
•
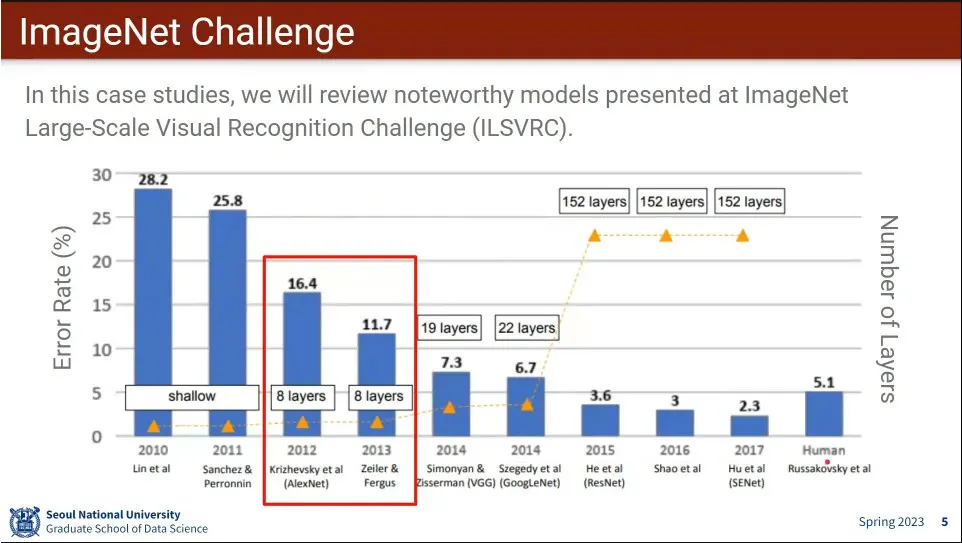
이미지넷의 AlexNet과 ZF-Net

•
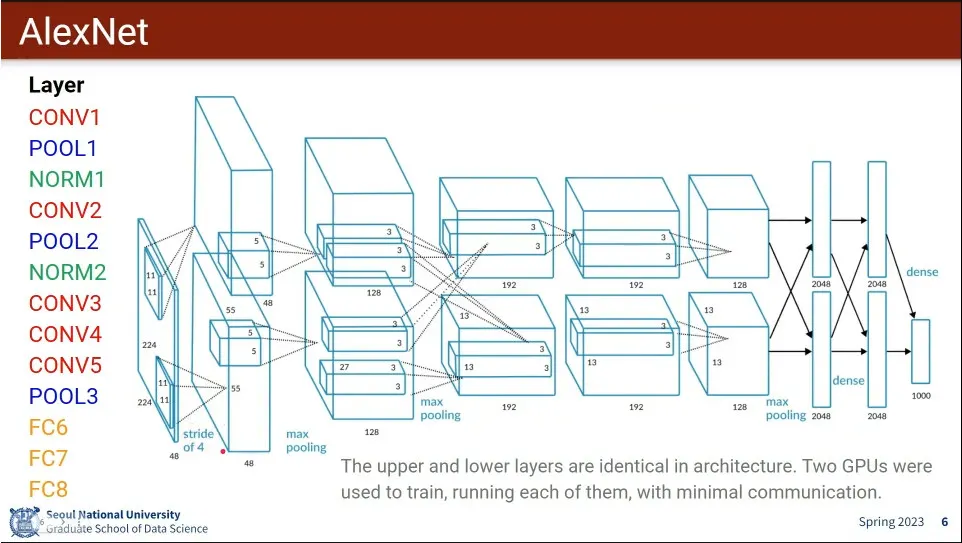
AlexNet 아키텍쳐

•
AlexNet의 세부 사항들
•
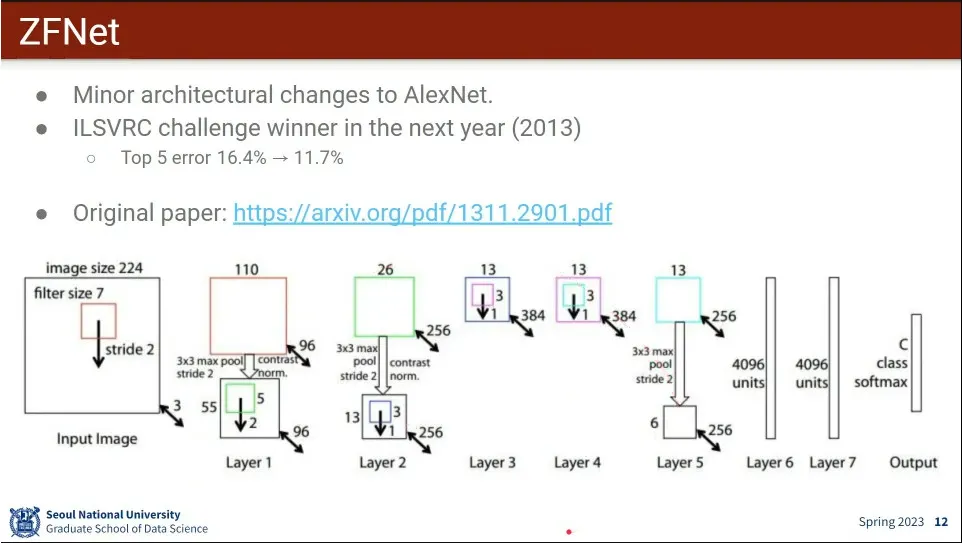
ZF-Net의 아키텍쳐.
◦
AlexNet과 비슷한데, 조금 더 튜닝해서 성능을 좀 더 높임

•
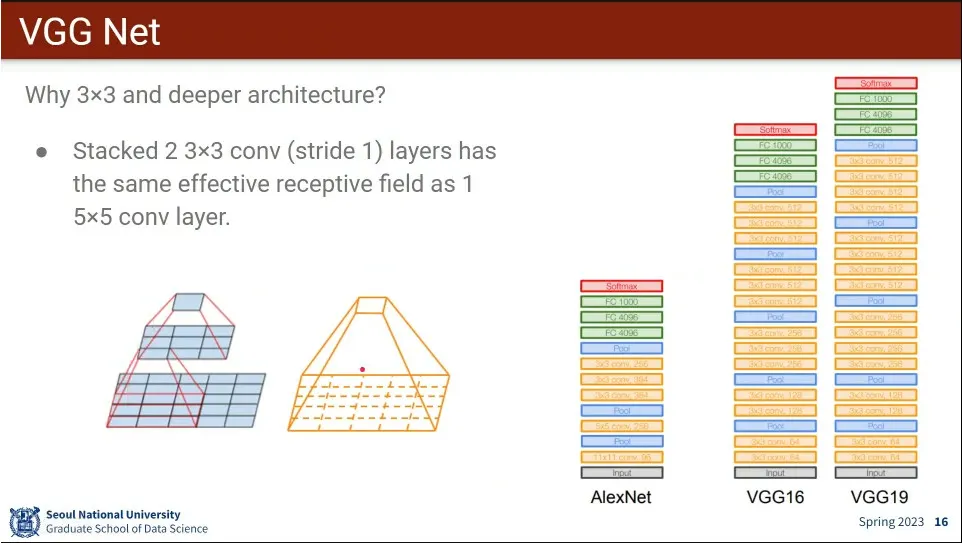
VGG Net 아키텍쳐
◦
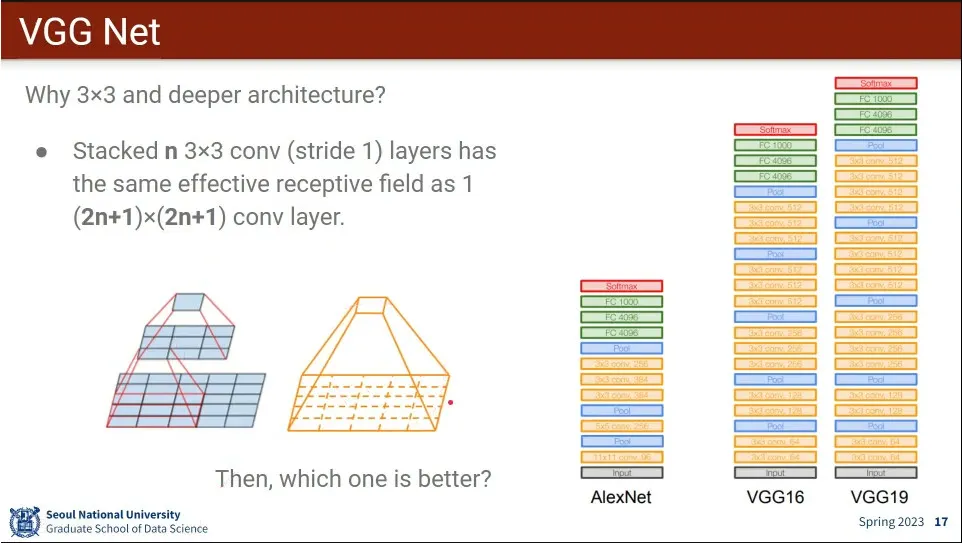
conv를 3x3만 쓴 것이 특징
•
3x3을 2층으로 쌓으면 5x5 효과를 갖는다.
◦
같은 식으로 3x3를 계속 쌓으면 모든 크기의 filter를 대응시킬 수 있음

•
3x3을 여러 개 쌓는 것이 성능이 더 유리함.
◦
3x3을 3개 쌓으면 파라미터가 27개가 필요하지만, 7x7로 쌓으면 49개가 필요함.
◦
3x3을 쌓는 것은 O(n)인데, nxn 1개를 쓰면 O(n^2)이 됨
•
3x3을 여러 층 쌓으면 중간에 activation function도 여러 개 들어가기 때문에 추가로 성능도 더 좋음

•
VGG Net 아키텍쳐
◦
메모리는 앞쪽 layer가 많이 먹고, 파라미터는 뒤쪽 layer가 많이 먹는다.

•
VGG Net 상세

•
GoogLeNet이 VGG가 나왔던 해애 1등 함. VGG는 2등.
•
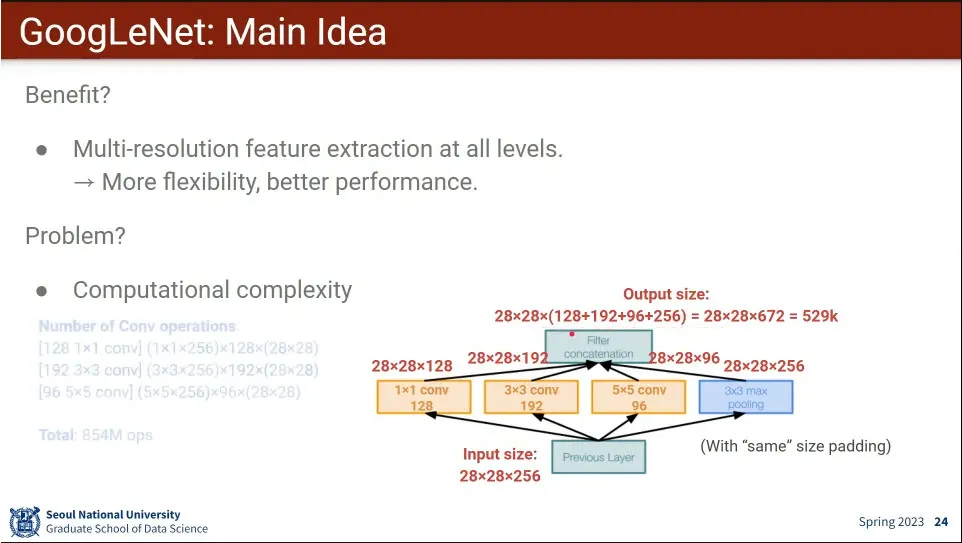
Filter의 크기를 여러 개를 쓰는게 핵심 아이디어. filter를 여러 개 쓰고 그 결과를 channel-wise로 합친다.
◦
이것 때문에 Inception이라고 불림.
•
모든 레벨에서 다양한 해상도의 feature를 뽑을 수 있고, 그래서 성능도 더 좋다는 장점이 있음.
•
계산량이 너무 많다는 단점이 있음.

•
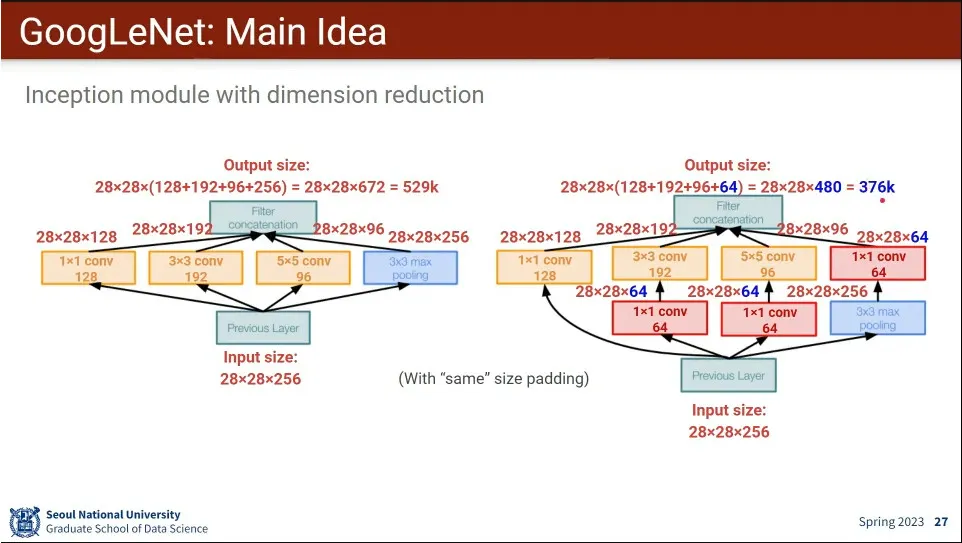
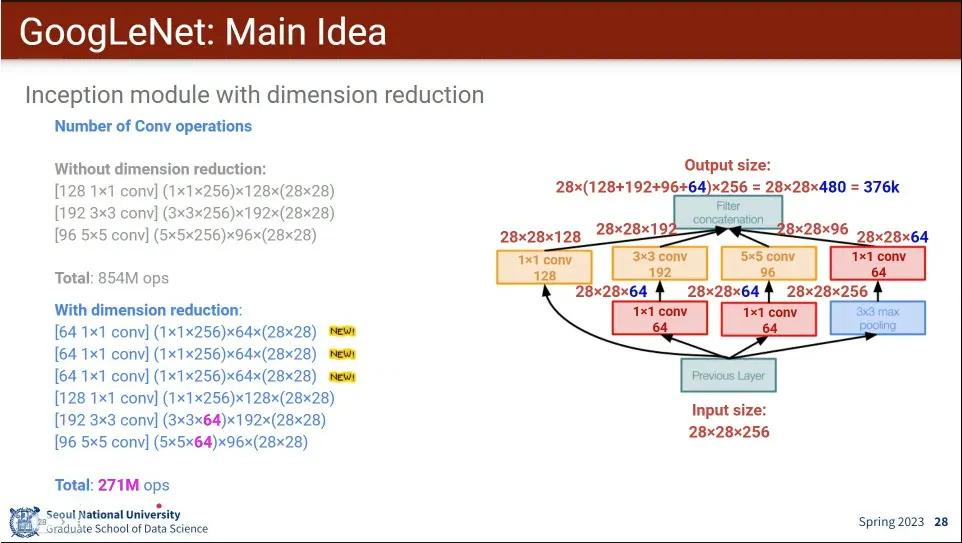
계산량을 줄이기 위해 1x1 conv로 dimension reduction을 함.
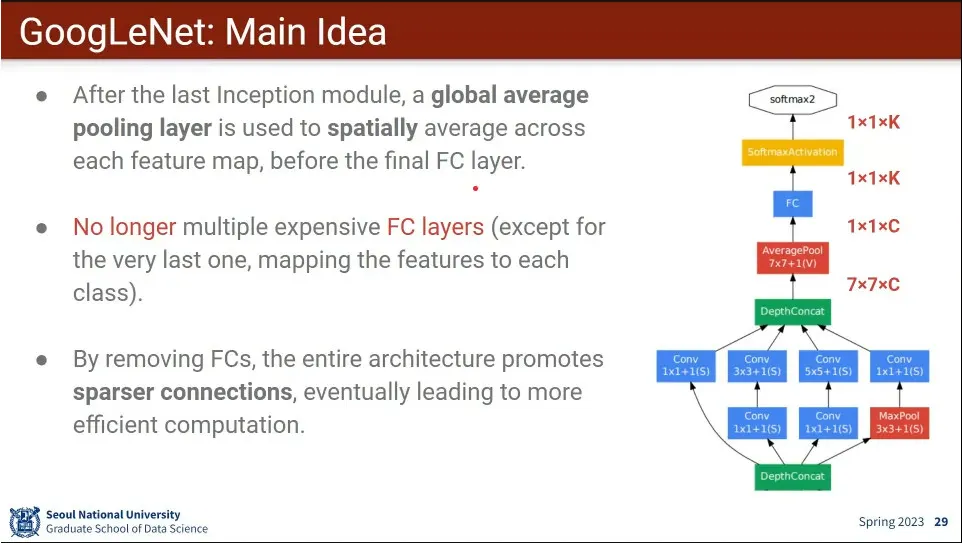
•
Fully-connected 를 없앤 것도 특징.
◦
마지막에 있는 fully-connected 레이어가 연산량을 많이 잡아 먹기 때문에 없애고 AveragePool을 사용 함.
•
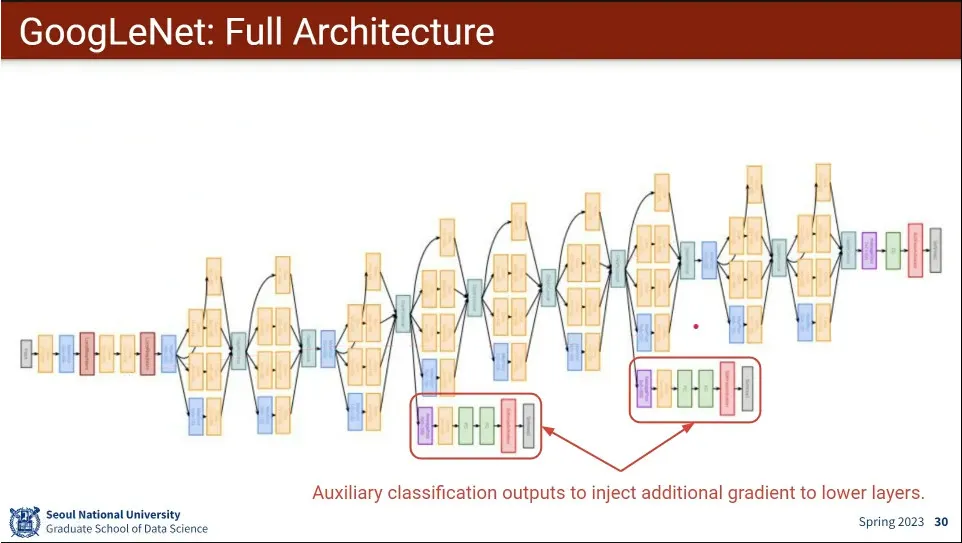
GoogLeNet의 아키텍쳐
◦
gradient 소실 문제 때문에 inception 모듈 중간에 2번 넣어줌.
◦
나중에 밝혀진 사실에 의하면 안해도 되는 것으로 결론 남.

•
GooLeNet의 상세
◦
겉으로 보기에 복잡해 보이지만 AlexNet이나 VGG16 보다 가벼운데, 마지막 Fully-connected을 없앤 것이 큰 효과를 냄.
•
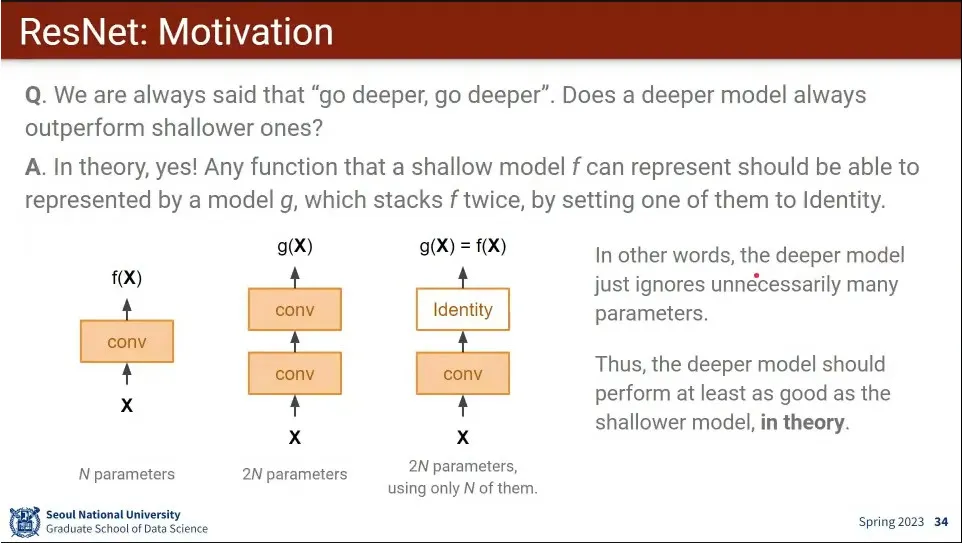
모델이 더 깊어지면 이론적으로는 성능이 좋아져야 됨.
◦
만일 2층일 때의 결과가 1층일 때의 결과와 같아야 한다면 2층을 identity로 만들면 되기 때문에, 1층에서 가능한 것은 2개 층에서는 모두 가능하지만, 그 반대는 아니므로.
•
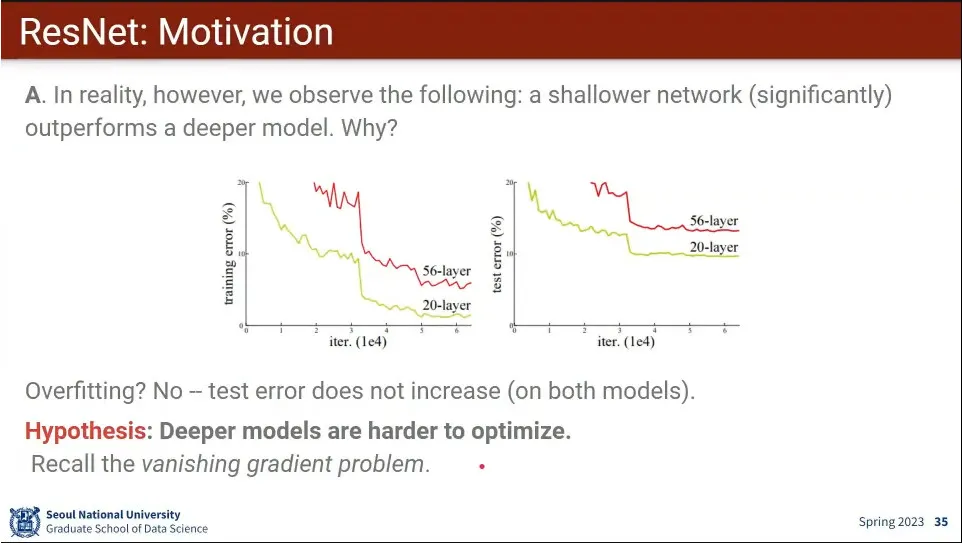
근데 실제로 해보니 더 적은 layer가 더 나은 성능이 나오는 경우가 있음.
◦
깊은 모델을 최적화 시키는게 더 어려워서 그런거 아닐까? 하는 가설이 등장함.

•
그래서 input을 output에 shortcut(원래 input)을 더해 주는 방식을 도입함.
◦
예전에는 x에서 h(x)를 바로 모델링을 해야 했지만, default로 x가 가기 때문에 x와 h(x)의 차이가 존재하면 그 차이를 모델링하도록 학습이 됨.
◦
만일 layer가 깊어져서 x와 h(x)가 이미 비슷해져 있으면, 배울게 없으므로 모델이 그 layer는 안 쓰게 됨. —identity가 됨
◦
모델이 스스로 필요하지 않으면 layer을 안 쓰기 때문에 layer을 왕창 쌓는게 가능해 짐.
•
덕분에 layer가 22층에서 152층으로 깊어짐.
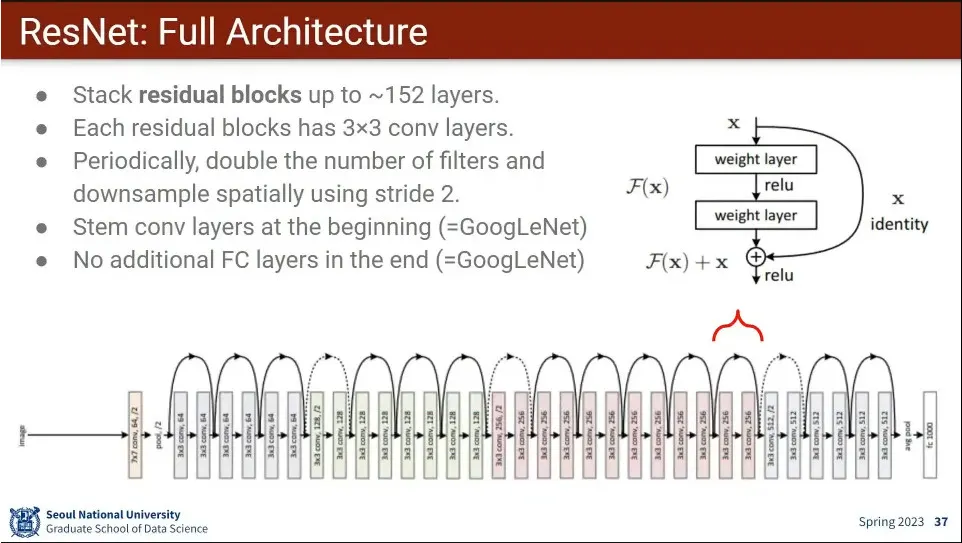
•
ResNet의 아키텍쳐
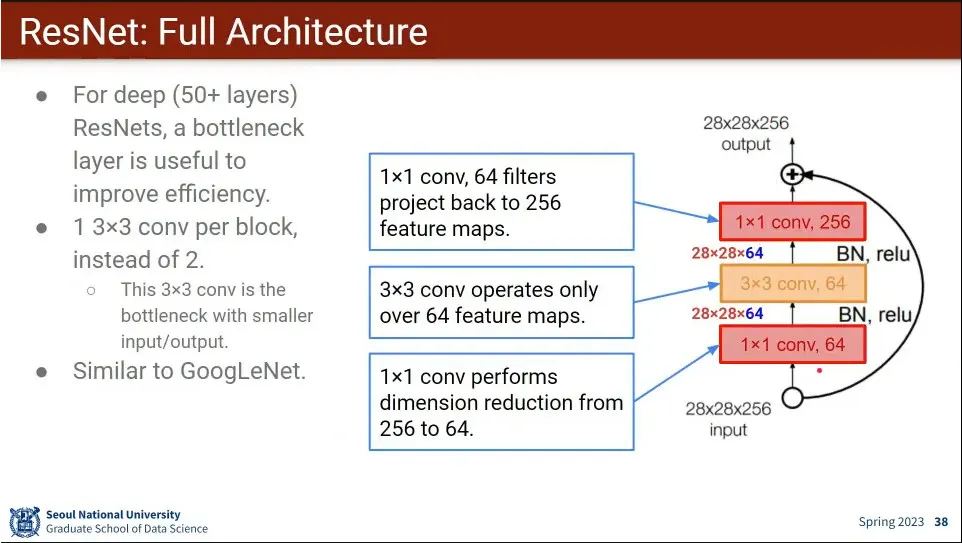
•
resnet은 output에 input을 더해서 나가야 하기 때문에 최종 크기가 input과 같아져야 한다는 제약이 존재함.
◦
때문에 계산량이 많아져서 줄이기 위해 1x1 conv를 쓰는데, output에 더할 수 있도록 크기를 다시 늘리는 1x1 conv를 추가로 사용함. 앞 뒤로 1개씩 배치

•
Resnet 상세
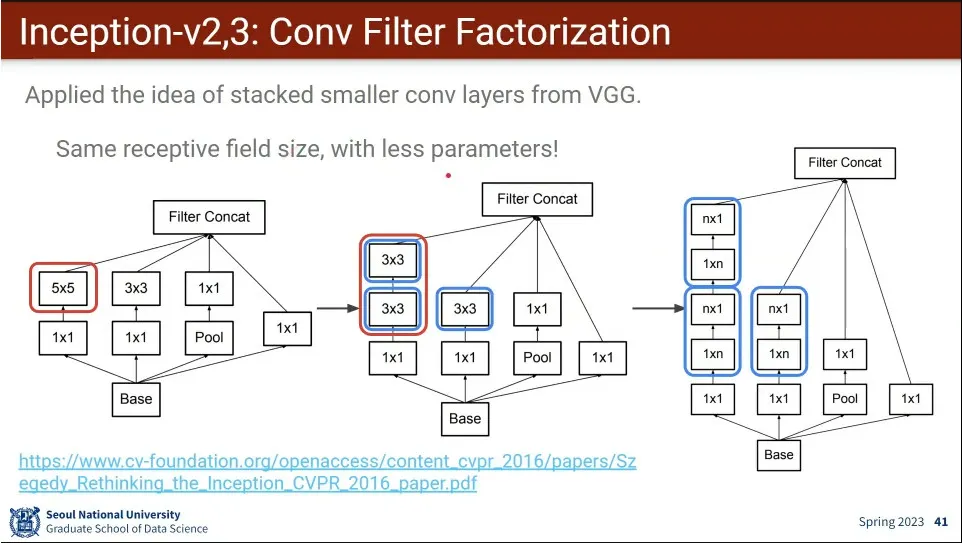
•
Inception의 version 2, 3. 동시에 공개 되어서 사실상 같은거라고 볼 수 있음.
◦
vgg에서 3x3으로 다 할 수 있으므로 그걸 반영한 버전.
◦
추가로 3x3을 1x3, 3x1나 나누는 것도 함.
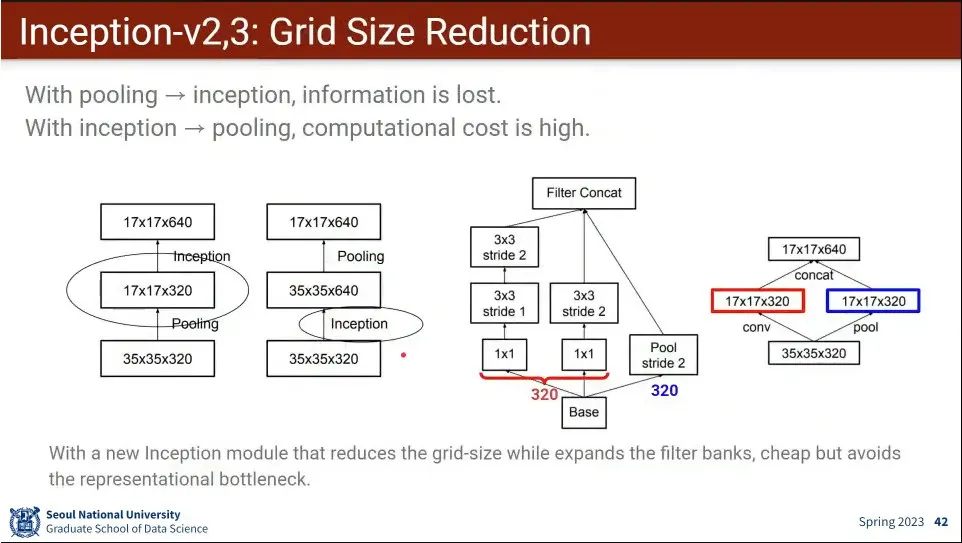
•
pooling→inception과 inception→pooling의 각각의 단점이 있어서 둘을 합침
•
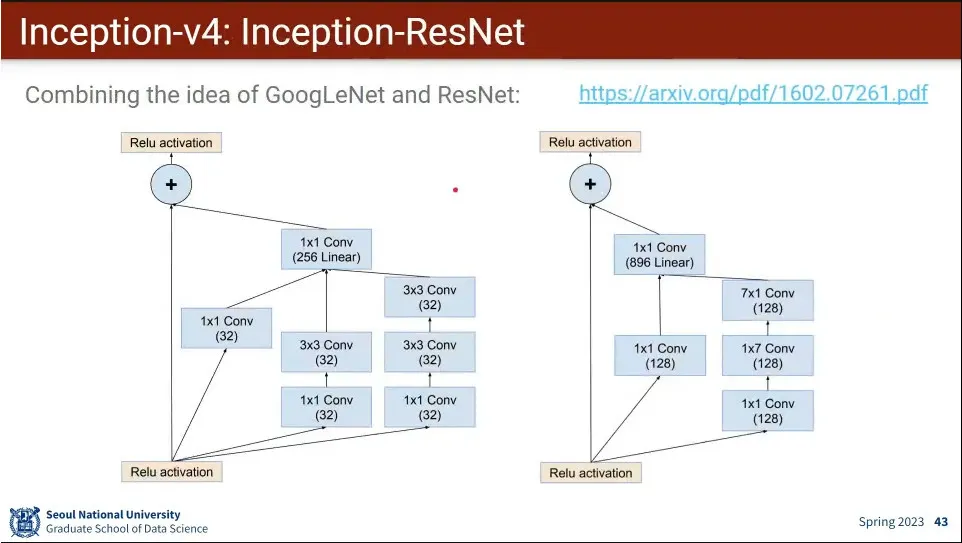
inception v4는 resnet의 아이디어를 추가한 버전
•
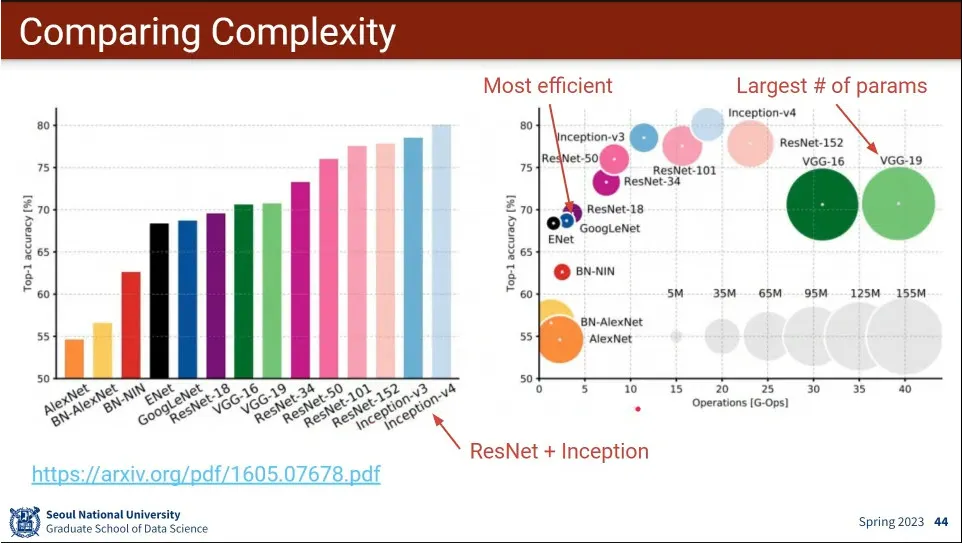
Inception v4가 성능도 가장 좋고, 계산량도 중간 정도.
•
최근의 나온 결과물들
