
Invertible transformations (bijections)
•
가 인 전단사(bijection)라고 하자.
◦
전단사는 단사(injective), 즉 one-to-one이고 전사(surjective)인 함수이다. 이것은 함수가 역이 잘 정의되었다는 것을 의미한다.
•
의 pdf를 계산하기 원한다고 가정하자. change of variables 공식은 다음을 말한다.
•
여기서 는 에서 계산된 역행렬 의 야코비안이다. 그리고 는 의 determinant(행렬식)의 절대값이다. 즉
•
야코비안 행렬이 삼각이면 행렬식은 주 대각 항들의 곱으로 축소된다.
Monte Carlo approximation
•
때때로 야코비안을 계산하는 것이 어려울 수 있다. 이 경우에 Monte Carlo 근사를 만들 수 있다. 개의 샘플 를 뽑고 를 계산한 다음 경험적 pdf를 구성하면 된다.
•
예컨대 이고 이고 라 하면 몬테 카를로를 사용하여 를 근사할 수 있다.
Probability integral transform
•
가 cdf 의 확률 변수라 하고 를 의 변환이라고 하자. 이제 가 균등 분포를 가지면 결과는 probability integral transform(PIT)임을 볼 수 있다.
•
예컨대 아래 그림 왼쪽 열에서 pdf의 의 다양한 분포를 볼 수 있다.
◦
이것으로부터 샘플링하면 를 얻는다. 다음으로 을 계산한 다음 값을 정렬하여 의 경험적 cdf를 계산한다. 결과는 중간 열에 보인다. 이 분포가 균등임을 보일 수 있다.
◦
또한 커널 밀도 추정을 사용하여 의 pdf를 근사할 수 있다. 이것은 오른쪽 열에 보인다. 그리고 이것이 (근사적으로) 편평함을 볼 수 있다.
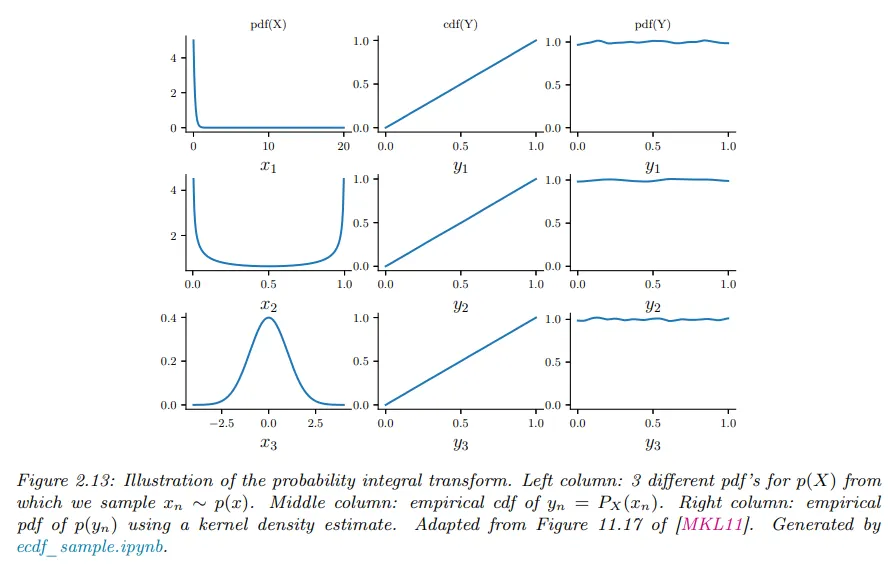
•
Kolmogorov-Smirnov test를 사용하여 샘플들의 집합이 주어진 분포에서 나왔는지 테스트하기 위해 PIT를 사용할 수 있다. 이것을 하기 위해 샘플들의 경험적 cdf와 분포의 이론적 cdf를 plot하고 이 두 커브 사이의 최대 거리를 계산한다. 아래 그림 참조.
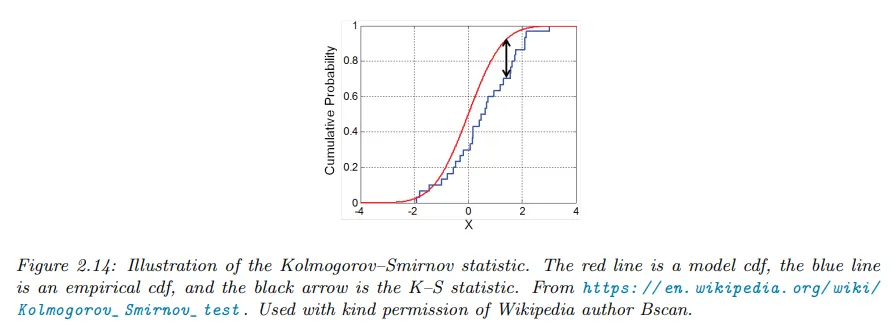
•
형식적으로 KS 통계량은 다음처럼 정의된다.
•
여기서 은 샘플 크기이고
◦
은 경험적 cdf이고
◦
는 이론적 cdf이다.
•
샘플이 로부터 뽑힌 경우 값 은 0에 접근해야 한다(.
•
PIT의 또 다른 응용은 분포에서 샘플을 생성하는 것이다. 균등 분포 에서 샘플링하는 방법이 있으면, 를 설정하여 이것을 cdf 가 있는 다른 분포의 샘플로 변환할 수 있다.
