemcpyHostToDevice));
// 결과를 받을 result 선언
size_t resultSize = N * sizeof(PointCuda);
PointCuda* resultDevice;
checkCuda(cudaMalloc(&resultDevice, resultSize));
// 결과를 받아올 것이기 때문에 cudaMemcpy는 하지 않는다.
int size = 16
// dim3 타입으로 선언하고 x, y에 size(16)을 넣고 z에는 1을 넣는다.
dim3 threadSize(size, size, 1);
// block의 x축은 columnCount를 기준으로 잡고, y축은 rowCount를 기준으로 잡는다. z는 1
dim3 blockSize((columnCount / threadSize.x) + 1, (rowCount / threadSize.y) + 1, 1);
// CUDA 실행
DetectPoint<<<blockSize, threadSize>>>(sourceDevice, resultDevice, columnCount, rowCount, N);
// 에러 체크
checkCuda(cudaGetLastError());
// device에 담아온 결과를 CPU에서 사용 가능하게 resultHost에 담는다.
checkCuda(cudaMemcpy(resultHost, resultDevice, resultSize, cudaMemcpyDeviceToHost))
// GPU에서 사용한 sourceDevice, resultDevice는 해제한다.
checkCuda(cudaFree(sourceDevice));
checkCuda(cudaFree(resultDevice));
// resultHost를 사용하거나 반환한다.
}
C++
복사