
•
RNN에 대해서 이전에 들었던 것에 더 상세한 부분이 있음. 아래 페이지 참조
•
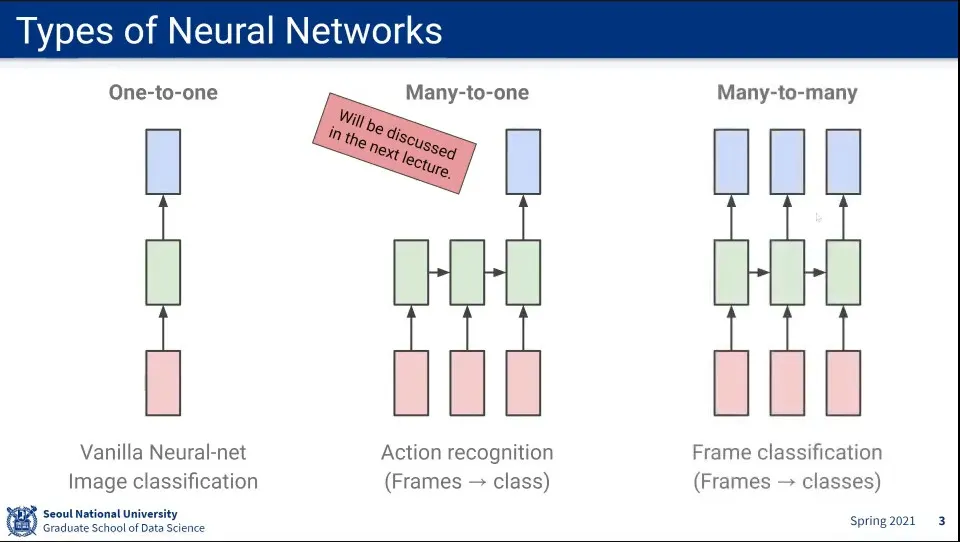
Neural Network의 여러 종류
◦
Input, Output이 모두 1개인 것도 있고
◦
Input이 여러 개인데 Output이 1개인 것도 있고
◦
Input이 여러 개이고 Ouptut도 여러 개인 것도 있다.
◦
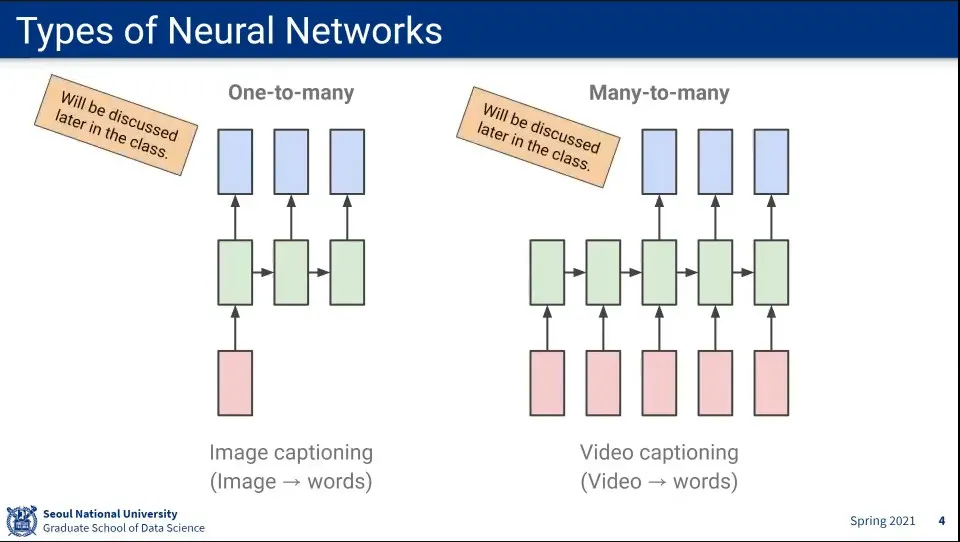
Input이 1개인데, Output이 여러 개인 것도 있다.
◦
Input과 Output 모두 여러 개인 것도 있다. —3번째와는 다름
•
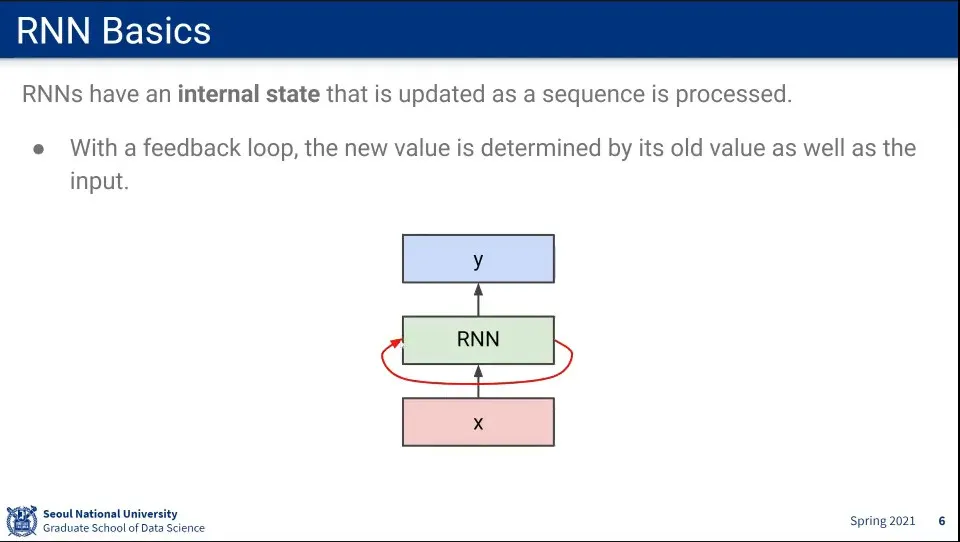
RNN은 Input을 받을 때 자신의 상태를 업데이트하는 feedback loop를 돈다.
•
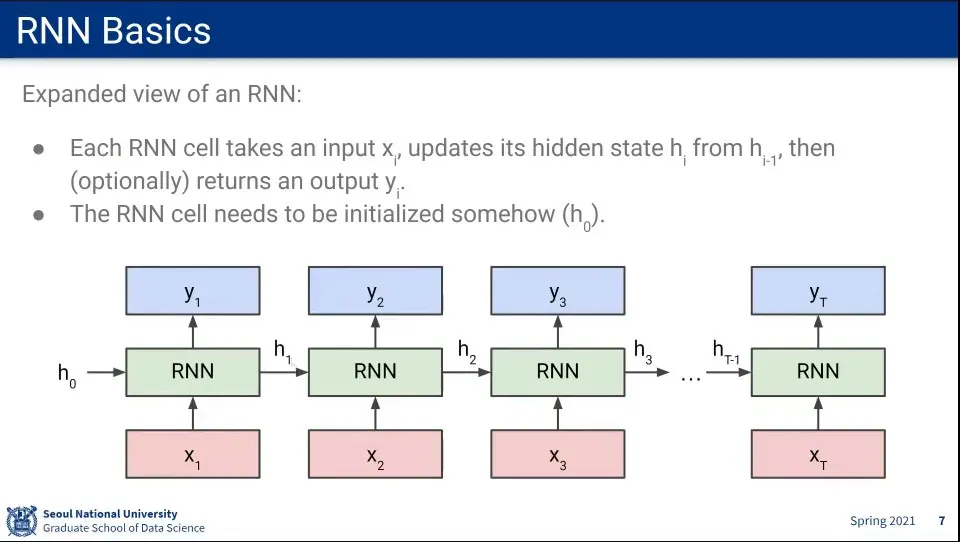
시퀀스를 펼치면 위와 같다.
◦
input을 받아서 hidden state를 업데이트하고 output을 내보낸다. (output을 안 내보낼 수도 있음)

•
이전 hidden state()와 현재 input()을 받아 hidden state()를 업데이트 한다.

•
hidden state를 업데이트 할 때는 tanh를 사용한다.
•
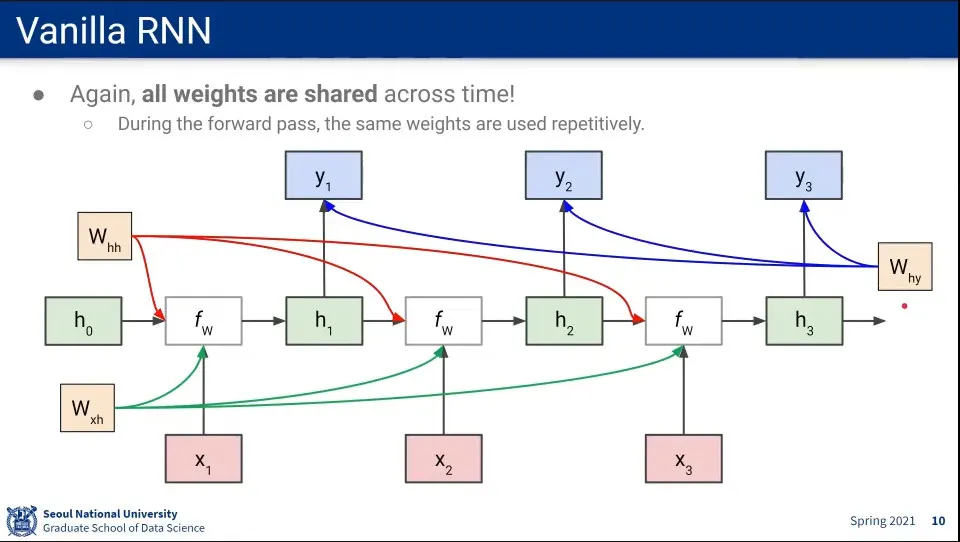
각 위치에서 사용되는 가중치()는 sequence가 바뀌더라도 항상 같은 것을 사용한다.
•
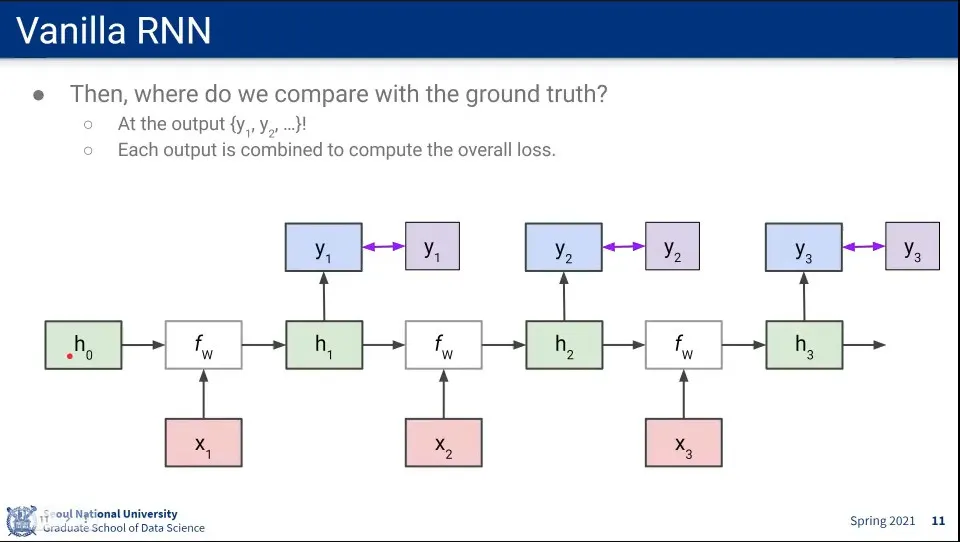
Loss가 각 output에 대해 발생하기 때문에 앞쪽에 있는 state에 대해 계속 Loss가 계산된다.
◦
은 의 loss를 모두 받음. 은 의 loss만 받음
•
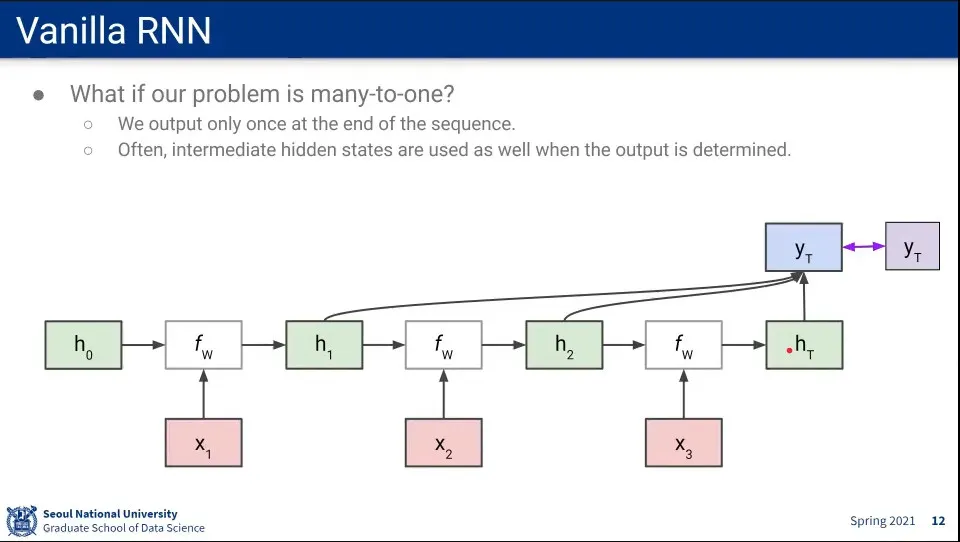
만일 Many-to-One인 경우라면 Loss 계산을 한 번만 하게 된다.
◦
이때 시퀀스가 길어지면 앞쪽 state의 값은 잃어버릴 수 있으므로, 그 값을 유지하고 있다가 최종 output을 계산할 때 함께 사용한다.
•
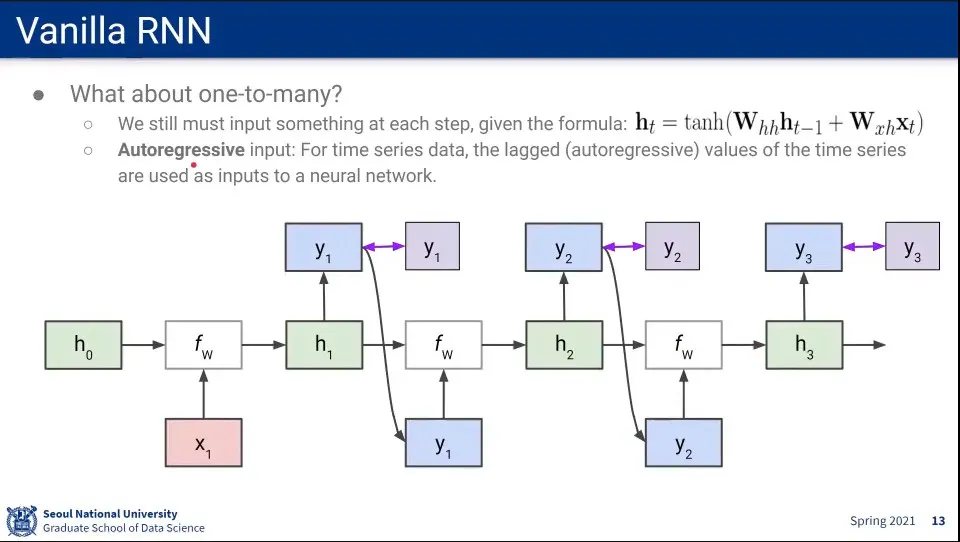
One-to-Many인 경우는 Input이 1개 뿐이므로, 이전 단계의 output을 input으로 넣어 사용한다.
•
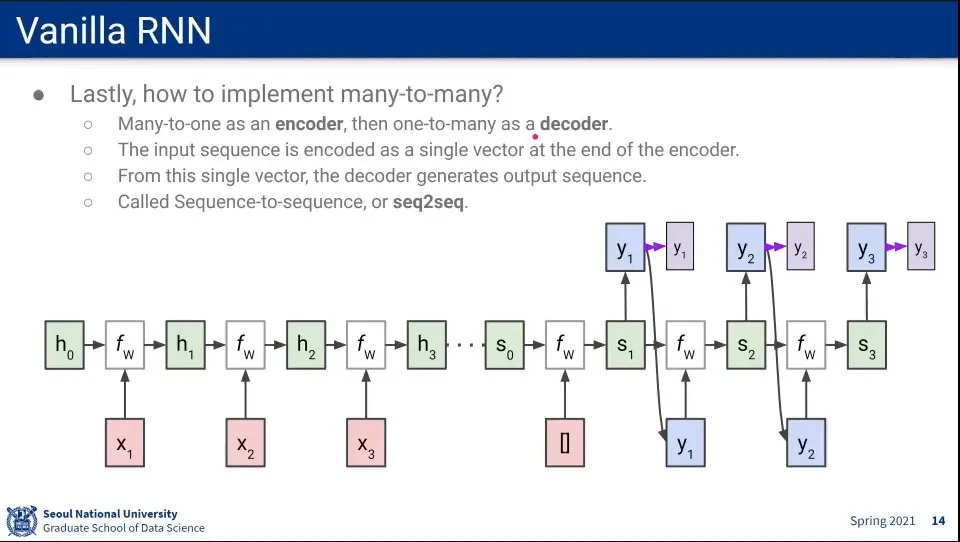
Many-to-Many는 Many-to-One과 One-to-Many를 합하여 구성한다.
◦
이때 Many-to-One은 Encoder라고 하고, One-to-Many는 Decoder라고 한다.
•
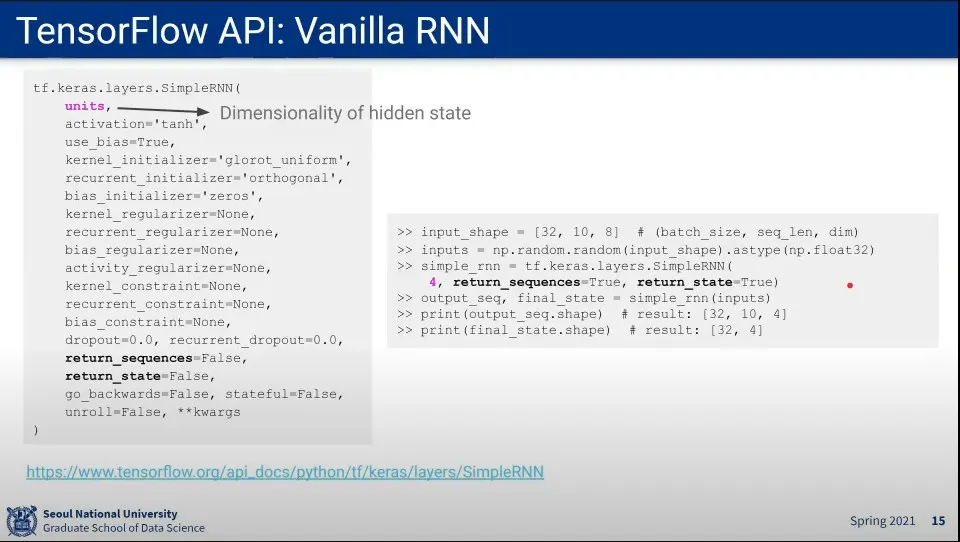
TensorFlow에서 RNN 사용하는 방법

•
RNN 장점
◦
항상 같은 W를 쓰기 때문에 길이에 제한이 없다.
◦
따라서 Input이 아무리 커져도 모델 사이즈가 커지지 않는다.
◦
이론적으로는 오래 전 state도 현재에 활용 될 수 있음
•
RNN 단점
◦
느림
◦
순차적이라서 parallel하게 처리할 수 없음
◦
vanishing gradient 문제가 발생함
◦
현실적으로 long-range dependence를 해결하지 못 함
•
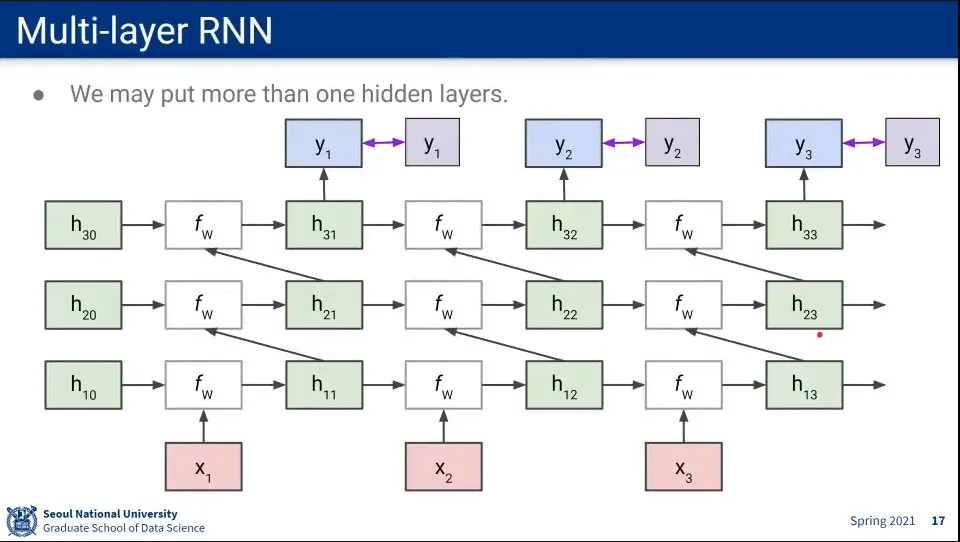
RNN의 Hidden Layer를 여러 층으로 쌓은 것을 Multi-layer RNN이라고 함

•
RNN 활용 예 - Image Captioning

•
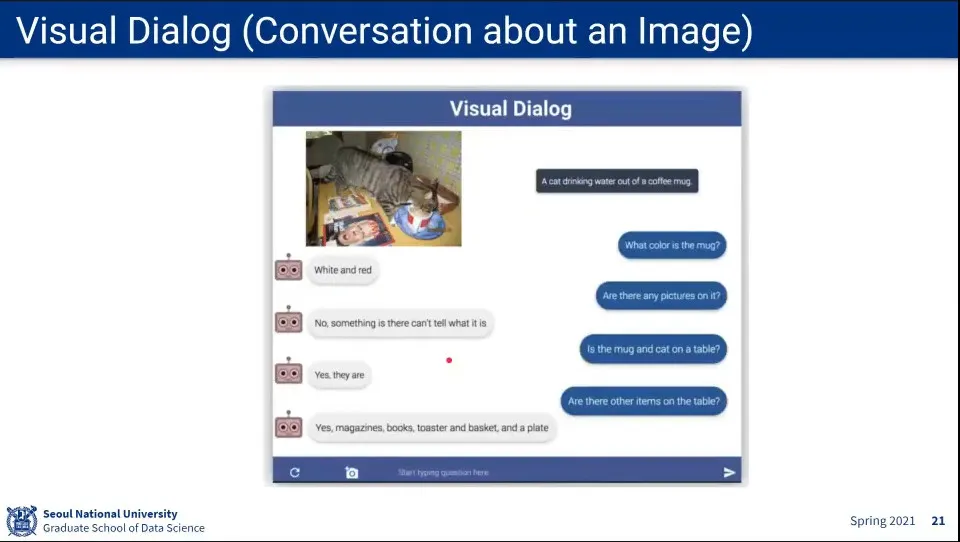
이미지 보고 Q&A
•
Visual Dialog
•
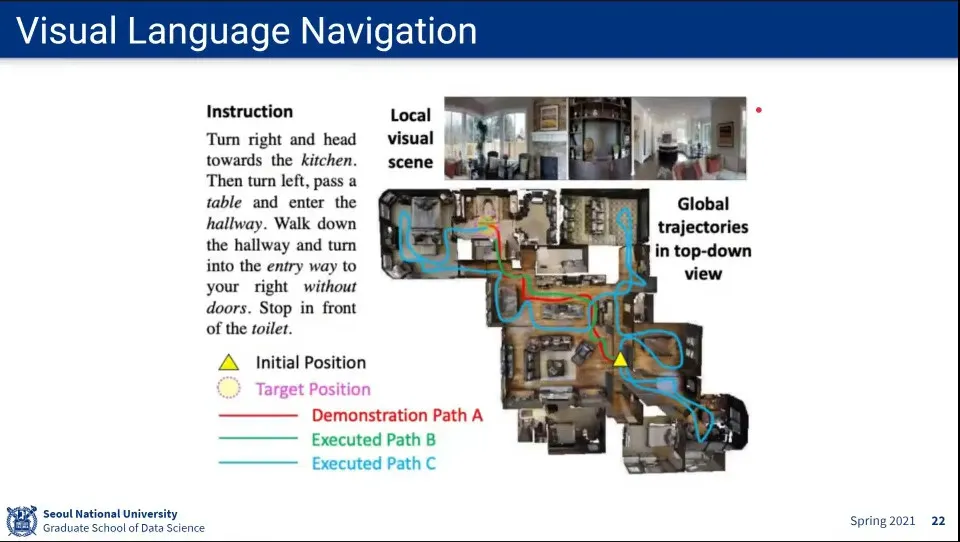
Visual Language Navigation

•
RNN은 NLP에서 많이 쓰임
•
여기서는 Video와 Multi Modal 문제에 적용해 보겠다.
•
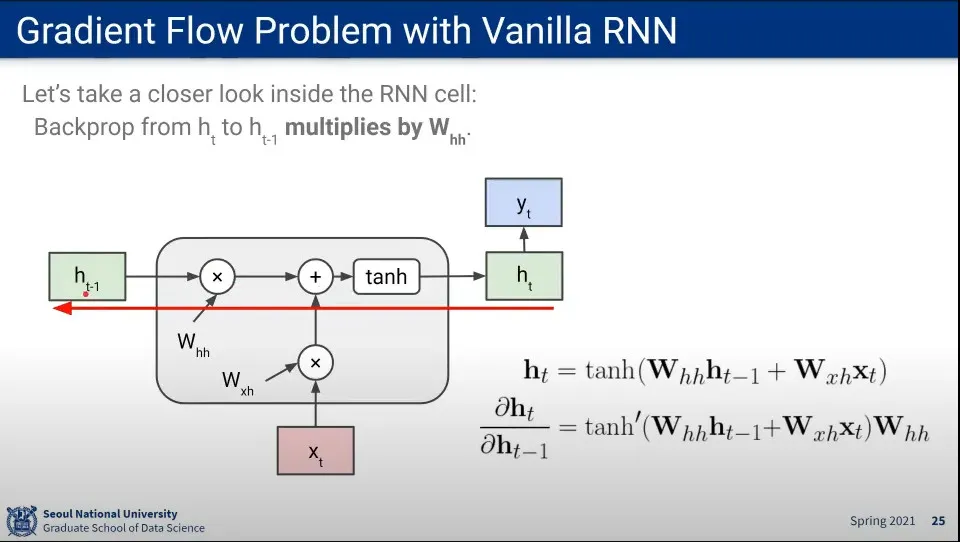
RNN의 Gradient 계산 방식
•
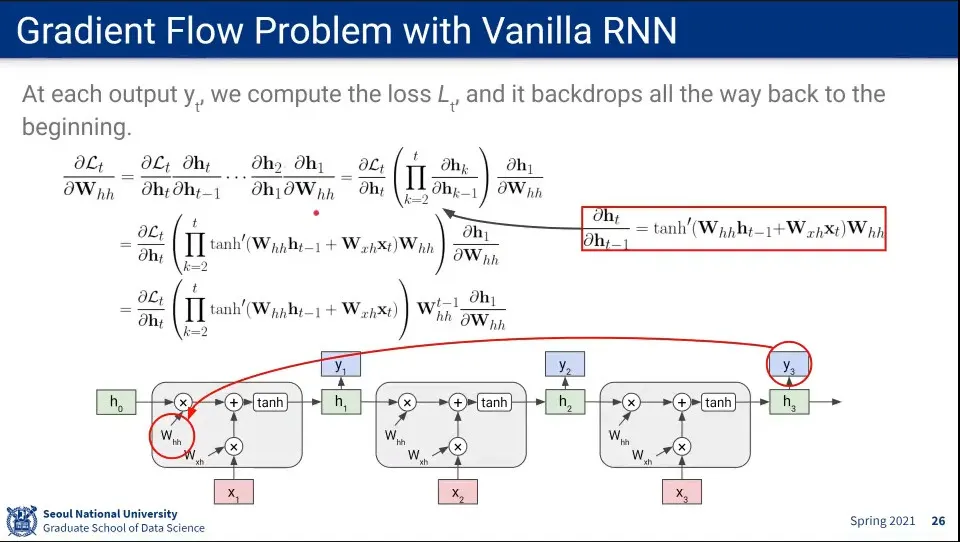
같은 W에 대해 Gradient 계산이 반복 됨

•
tanh는 1과 -1 사이의 값이 나오는데, 이걸 계속 반복해서 계산하면 0으로 가게 됨
◦
그 옆의 W도 1보다 작으면 소실될 수 있고, 1보다 크면 폭발할 수 있음
◦
폭발하는 경우를 막기 위해 특정 값 이상으로는 못 올라가게 clipping 할 수도 있음.
◦
하지만 vanishing하는 경우는 해결이 불가
•
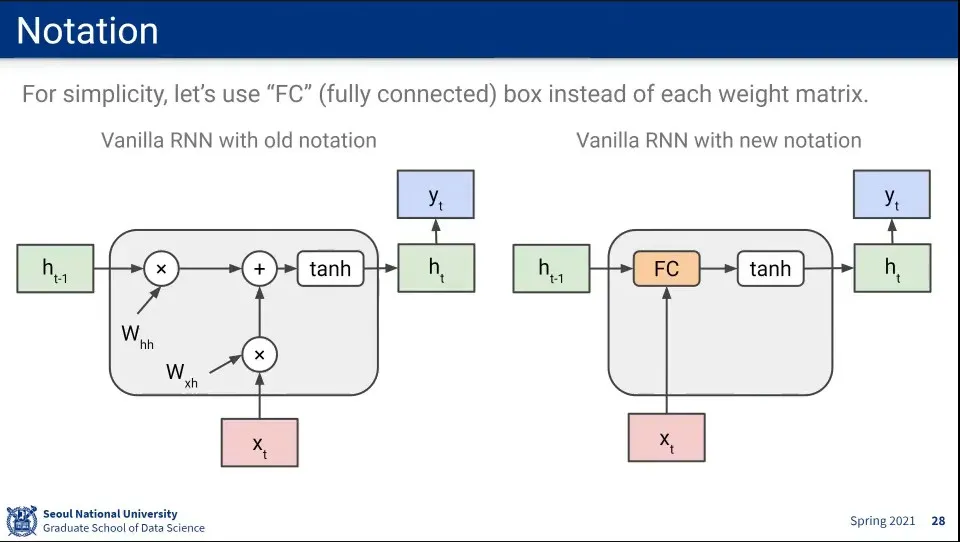
RNN 구조 notation을 오른쪽과 같이 축약하여 표기
•
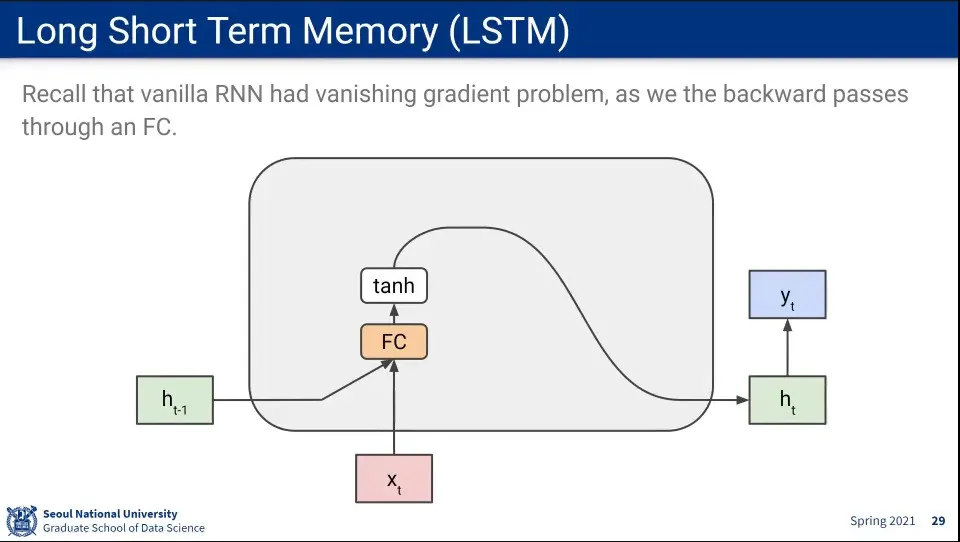
Vanishing Gradient 문제를 해결하기 위한 방법이 LSTM
•
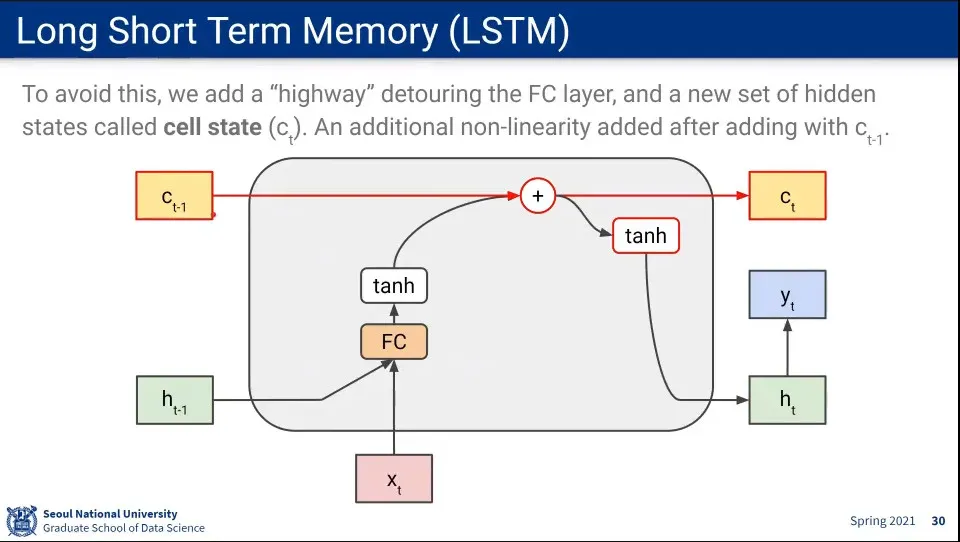
Fully-Connected를 반복해서 gradient가 소실되기 때문에 FC를 반복하지 않도록 하는 별도의 cell state라는 state를 추가하고, cell state는 FC를 하지 않음
•
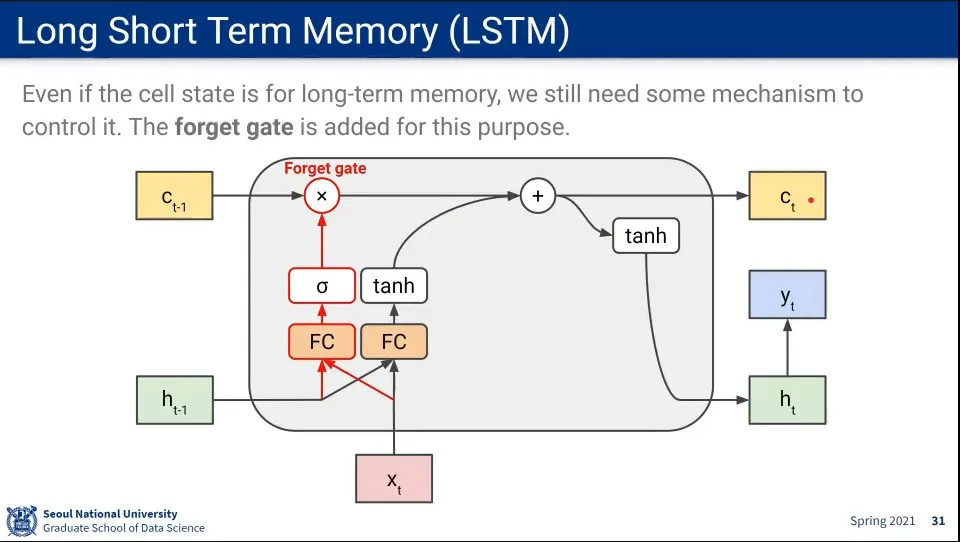
그래도 long term memory(cell state)가 모든 정보를 계속 가지고 있으면 안되기 때문에 적절하게 잊어줄 수 있게 forget gate를 추가해 줌
◦
이전 hidden state와 input을 fully-connected 하는 건 마찬가지 동일한데, 그것을 sigmoid 함수에 넣은 결과와 곱해서 이전 것 중에 잊어야 할 것은 잊게 해 줌
•
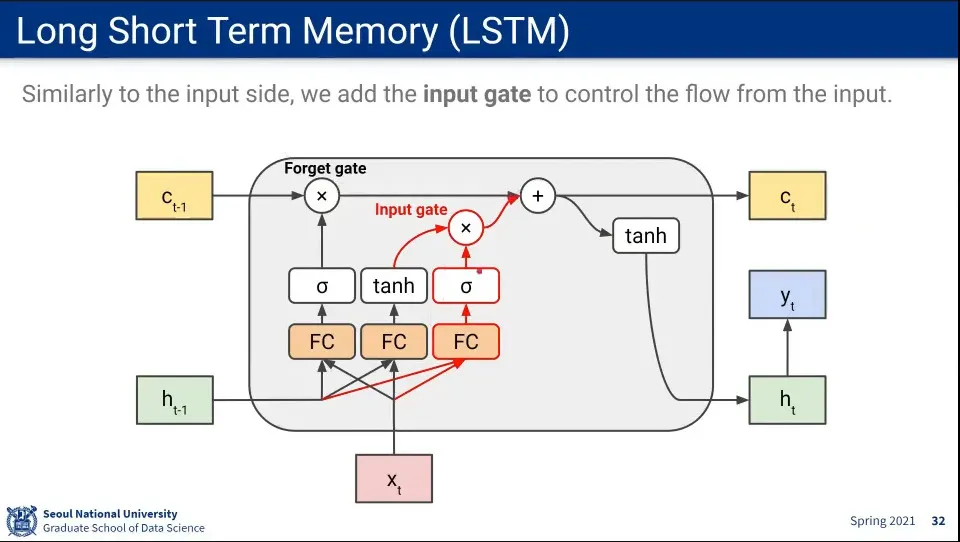
long term memory에서 잊어야 할 것을 잊은 후에는 새로운 것을 추가해 주기 위해 input gate를 추가해 줌
◦
이전 hidden state와 input을 FC하고 sigmoid를 통과한 것까지는 동일한데, 이것을 tanh를 통과한 것과 곱한 뒤에 forget gate를 통과한 것에 더해 줌
◦
그렇게 더해준 값이 cell state에 남겨짐
•
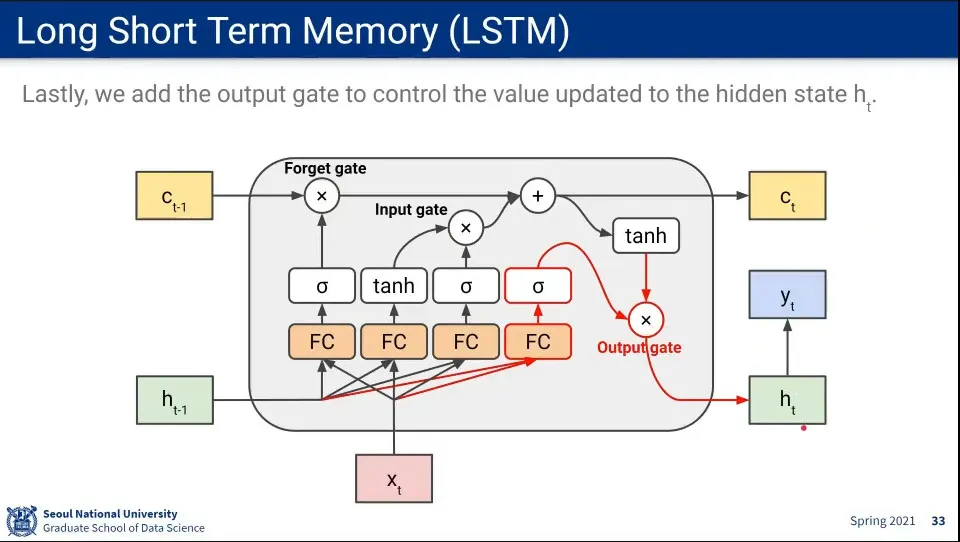
다음 state를 업데이트 하기 위해 output gate를 추가해 줌
◦
이전 hidden state와 input을 FC하고 sigmoid를 통과한 것까지는 동일한데, 이것을 앞서 계산한 long-term 기억과 곱해서 long term 기억을 일부 반영한 후 hidden state를 업데이트 함
•
결국 long-term(cell state), short-term(hidden state)와 forget gate, input gate, output gate를 이용해서 구성 함
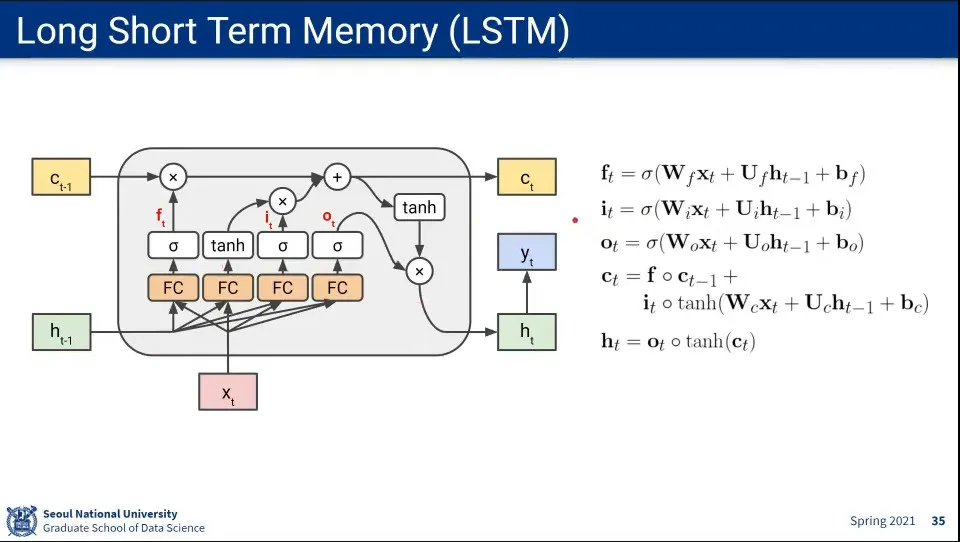
•
위 흐름에 대한 수식
•
장기 기억(Cell State)는 forget gate를 통해 데이터를 일부 잃지만, input gate에서 새로운 input을 지속적으로 더해주기만 하기 때문에 기억을 오래 유지할 수 있다.
◦
반면 단기 기억(Hidden State)는 Fully-Connected와 장기 기억과의 곱이 다음 State로 넘어가기 때문에 기억을 잃게 됨. 가장 최근의 Input만 오래 살아 남는다.

•
LSTM은 Vanishing Gradient를 많이 줄여준다. 그러나 완전히 없애 주지는 못 한다.
•
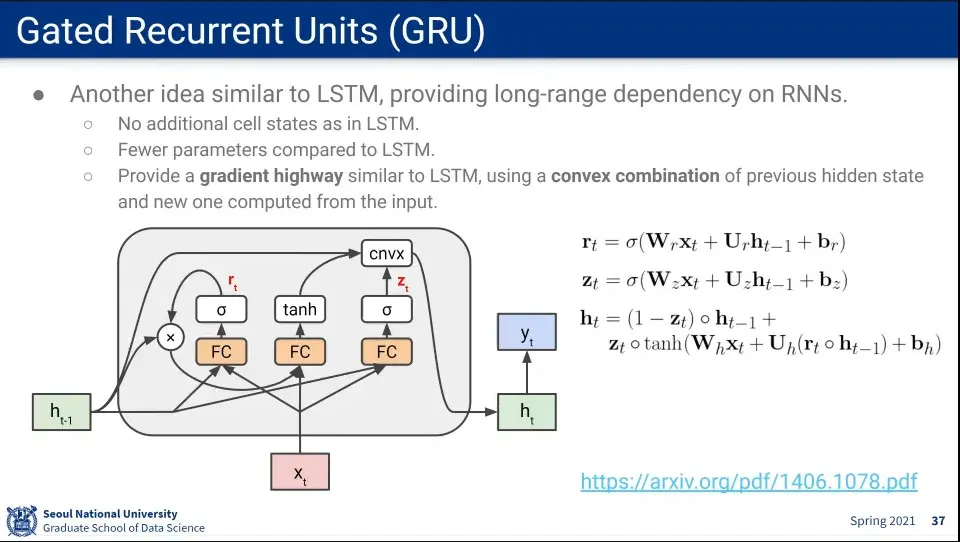
LSTM과 비슷한 GRU 모델이 있다.
◦
GRU는 state는 1개만 유지함.
◦
별도의 state를 유지하지 않고도, 새로운 hidden state에 기존 hidden state와 convex combination 연산을 통해 이전 기억을 유지할 수 있도록 함

•
LSTM과 GRU 코드 예
•
LSTM은 RNN을 할 때 기본 선택으로 사용할 수 있다.
•
파라미터를 줄이고 싶을 때 GRU를 쓸 수 있다.
•
그런데 요즘은 Transformer가 대세임
