
•
Multimodal은 통계학에서 유래한 것으로 딥러닝에서는 데이터 형식이 여러 개인 것을 뜻함.
◦
Audio는 모든 소리를 뜻하고, Speech는 언어를 뜻함.

•
멀티모달의 활용 예
◦
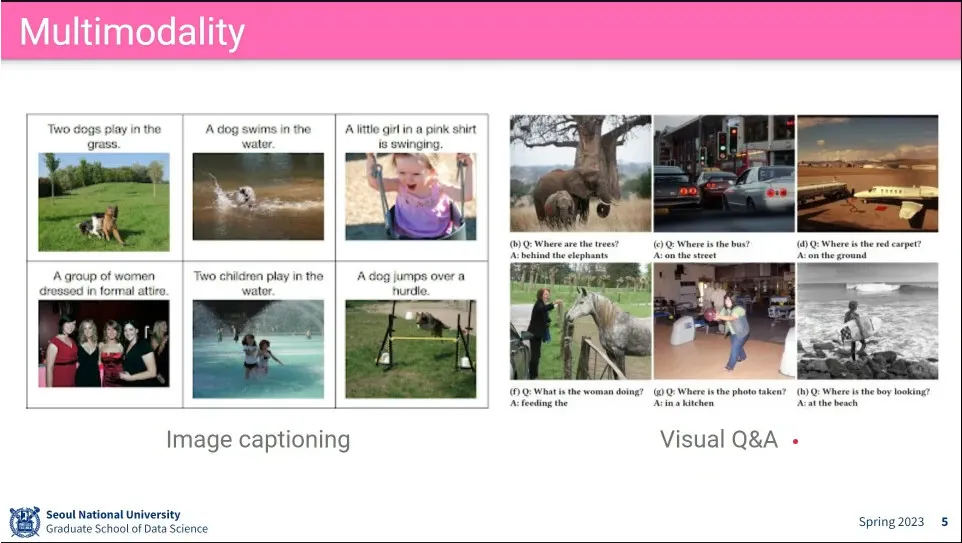
이미지/비디오 검색, 이미지/비디오 캡셔닝, VQA 등
•
예

•
Image나 video가 주어졌을 때 caption을 다는 task
◦
image와 caption을 주고 학습 시킴

•
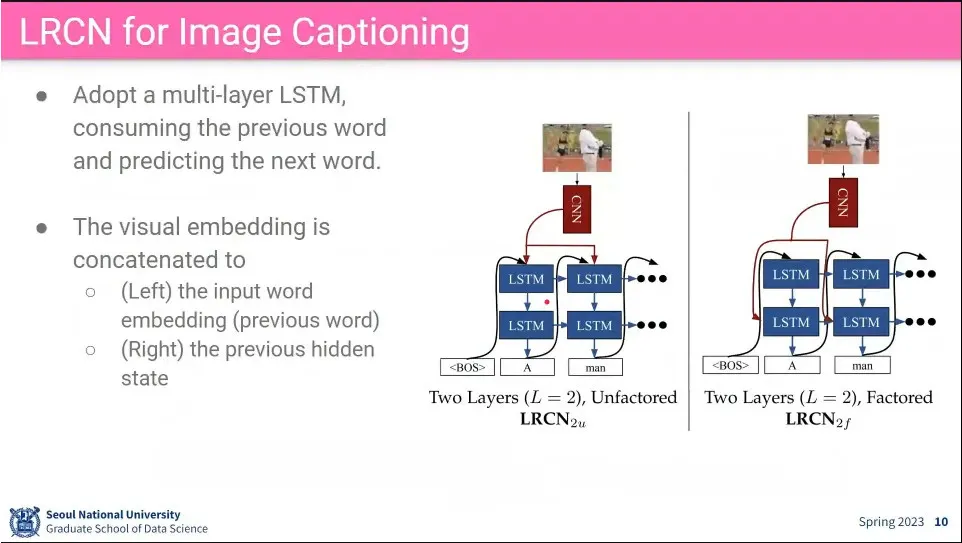
LRCN이 Image/Video Captioning에 잘 동작 함
•
LSTM의 input과 hidden state에 CNN feature를 추가해 주는 2가지를 테스트 해 봄.
◦
어느 정도 잘 된다.


•
NCE를 이용한 모델도 있음.
◦
input이 multi modal이기 때문에 image와 caption 2개를 이용해서 분포를 만듦.
◦
가짜 분포도 2쌍을 만들어주는데, 이때 아무렇게나 주면 너무 쉬우므로, image는 진짜 이미지를 쓰고, caption은 해당 이미지의 caption이 아닌 문장을 줌.

•
captioning을 위한 loss 함수
◦
기존과 동일하지만 image와 caption의 관계를 배우도록 loss를

•
예

•
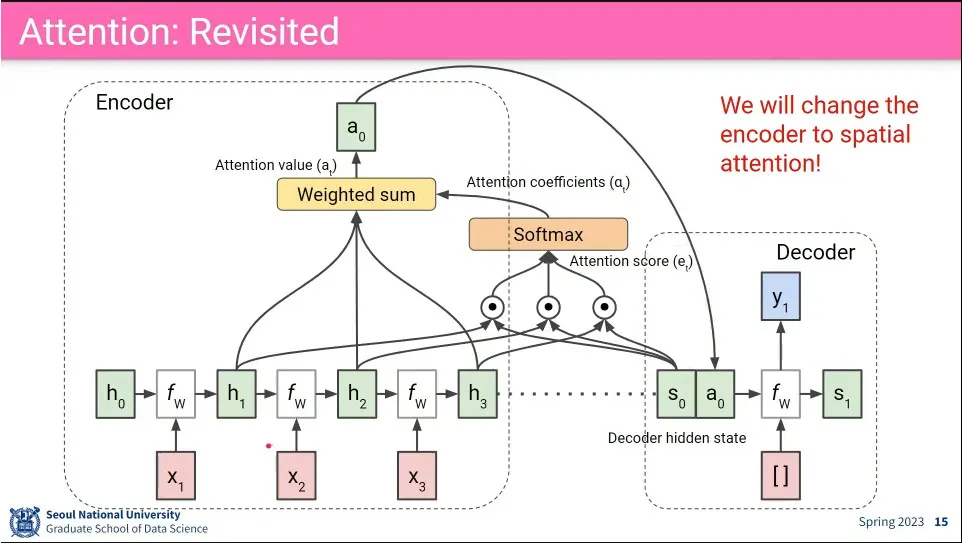
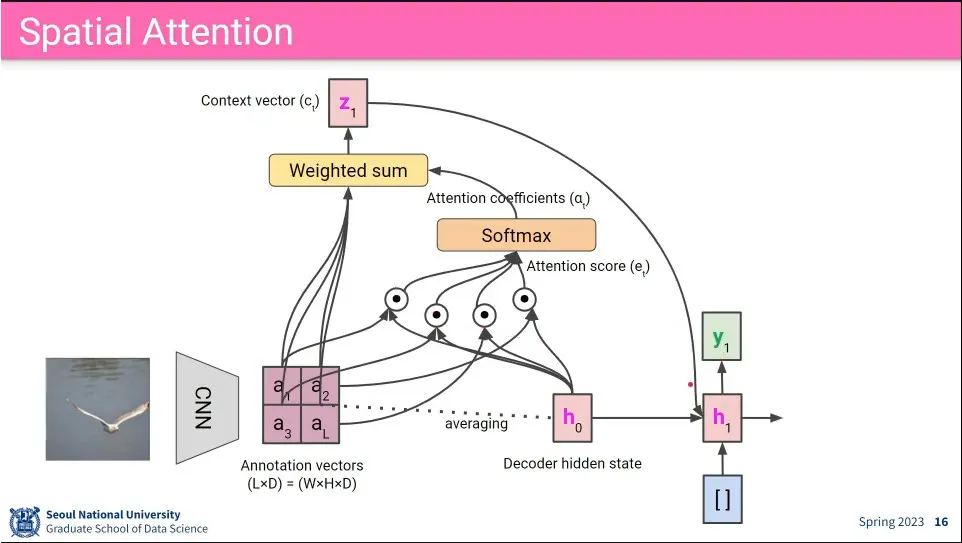
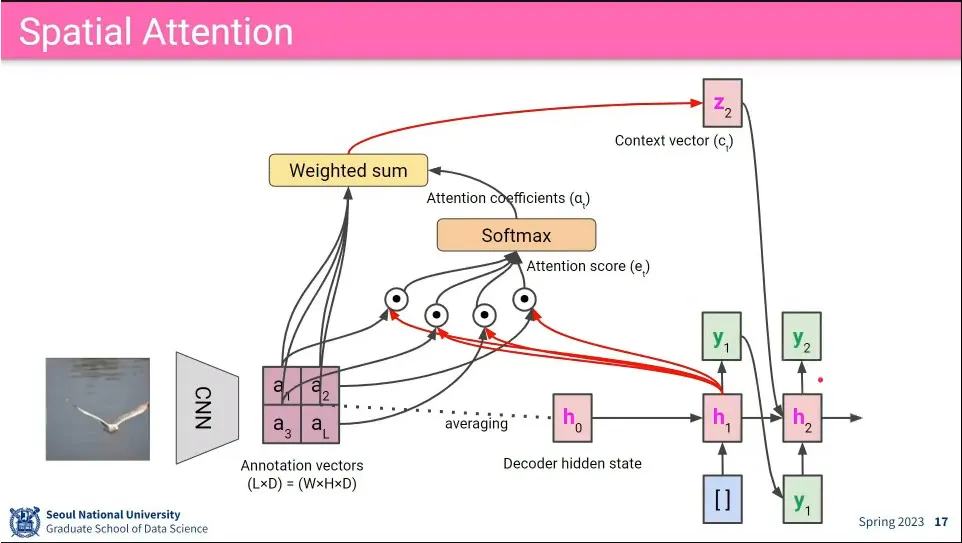
이미지에 대해 공간적인(spatial) 정보에 대해 LSTM으로 attention 함. 그래서 어느 공간적인 정보에 attention 해야 할지를 바탕으로 caption을 생성 함.
•
attention 과정
•
LSTM으로 spatial 정보를 attention 해서 hidden state를 업데이트하는 과정

•
Q, K, V

•
Spatial Attention의 분포 수식
•
예
◦
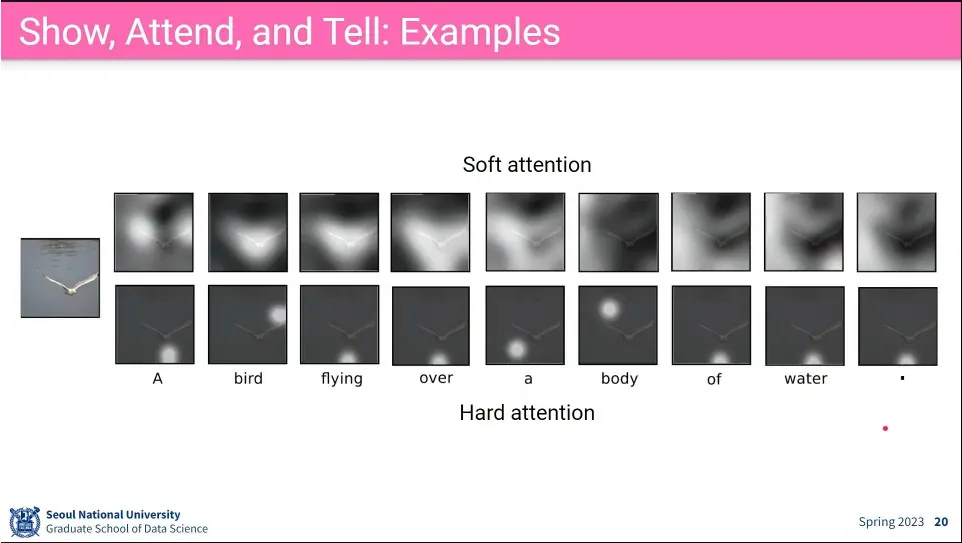
이미지의 특정 부분을 보고 caption을 생성 함.

•
예제 - 잘 된 것들
◦
각 단어에 대해 어느 부분에 attention 하고 있는지를 보여 줌.

•
예제 - 잘 안 된 것들

•
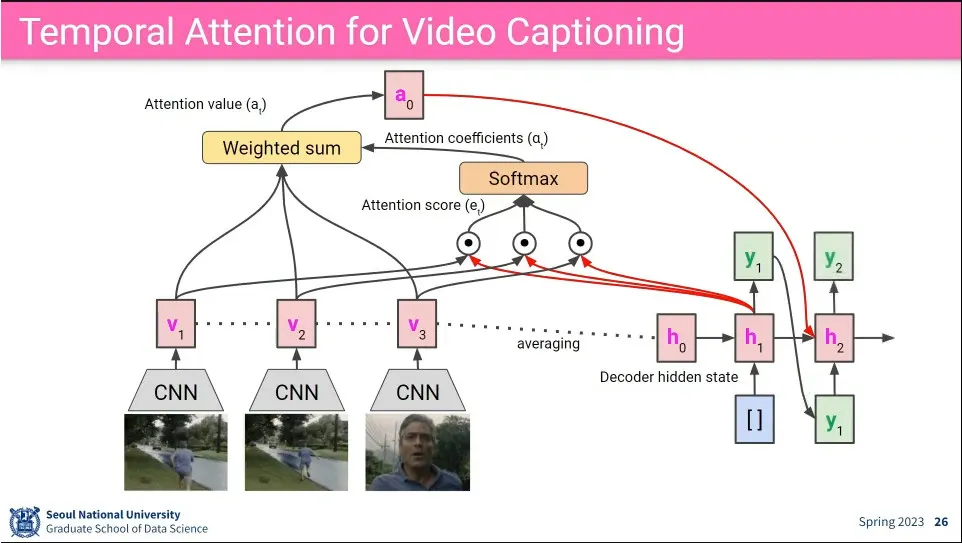
Video captioning을 할 때는 시간(temporal) 정보가 추가 됨.
•
처음 각 frame에 대해 CNN을 돌려서 그걸로 첫 번째 hidden state를 만들고 attention 단계를 진행
◦
흐름은 이전과 동일
•
transformer에서는 key, value에 대해 를 따로 만들어서 쓰는데, 다른 경우에는 대부분은 그냥 같은 것을 쓴다고 함.

•
Q, K, V

•
Tansformer에 image-text를 어떻게 사용할 수 있을까?
•
image, text pair는 어떻게 수집할 수 있을까?
◦
다소 noise가 있더라도 그냥 검색 결과와 클릭 이미지 pair를 쓰거나, 웹에서 image에 text를 단 것을 쓰거나 등. 이런 데이터에는 noise가 많이 끼어 있음.
•
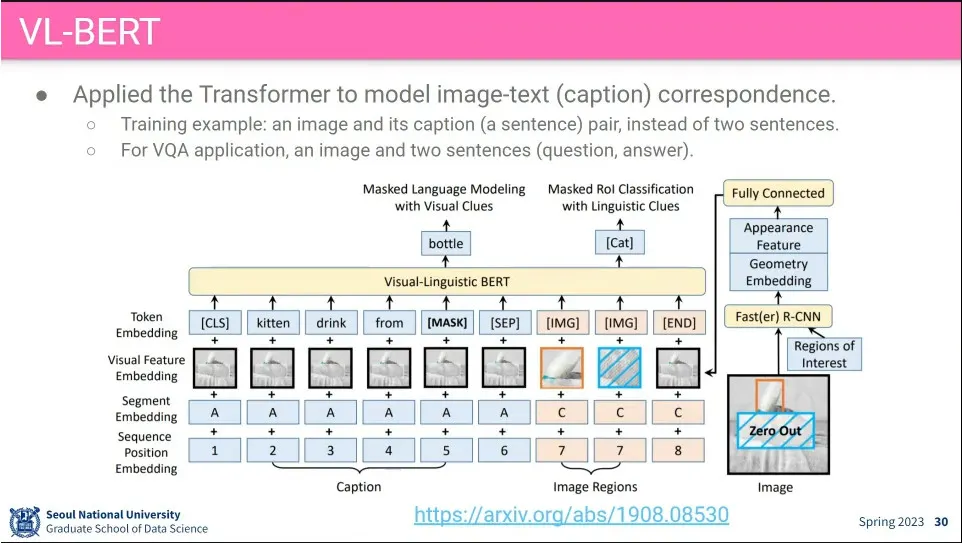
VL-BERT는 Transformer를 image-text 대응 모델에 적용 시킴. ViT보다 먼저 나옴.
•
caption과 image에 대해 token, segment, sequence position에 추가로 video feature embedding을 추가해서 넣어 줌.
◦
token은 기존 문장 token에 [img]를 추가해서 넣음
◦
segment는 문장과 이미지를 구분
◦
sequence는 sequence. image 부분은 detection 된 object의 좌표를 넣음
◦
visual feature는 text 부분에는 image 전체에 해당하는 feature를 넣음. image에는 object detection을 돌린 후에, detection된 object의 bounding box를 잘라서 넣음.
•
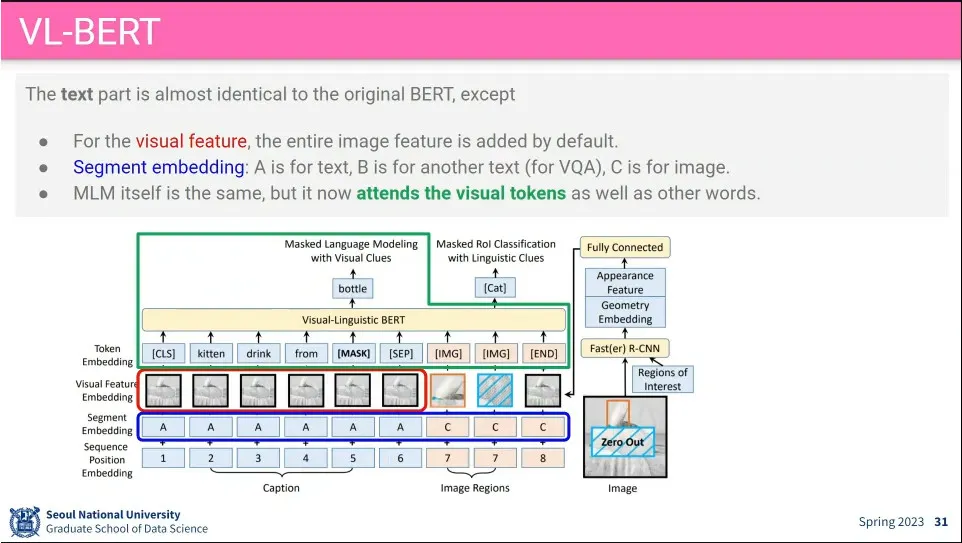
BERT의 MLM처럼 문장에 빈칸(Mask)을 만들어서 단어를 찾게 하는데, visual 데이터도 함께 보고 추측하게 함.

•
이미지에 대해서도 detection된 object를 Mask 씌우고, 거기에 어떤 이미지에 해당하는 text가 있어야 하는지를 맞추게 함.
◦
고양이에 mask를 씌우고, ‘Cat’이 나오게 함.
◦
Mask 씌워진 이미지가 무엇일지는 Caption 문장을 보고 추론하게 함.

•
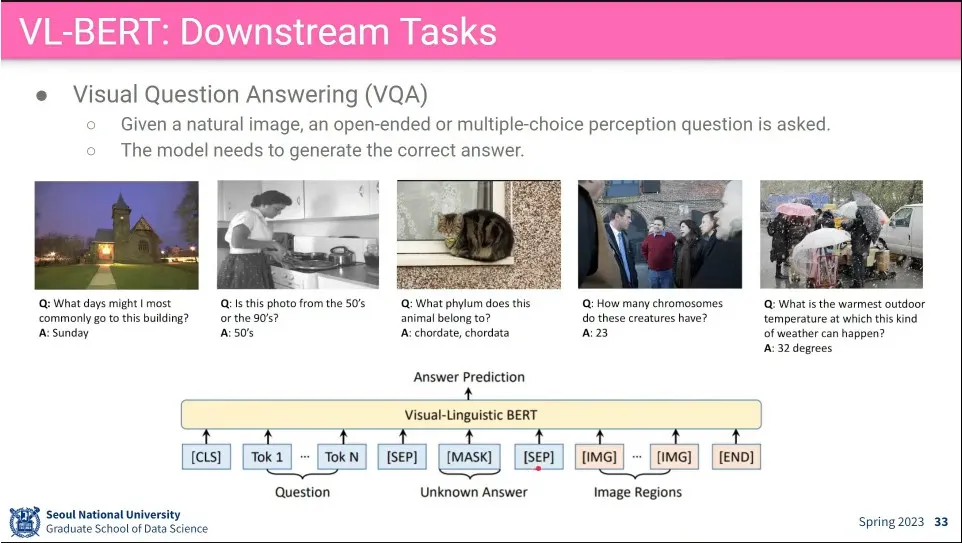
사례
•
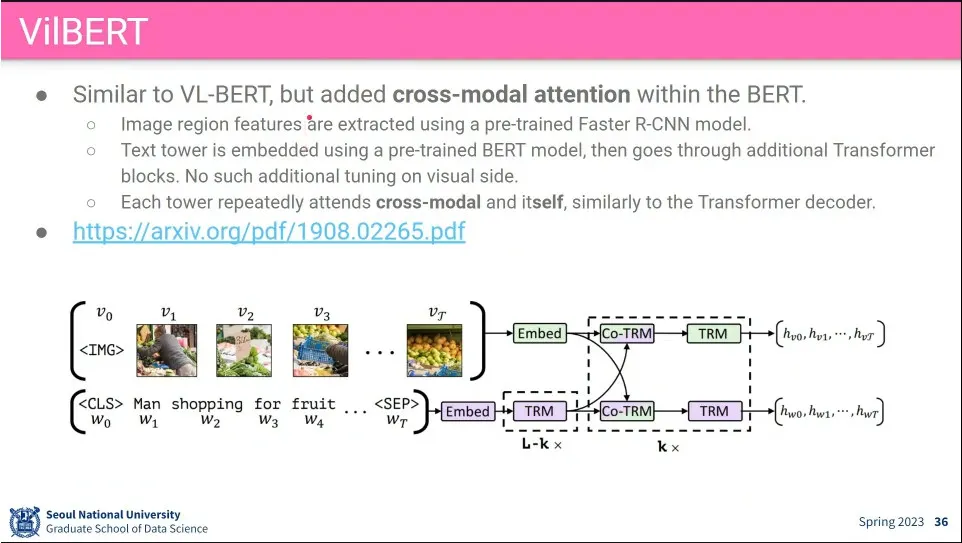
VL-BERT랑 비슷하게 나온 것이 VilBERT
◦
VL-BERT처럼 Fast R-CNN을 써서 object detection 해서 caption과 함께 input으로 넣어 줌
◦
attention 과정에 차이를 줌
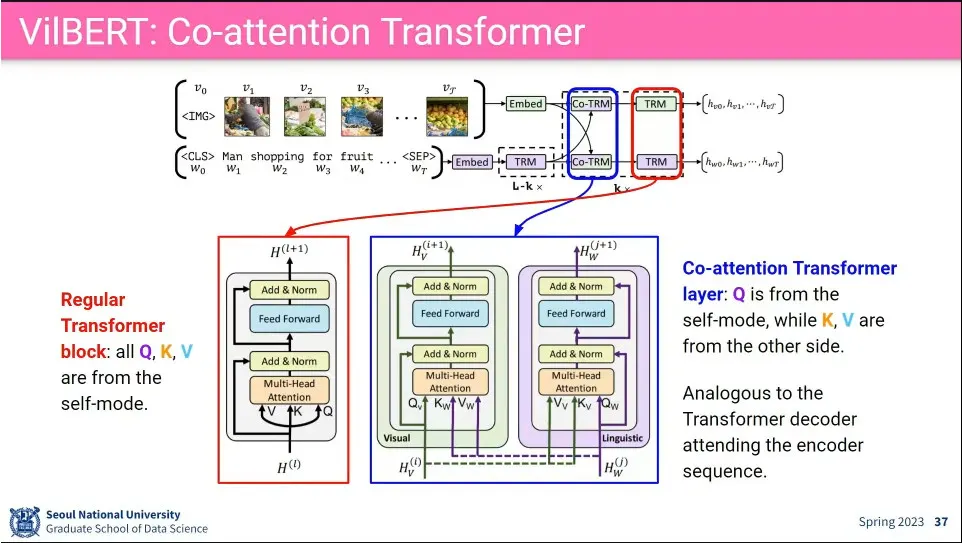
•
input을 같이 넣지 않고, visual, caption을 각각 돌림.
•
TRM은 전통적인 Transformer로 자기 자신에 대한 것을 돌리는데, 그 앞에 Co-TRM에는 visual, liguistic을 교차 시킴.
◦
이때 query는 자기 자신을 input으로 넣는데, key, value를 상대방 것 (visual이면 text, text면 visual)을 넣어 줌.
•
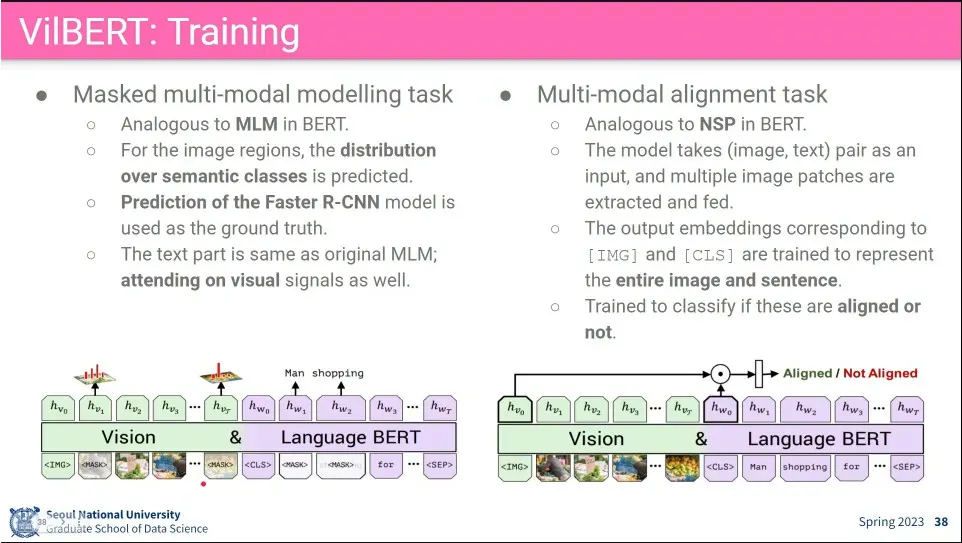
VilBERT의 학습 방법. BERT의 MLM과 Next sentence prediction에 대응하는 것을 1개씩 해 봄.
◦
MLM에서는 visual과 text에 각각 mask를 씌우고 visual이면 text, text면 visual 정보도 보면서 예측 가능하게 함.
◦
NSP 쪽에서는 문장이 visual 데이터를 예측하는게 맞냐 아니냐를 판정하게 함. 맞는 것 50% 틀린 것 50%를 넣어서 예측 돌림. 이게 상당히 강력함.
•
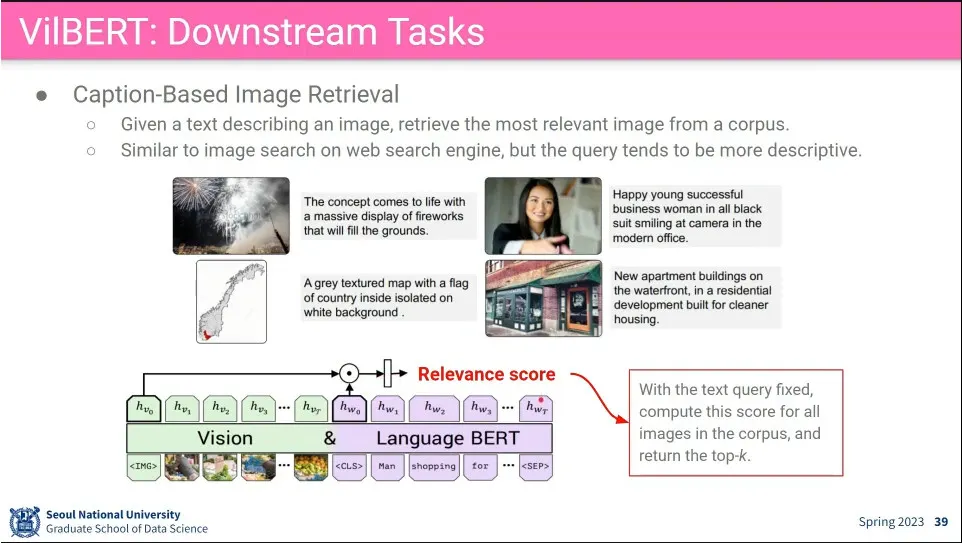
caption을 주면 그에 맞는 image를 검색하는 것을 함.
