•
지금까지는 이미지 분류 문제에 대한 것을 보았음
•
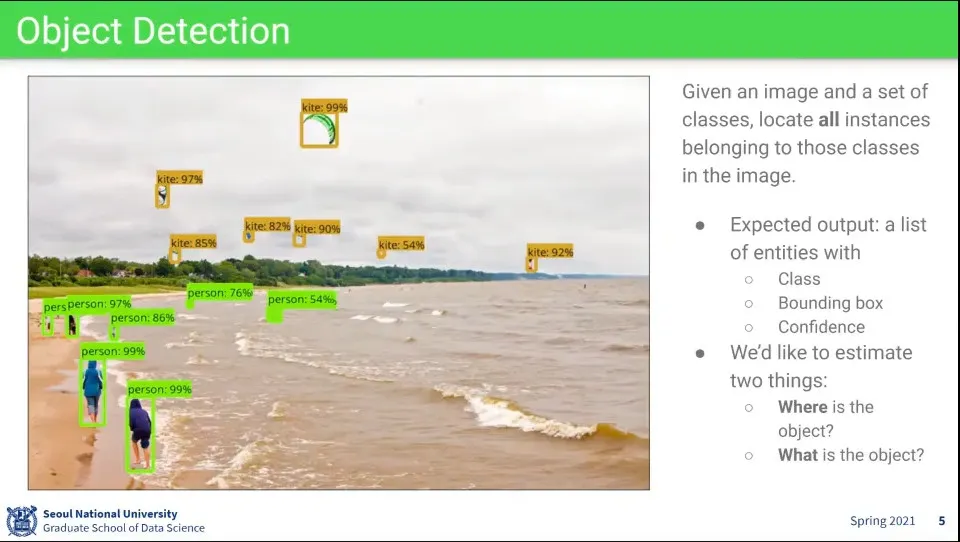
Object Detection은 이미지에 여러 class의 object가 있고, 그게 각각 어디에 있는지를 맞추는 것
•
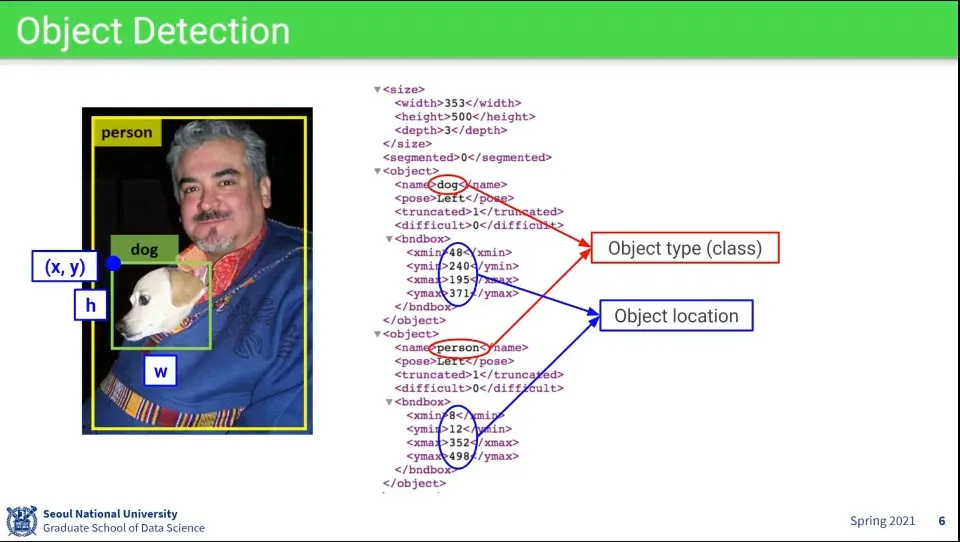
Object Detection의 결과는 다음과 같이 주어진다.
•
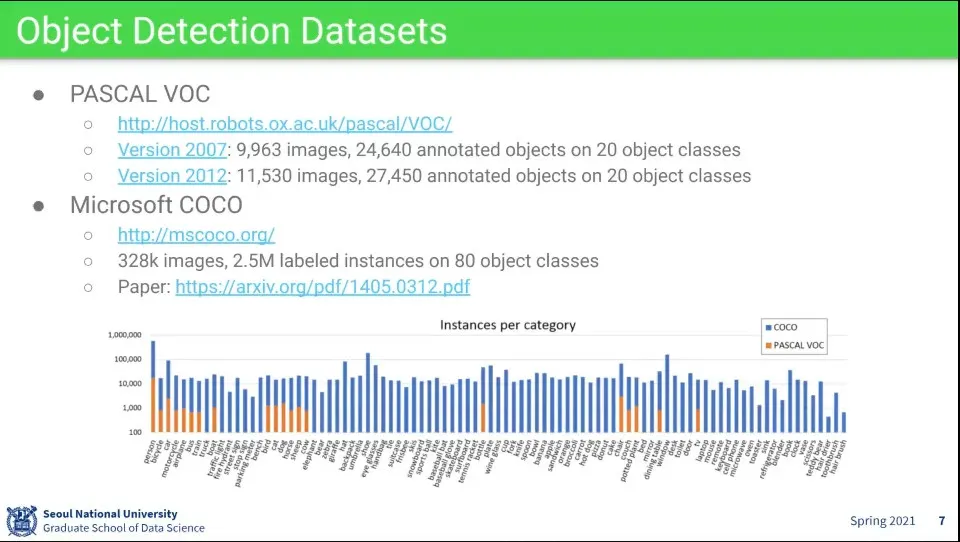
많이 쓰이는 데이터셋
◦
예전에는 Pascal VOC를 많이 썼는데, 요즘에는 MS의 COCO를 많이 씀
•
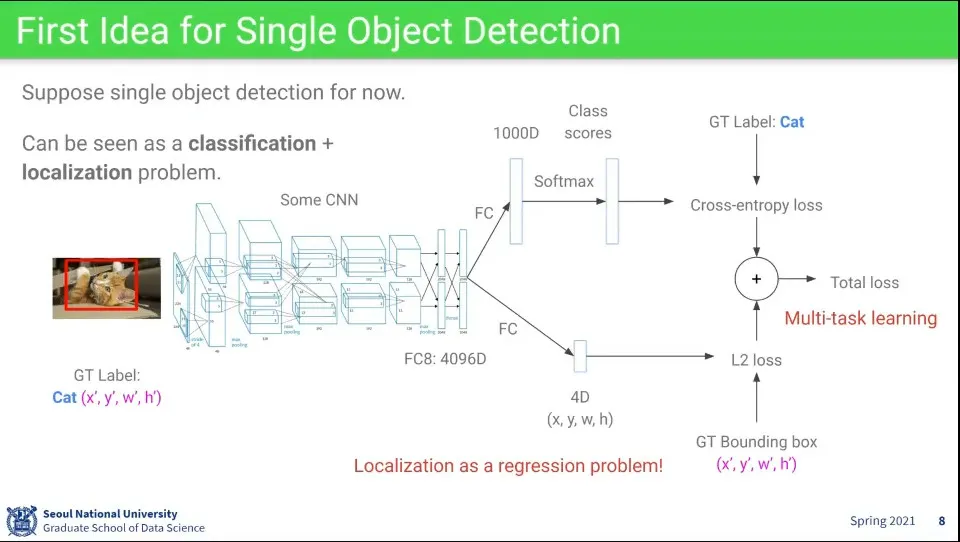
object의 class와 position에 대한 detection 아이디어
◦
레이어의 마지막 부분에 대해 class와 position을 따로 뽑고, 그걸 합해서 최종 loss를 구한다.
▪
clsss에 대해서는 cross-entropy loss를 쓰고, position에 대해서는 L2 loss를 쓴다.
•
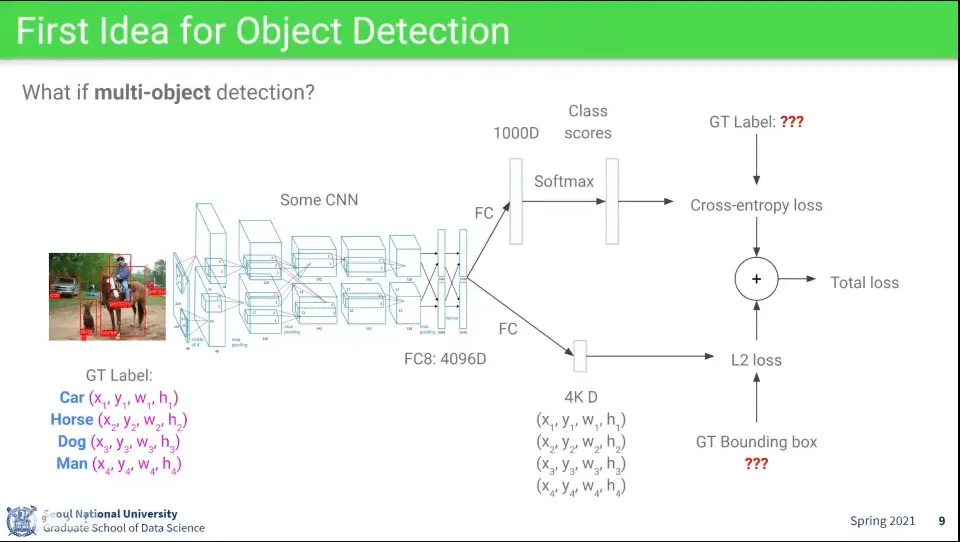
위와 같은 방식으로 하면 이미지 내 여러 object가 있는 경우 처리할 수 없음

•
또 다른 아이디어로는 우선 bounding box를 찾고, 그 bounding box에 대해 classification을 수행
•
그러나 이렇게 하면 너무 많은 비용이 소모 됨

•
그래서 2가지 방법이 제시됨
•
Proposal-based model
◦
후보가 될만한 것들을 먼저 추리고 그것들에 대해 분류를 시도하는 방식
•
Proposal-free model
◦
후보가 될만한 것들을 추리지 않고, 그냥 한 번에 처리하는 방식

•
Proposal-based model의 선구적인 모델
◦
Region의 R이므로 RNN과는 관계가 없다.
•
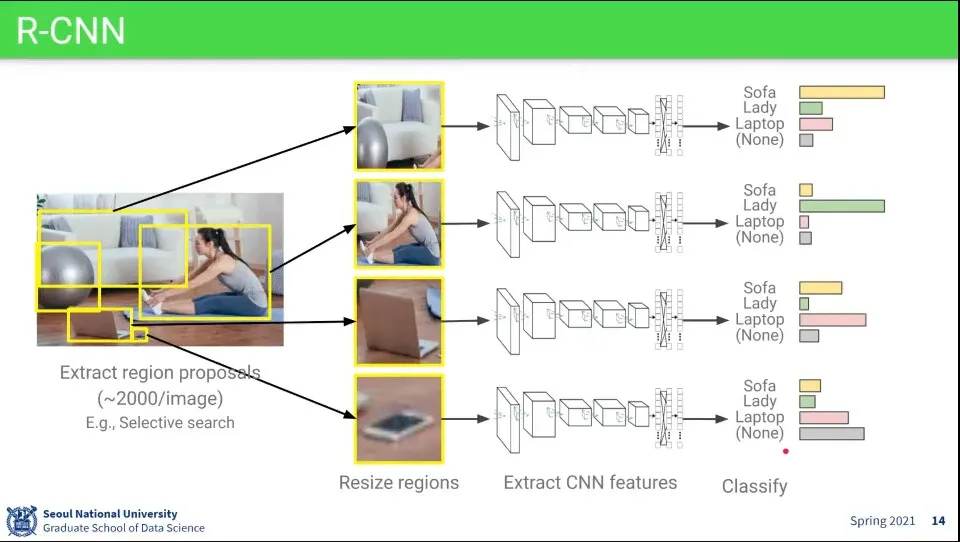
먼저 Region Proposal을 하고
◦
R-CNN의 Region Proposal은 이미 있던 기존 연구를 가져다 씀
◦
이미지 당 대략 2000장 정도를 뽑음
•
그 다음으로 Object를 인식한다.
◦
이 단계는 기존의 이미지 분류와 동일
•
기본 흐름은 위와 같다.
1.
Region Proposal을 통해 bounding box를 찾음
2.
bounding box를 224x224 이미지로 resize
3.
resize한 이미지를 CNN에 넣어서 feature를 뽑고
4.
최종적으로 분류를 함

•
Bounding box를 찾는 것을 학습할 때는 실제 측정된 위치를 그냥 사용하면 뭔가 잘 안되서, 그걸 위와 같이 변형해서 사용한다.
◦
이미지의 좌표를 그대로 안 쓰고, 실제 측정된 위치에 대해 얼마나 차이가 나는지에 대한 offset을 학습 함
◦
는 모델이고 예측하고자 하는 target이
◦
예측하려는 offset 중 x, y는 실제 측정된 x, y와 proposal의 x, y를 빼고, w, h로 나눠서 처리하고 —이러면 비율이 나옴
◦
w, h는 실제 측정된 w, h를 proposal의 w, h로 나눈 후에 log를 씌워서 처리한다.
•
이 방식은 이후 다른 bounding box regression 모델들이 다 따라서 함

•
R-CNN은 처음으로 deep learning을 기반으로 한 image detection
•
하지만 너무 오래 걸려서 요즘은 잘 안 씀
•
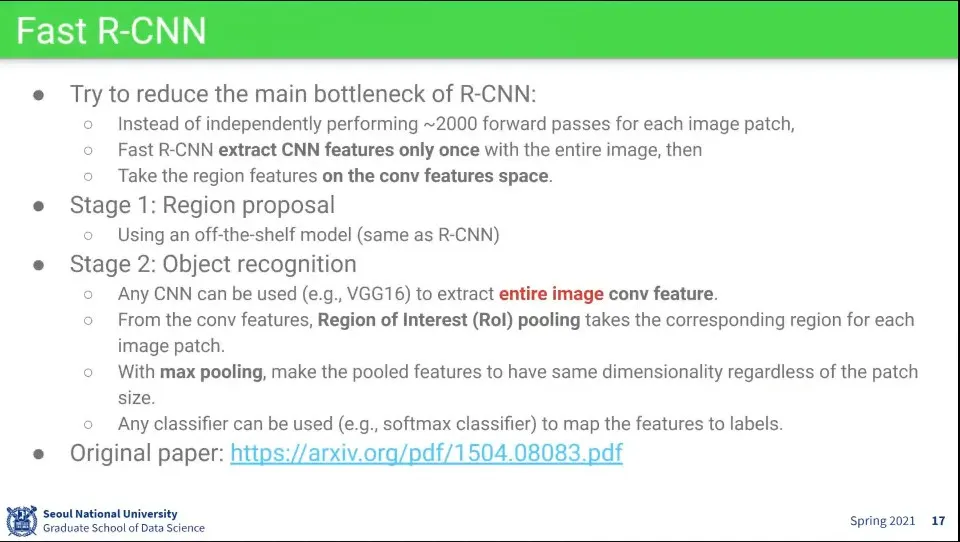
R-CNN이 느려서 나온게 Fast R-CNN
•
R-CNN은 각 proposal 마다 resize를 해서 detection을 하다 보니 이미지당 2000번 inference 하다보니 너무 느림
•
단계는 다음과 같다.
1.
Region Proposal을 한다. - 이거는 R-CNN과 동일
2.
Object 인식을 한다.
•
이때 전체 이미지에 대해 Conv feature는 1번만 뽑음 —모든 이미지에 대해 뽑았던 R-CNN과 달리
•
대신 Region Of Interest(ROI) pooling을 1번만 수행함
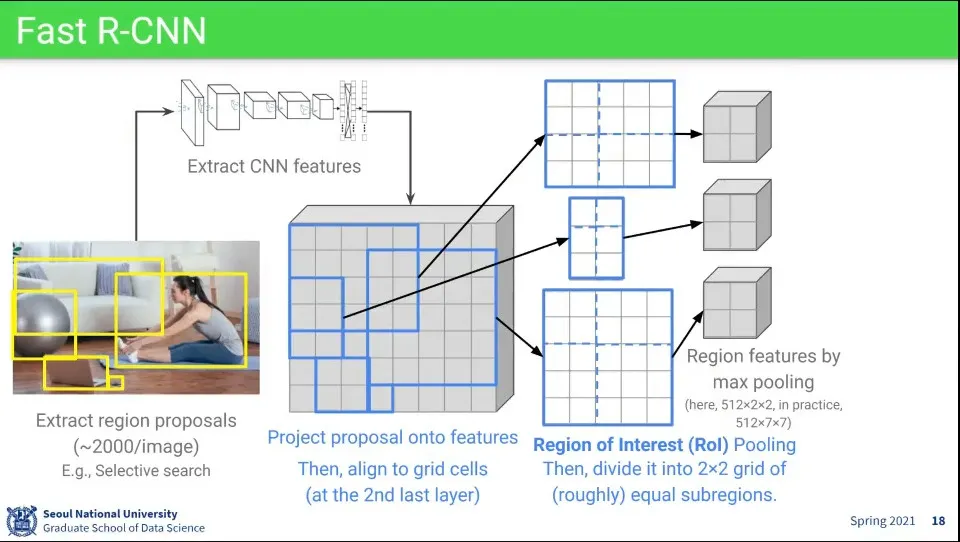
•
순서는 다음과 같다.
1.
일단 Region Proposal을 하고
2.
전체 이미지에 대해 1회 CNN Feature를 뽑음
3.
CNN 레이어의 마지막 부분에 나오는 map에 Region Proposal에서 인식한 bounding box 영역을 mapping 시킴
4.
그렇게 mapping 시킨 영역에 대해 max pooling을 시킴 - 이걸 Region of Interest Pooling이라고 함
•
인식한 bounding box 크기는 다르지만 분류를 위해 같은 사이즈로 pooling 하는 것
•
bounding box의 크기가 pooling 하기 적절하지 않은 크기일 수 있으므로 적당히 사이즈를 잘라서 pooling 한다. 위 이미지에서는 2x2로 만들기 위해 이미지를 적절하게 4등분함
•
위 이미지에서는 512x2x2로 나오지만 512x7x7사이즈로 pooling 함

•
Fast R-CNN은 R-CNN에 비해 빠르고 정확함
•
feature를 1번만 뽑기 때문에 memory 저장 공간을 절약할 수도 있다.

•
Fast R-CNN도 느려서 그걸 개선한게 Mask R-CNN
◦
자세한 내용은 segmentation 부분에서 다시 설명

•
Region proposal을 기존 것을 사용하지 않고 새로운 아이디어를 적용한게 Faster R-CNN
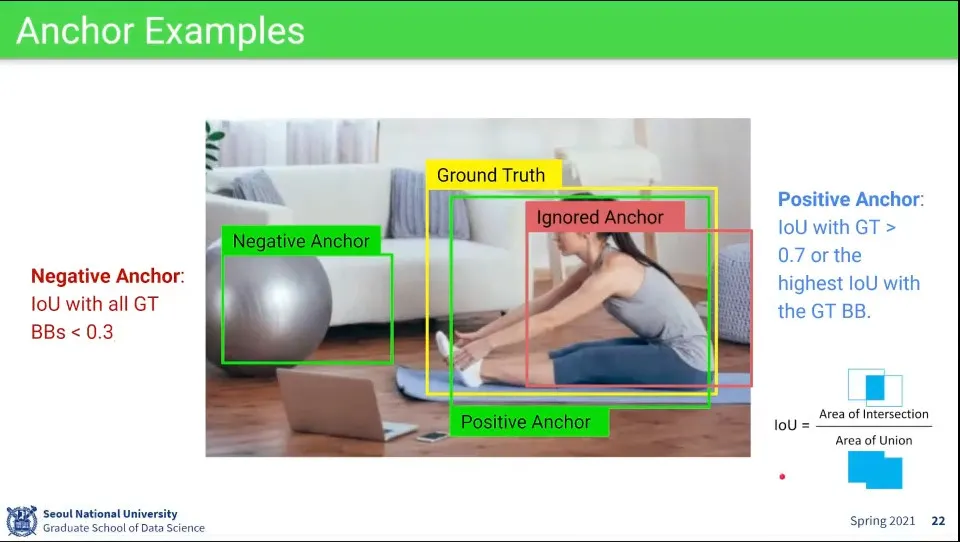
•
측정된 것에 대해 IoU가 0.7 이상인 것들을 positive anchor로 설정함
•
마찬가지로 IoU가 0.3 이하인 것을 negative anchor로 설정함
•
그 사이의 값들은 어정쩡하므로 무시함
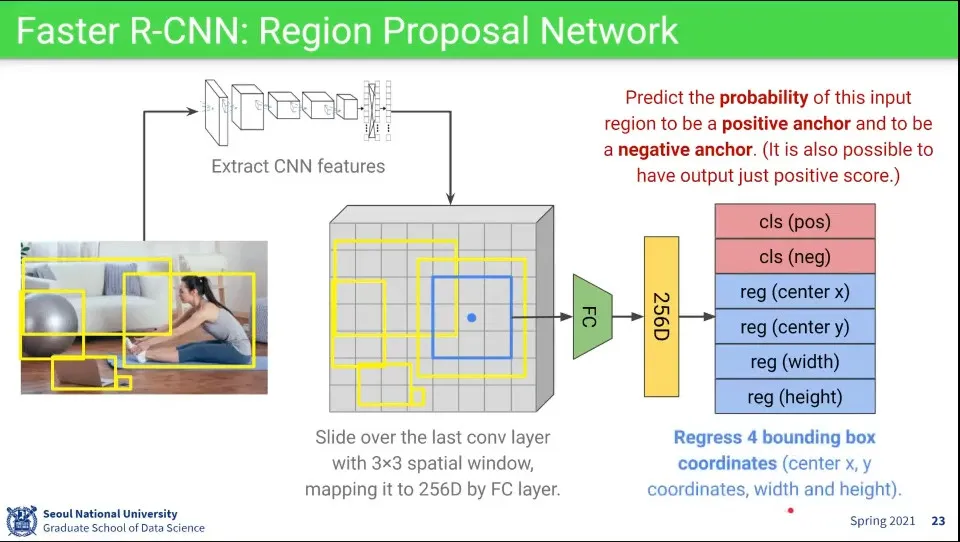
•
앞서와 마찬가지로 진행
1.
일단 Region Proposal을 하고
2.
전체 이미지에 대해 1회 CNN Feature를 뽑음
3.
CNN 레이어의 마지막 부분에 나오는 map에 Region Proposal에서 인식한 bounding box 영역을 mapping 시킴
4.
거기에 3x3 크기로 slide 하면서 이미지에 대해 positive anchor, negative anchor일 확률을 예측하고, x, y, w, h를 찾는다.
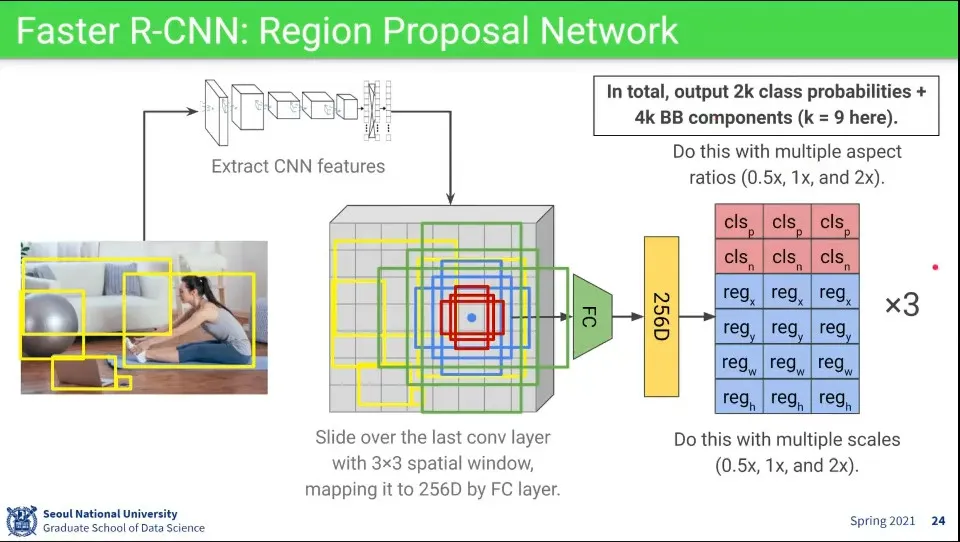
•
이때 object의 크기가 정사각형이 아니기 때문에, 비율와 크기를 바꿔가면서 학습을 함
◦
한 자리에서 비율과 크기가 다른 것을 각각 적용해서 총 9번 돈다.

•
Region Proposal Network를 구성하기 위해 classify와 bounding box regression에 대해 별도의 loss를 구한 것을 합하여 사용한다.
◦
이때 positive anchor냐 negative anchor냐도 함께 넣어줘서 loss를 계산한다.
•
실제 사용할 때는 positive가 128개 미만일 때는 positive를 다 쓰고, positive가 128개가 넘으면 positive를 128개만 쓰고 나머지는 negative로 채워서 학습하면 positive:negative 비율이 1:1이 나와서 학습이 잘 된다고 함

•
학습 과정은 총 4단계로 구성됨
1.
처음에는 Region Proposal Network만 학습함
2.
다음으로 1단계에서 학습된 conv layer를 초기화하고 이번에는 Classfier만 학습 함
3.
1, 2 단계를 통해 만들어진 2개의 layer를 합쳐서 RPN을 fine-tuning 함
4.
그 후에 마지막으로 classifier를 다시 fine-tuning 함
•
요즘에는 이렇게 안 하고 그냥 end-to-end로 함
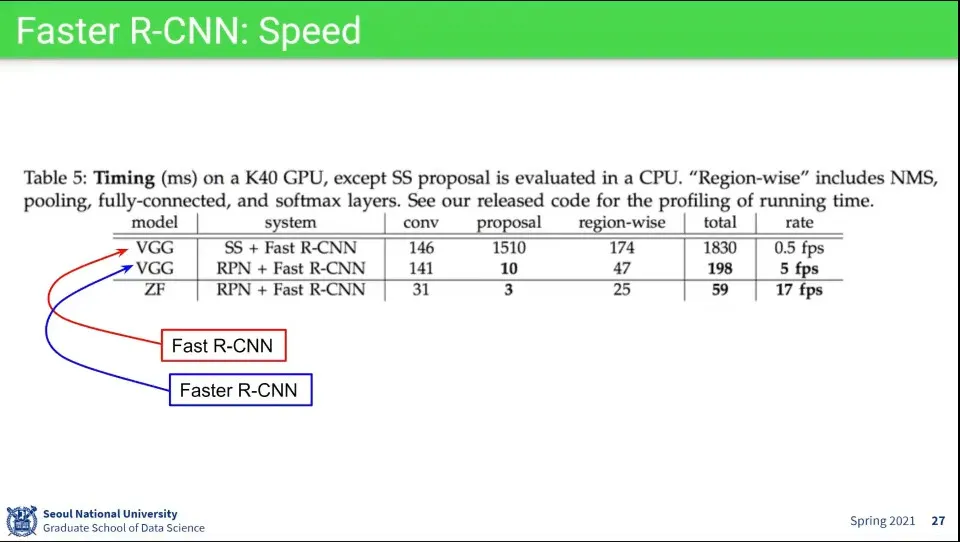
•
Fast R-CNN보다 Faster R-CNN에서 proposal 단계 속도가 150배 빨라짐. 전체에 대해 10배 빨라졌다고 함
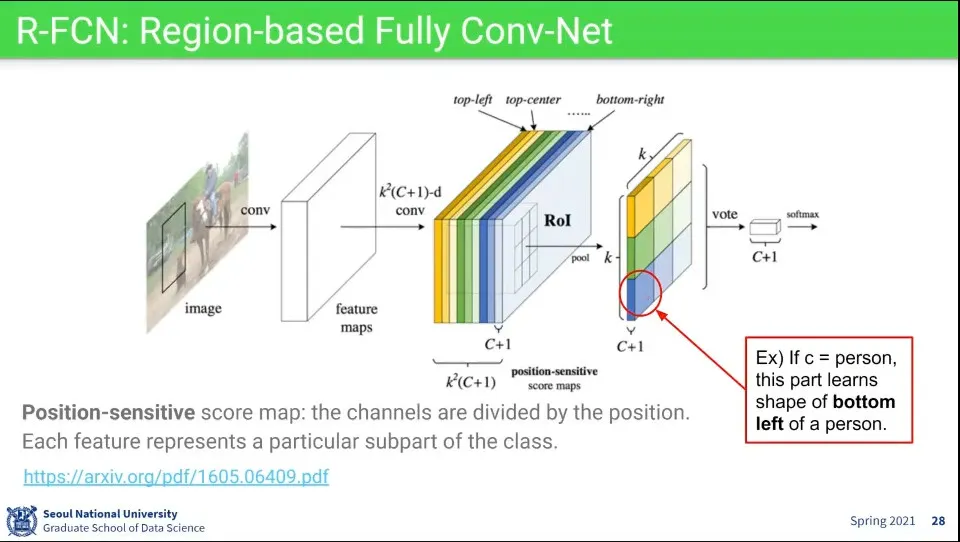
•
Object를 Detection 할 때 아예 구역별로 feature를 다르게 인식할 수 있도록 함
◦
예컨대 가장 오른쪽 이미지의 동그란 부분에 대해 사람의 왼쪽 아래에 해당하는 feature를 갖고 있고, 그 위의 노란색은 사람의 왼쪽 위에 해당하는 feature를 갖고 있다면, —나머지 부분도 그 구역에 맞는 feature를 가지고 있음— 그 feature 들에 대응되는 것을 찾으면 거기가 찾고자 하는 object가 위치하는 곳이 된다.
◦
이때 사람의 왼쪽 아래 (이미지상 파란 박스)는 그 앞단의 레이어에서 파란색 channel이 되고, 왼쪽 위 (이미지상 노란 박스)는 그 앞단 레이어에서 노란색 channel이 된다.
•
이렇게 위치별로 feature를 구분해서 처리하기 때문에 Position-sensitive score map이라고 한다.


•
그런 위치별 feature가 적용된 map을 이미지 상에서 slide 하면서 object를 찾음
◦
(이러면 물체가 회전된 것에 약하지 않을까? 사람인 경우 자세가 바뀌는 것도 문제가 됨)

•
Proposal based의 최신 논문들

•
YOLO는 Detection을 한 번에 하는 컨셉
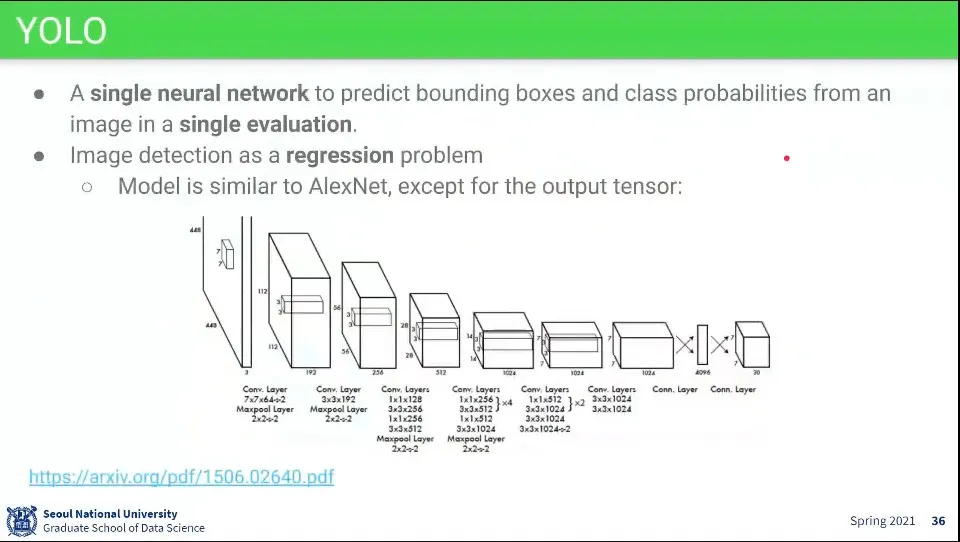
•
YOLO의 모델은 AlexNet과 유사하다.
•
YOLO는 Classifier와 Bounding box 찾는 것을 모두 regression 문제로 해결함

•
Input 이미지가 들어오면 SxS 크기로 쪼갬 (만든 사람들은 7x7로 함)
◦
그렇게 쪼개진 크기에 대해 그 중심에 있는 애가 Object를 Detection 해야 하는 임무가 주어짐
•
그 중심에 대해 인식해야 하는 object가 2개를 넘지는 않을 것이다라는 가정
◦
위 이미지상 쪼개진 grid의 중심에 엄마와 아기 2개까지 있는 거고, 그 이상 중심이 겹치는 object는 찾기 어려움
◦
각각의 bouding box는 5개의 결과를 예측함. x, y, w, h, confidence
◦
confidence는 object와 IoU를 이용해서 계산함
•
각 Grid Cell은 class score를 예측함
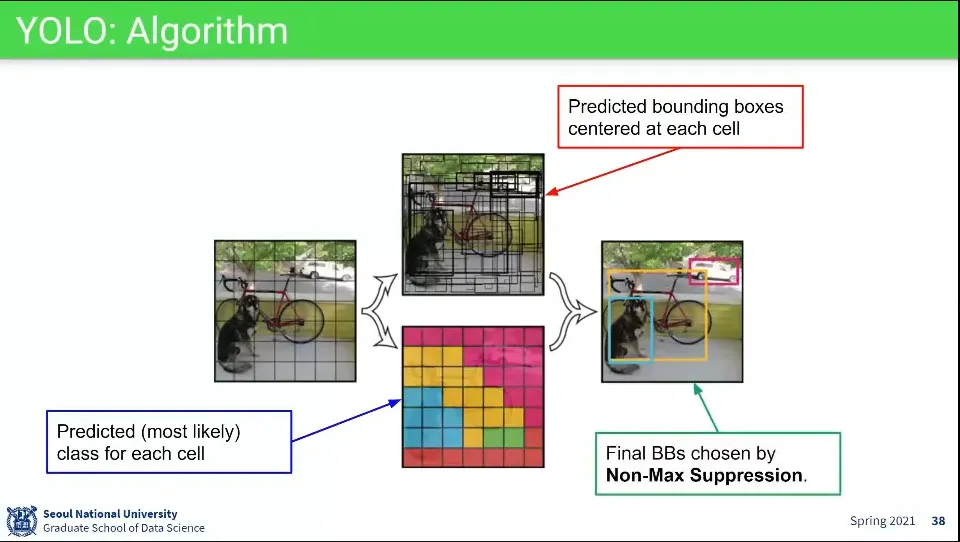
1.
이미지를 7x7로 쪼갬
2.
각 칸이 중심이 되도록 예측하여 bounding box를 그림 (가운데 위 그림)
3.
각 칸이 어떤 클래스에 들어가는지 예측함 (가운데 아래 그림)
4.
2, 3의 결과를 이용해서 Non-Max Suppression을 이용해서 최종 object의 bouding box를 처리함

•
Non-Max Suppression 알고리즘
1.
box 중에서 가장 높은 스코어를 취함
2.
1단계에서 구한 box와 IoU가 겹치는 것들을 구함
3.
겹치는 것들 중에 IoU가 50%가 넘는 것들은 버림
4.
그 다음 점수가 높은 box를 찾음
5.
2-4단계를 반복함
•
(같은 클래스를 이용하지 않는 것은 실제로 사람이 겹쳐 있거나 하는 경우가 있기 때문인 거 같다.)
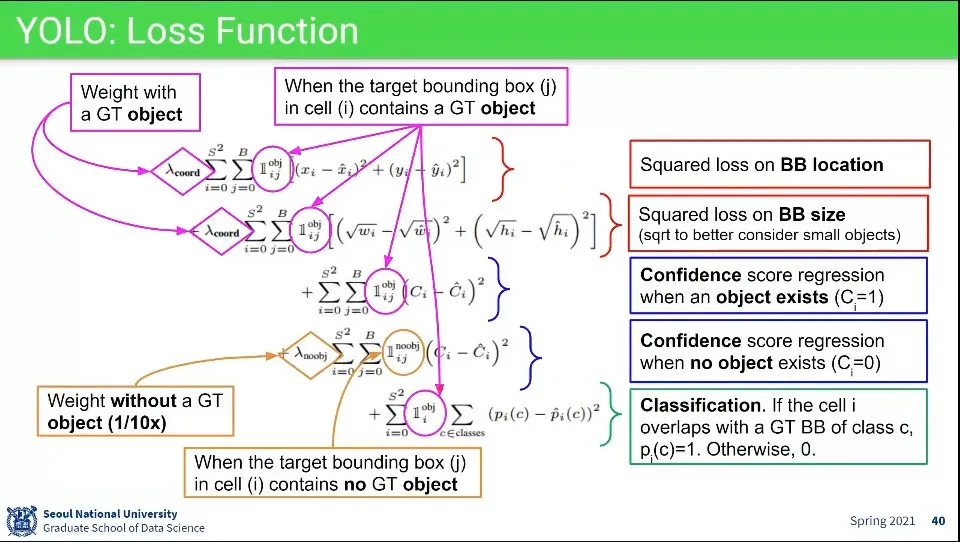
•
위치 잡는거랑 class 잡는 거를 하나의 loss 함수에 때려 박음
◦
notation이 수학적으로 엄밀하지는 않음
•
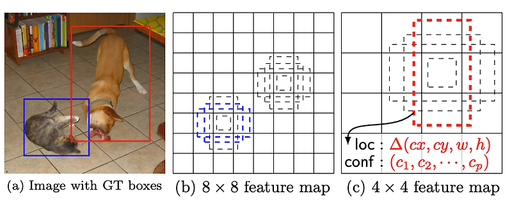
가장 윗줄은 x, y에 대한 것이고, 그 아래는 w, h에 대한 것
◦
w, h에 루트가 씌워져 있는데, 이것은 작은 오브젝트를 놓치지 않기 위한 방법
•
그 아래 2줄은 있는 것과 없는 것에 대한 confidence이고
◦
기본적으로 물체는 없는 경우가 더 많기 때문에 모든 cell이 없다고 report하면 정확도가 90%가 나온다. 이걸 방지하기 위해 있는 경우 가중치를 더주고 없는 경우에는 있는 경우의 1/10 정도의 가중치만 줌
•
맨 아래는 classfication에 대한 것
•
Proposal이 없는 대신 자리마다 2개씩만 있을 수 있다는 가정으로 처리 함

•
YOLO는 Realtime이 가능하면서 정확도도 높음
◦
Faster R-CNN보다 정확도는 조금 떨어짐
•
틀리는 것들에 대해
◦
Fast R-CNN은 background를 많이 틀리는데 이것은 False-Positive 문제
◦
YOLO는 있는 것은 잘 맞추는 대신 Localization을 많이 틀림
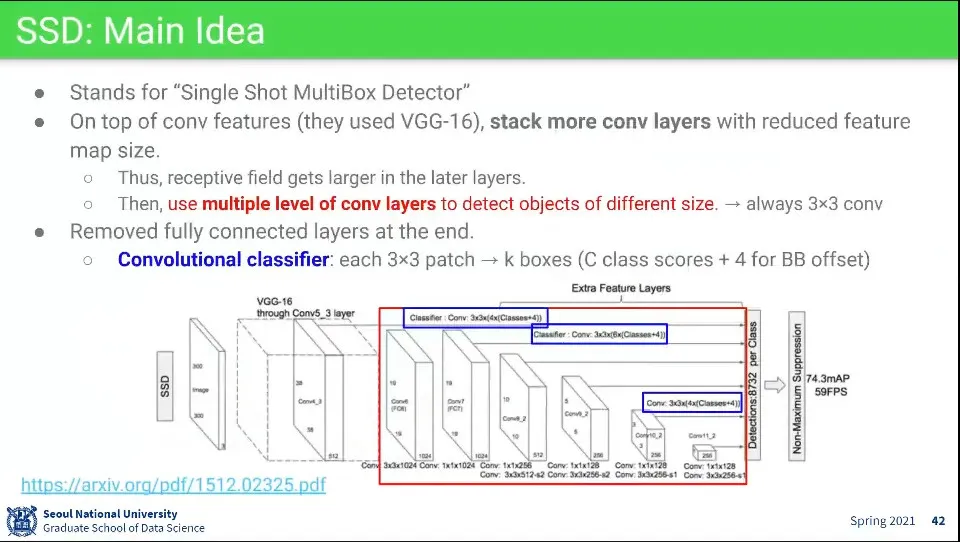
•
SSD도 YOLO처럼 한 번에 object를 찾는 방식
•
레이어 앞부분에는 VGG를 사용함
◦
VGG의 5x3 레이어를 다음에 3x3 레이어를 계속 넣어서 이미지를 1x1까지 줄임

•
3x3를 이용해서 classification과 bouding box를 찾는데, 그걸 매 단계에서 수행한다.
•
덕분에 layer 앞부분에서는 작은 물체를 찾고, layer 뒷부분에서는 큰 물체를 찾는다.
◦
layer 앞부분은 이미지가 큰데 (38x38) 거기서 3x3을 찾으니 상대적으로 작은 물체를 찾고
◦
뒷 부분은 이미지가 작아져 있는 상태에서 3x3을 찾으니 상대적으로 큰 물체를 찾게 됨
•
최종적으로는 그렇게 찾은 모든 object를 합쳐서 Non-Max Suppression을 해서 물체를 한 번에 찾아냄

•
SSD의 Loss 함수는 이와 같다.
◦
YOLO와 마찬가지로 location과 classfication을 하나의 loss 함수에 넣음. 각 loss의 상세 내용은 그 아래 나옴.
•
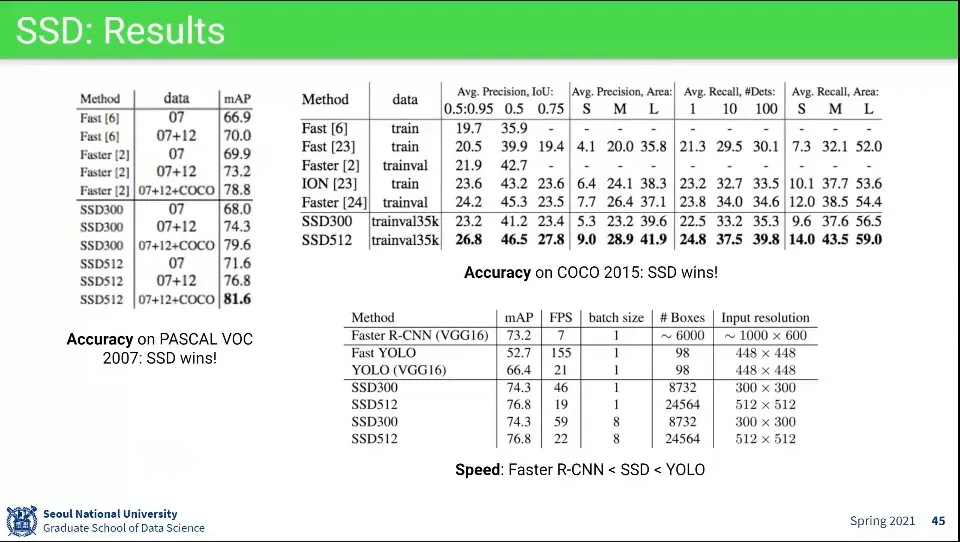
SSD는 Faster R-CNN보다 정확도가 높음. 대신 YOLO 보다 느림
◦
SSD 300이면 Realtime이 가능함

•
Proposal Free 방식의 최근 논문들
•
(개인적으로 신기했던 점은 아예 Bounding Box 자체도 학습을 시켜버린다는 것. 후처리를 통해 알아내는게 아니라 아예 Loss를 적용시켜서 학습을 해버림)