

•
정지된 이미지를 처리하기 위해 2d conv를 썼던 것처럼, video를 처리하기 위해 3d conv를 사용할 수 있다.
•
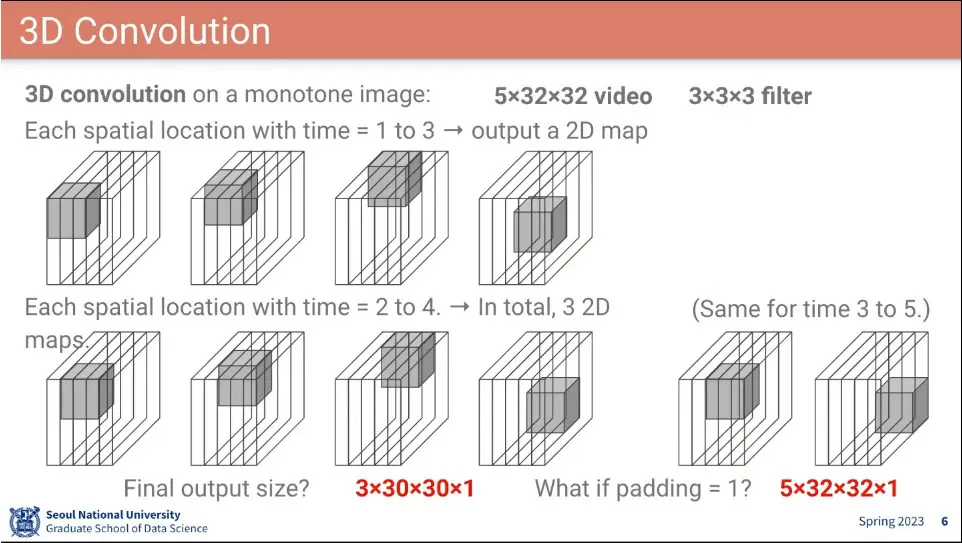
기존의 2d 이미지에 더해 시간 단위로 이미지를 여러 장 묶어서 conv를 돌린다.
◦
padding을 추가하면 input-output의 크기를 같게 맞출 수 있음

•
추가로 채널이 추가되기 때문에 최종적으로 3d conv의 filter는 총 4개의 차원을 갖는다. (seq, height, width, channel) 순서는 정하는 곳마다 다름.
•
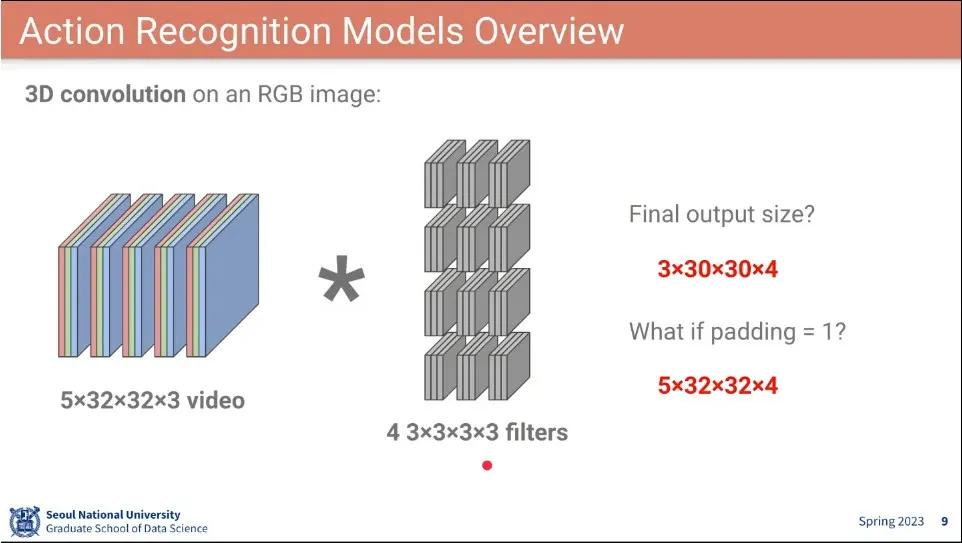
3d conv 크기 계산 예
◦
padding을 정수를 주면 시간, 공간에 모두 같은 값이 적용되고, (1, 0, 0) 처럼 주면 시간에만 1을 주는 식으로 설정된다.
•
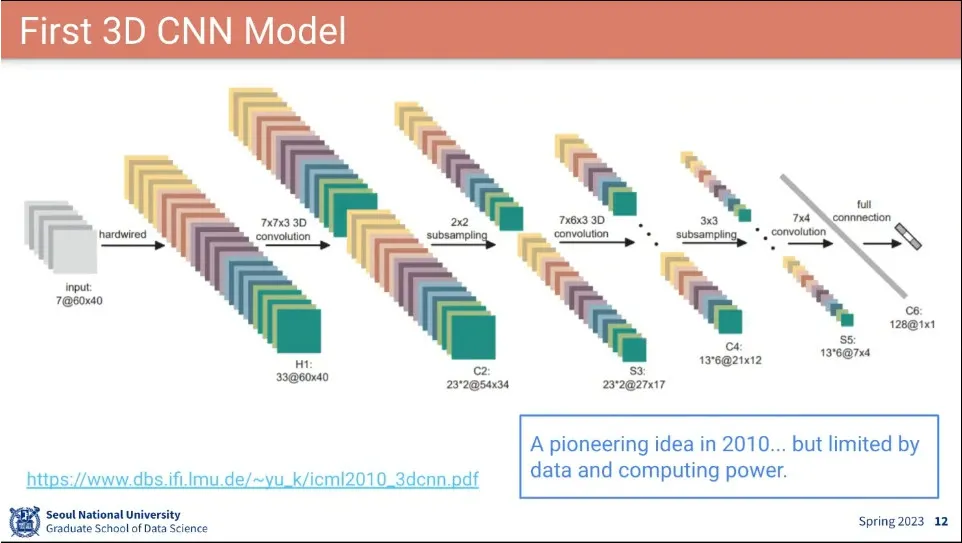
3D CNN 모델 아키텍쳐
◦
알렉스 넷이 등장하기 전에 했던 시도. 당시 컴퓨팅 파워의 한계로 주목 못 받고 잊혀짐


•
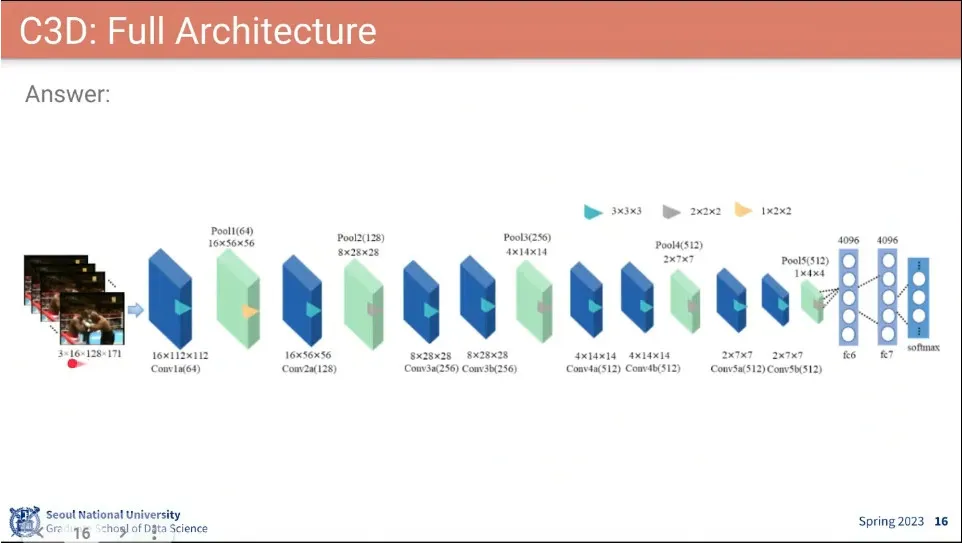
C3D (Convolutional 3D) 아키텍쳐
◦
알렉스넷과 비슷한 구조로 만듦.

•
짧은 액션만 가능하고 긴 영상은 처리가 어려움.
◦
3개 frame 씩 conv를 돌리면 그 상위 layer는 5개, 그 상위 레이어는 7개 frame을 볼 수 있는데, 30fps 영상만 되더라도 1초에 30개의 이미지가 있기 때문에 layer를 어지간히 쌓지 않고서는 특징을 찾기 어려움.
•
계산량이 많음.

•
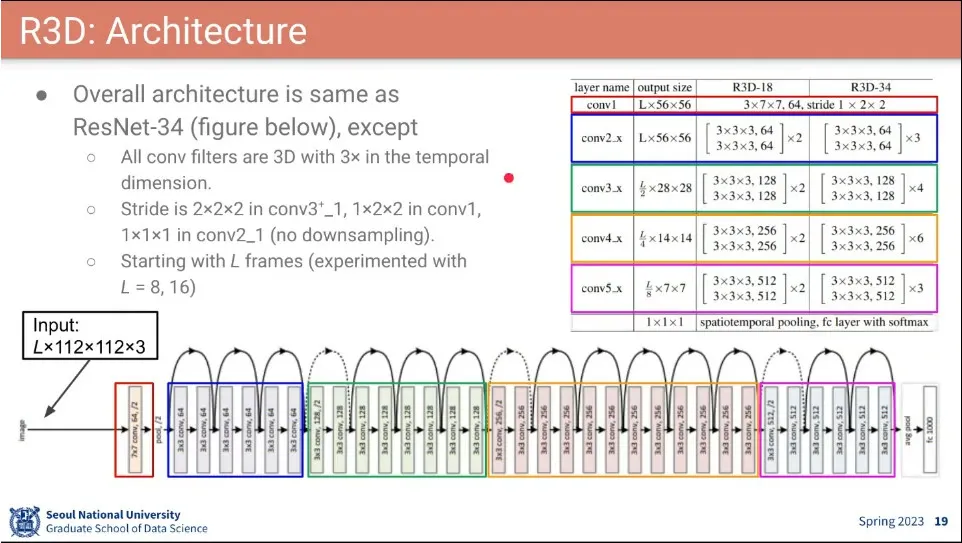
이번에는 Resnet을 이용한 R3D 모델이 나옴
•
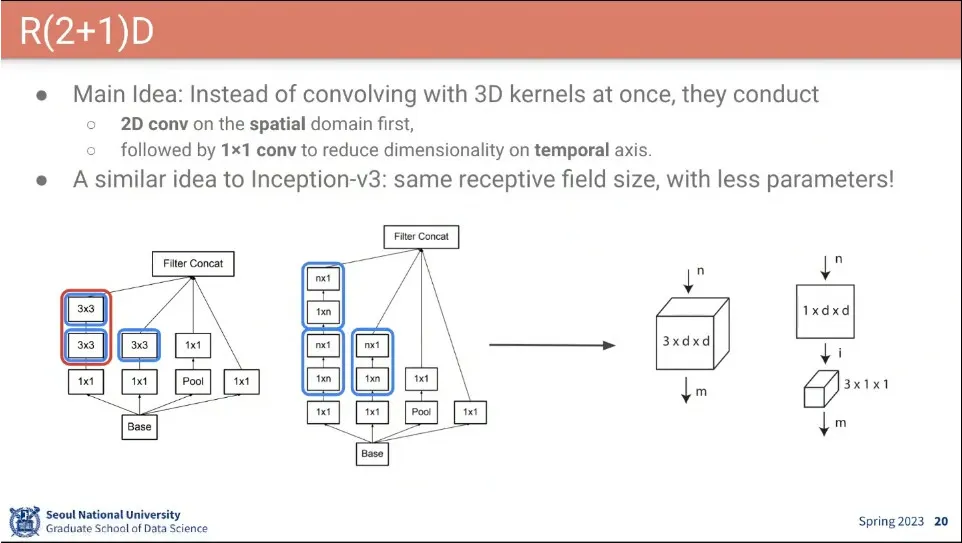
R3D를 개선한 R(2+1)D 모델이 나옴.
◦
Inception의 방식을 차용
•
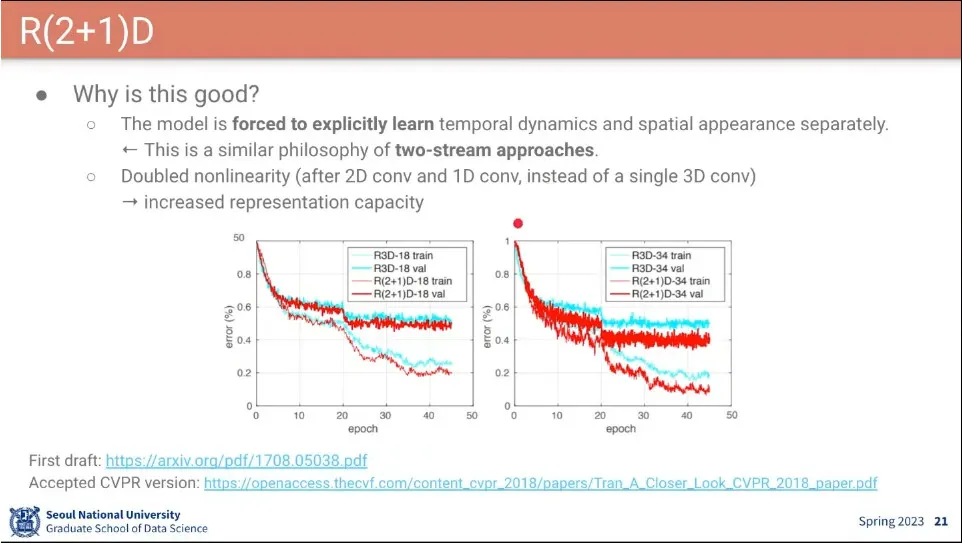
R3D 보다 R(2+1)D가 좀 더 성능이 좋았다.
•
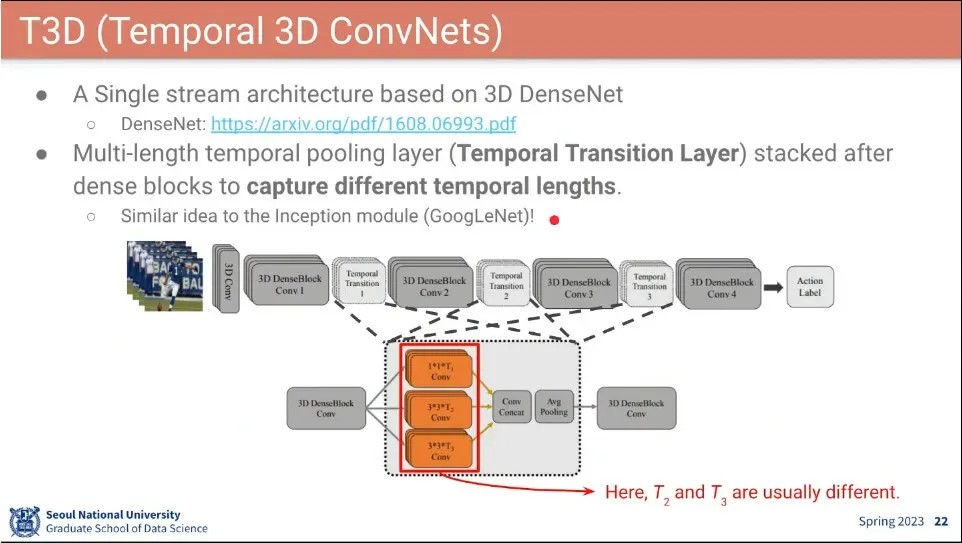
3D DenseNet을 차용해서 만든 T3D 모델
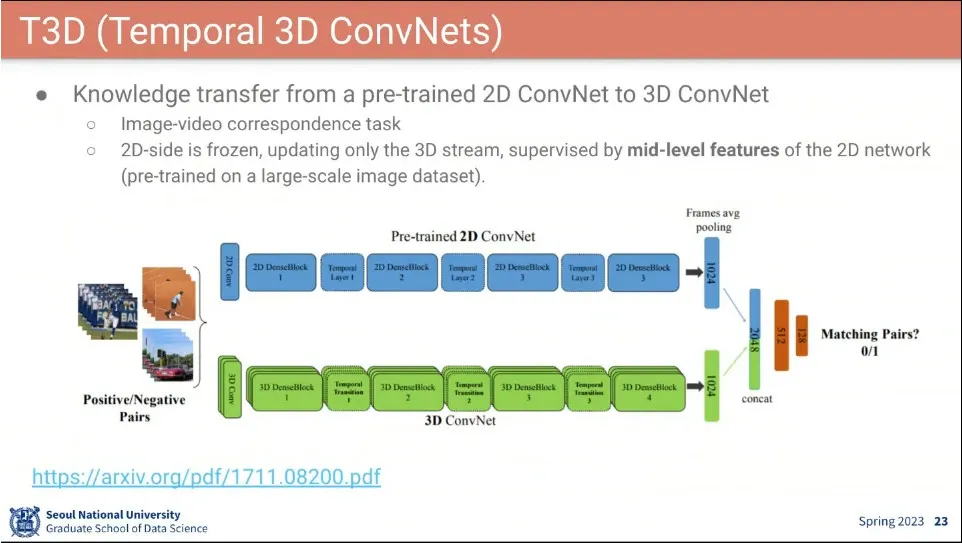
•
필요한 학습 데이터셋은 Video가 더 많이 필요한데, 실제 데이터는 이미지 데이터가 많음.
◦
그래서 2D 이미지에서 배워 놓은 것과 loss가 같아지도록 학습 시킴.
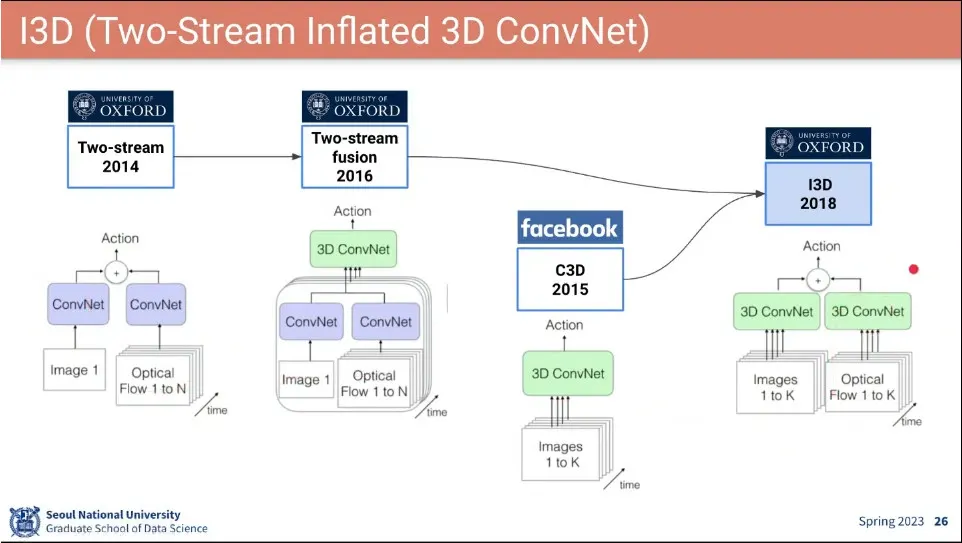

•
I3D는 Two-stream과 C3D를 결합하여 만들어진 모델. 성능이 좋아서 이후에 많이 쓰임.
◦
Two-stream 구조를 가져가는데, 공간정보를 3D ConvNet을 쓰고, Optical Flow에도 3D Conv Net을 씀.
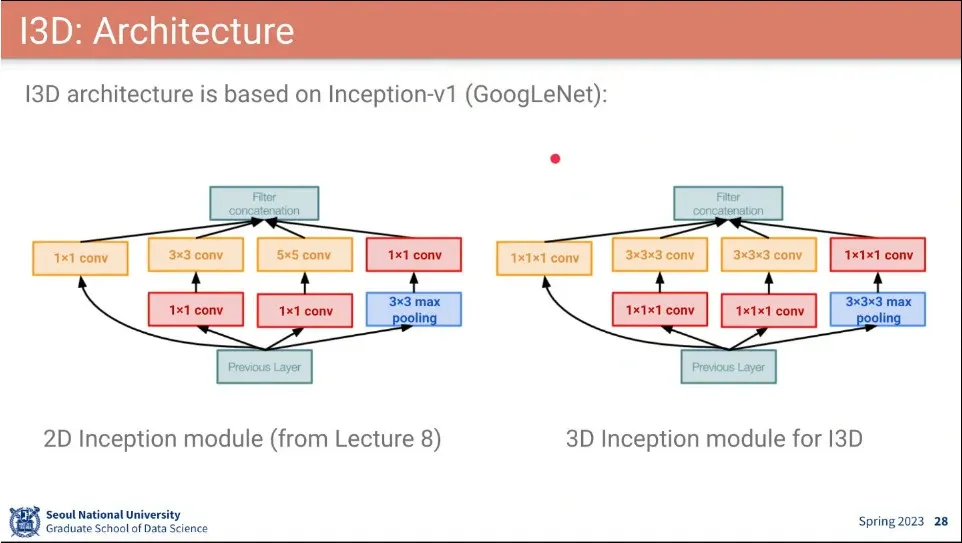
•
Backbone에 Inception을 3차원으로 확장해서 씀.
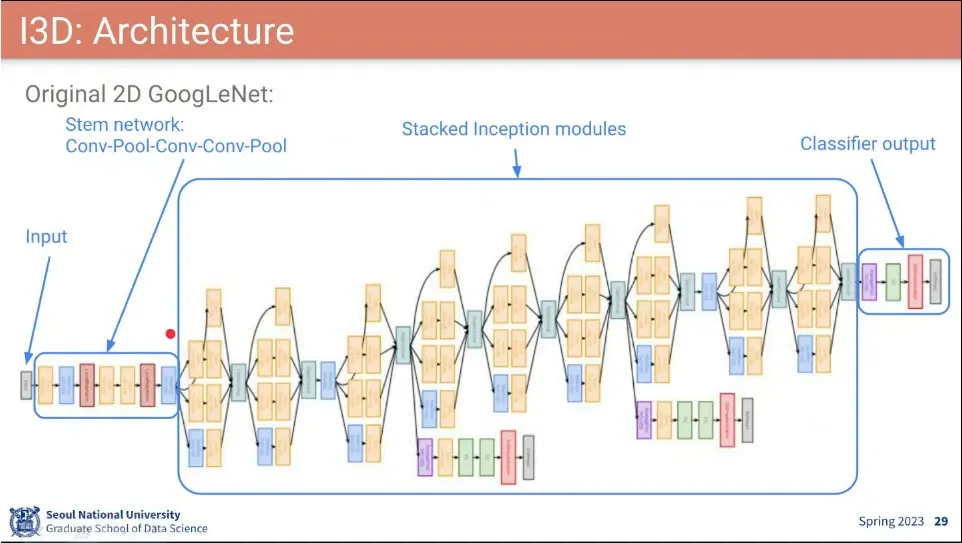
•
I3D 아키텍쳐
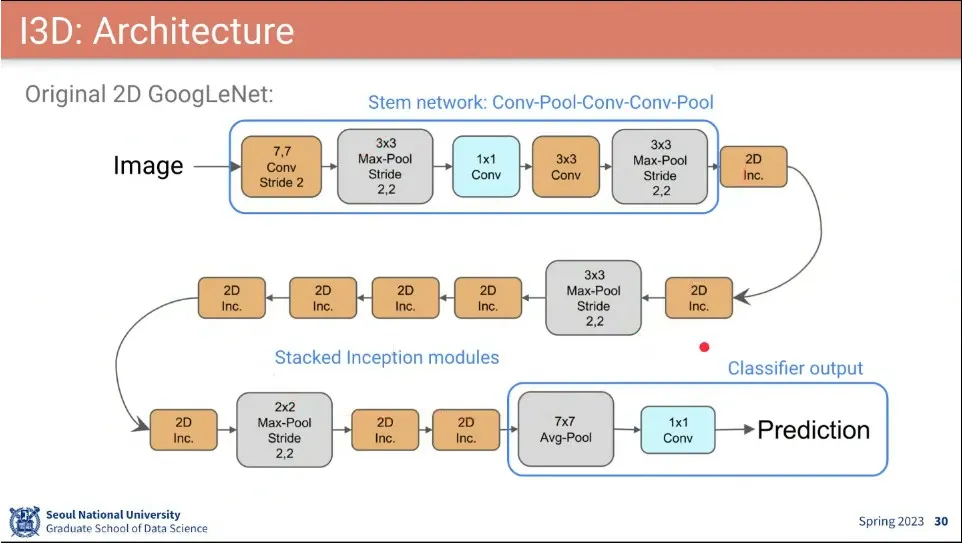
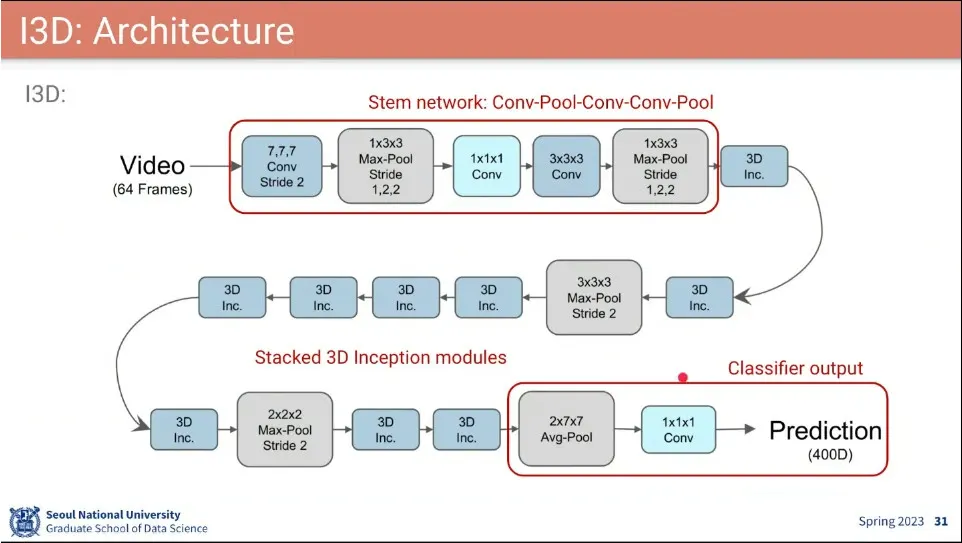
•
오리지널 GoogLeNet에 대해 변경된 부분.

•
3D Conv만으로는 Optical Flow 보다 성능이 안나와서 Optical Flow를 써야 성능이 좋아짐.
◦
아마도 optical flow에서 recurrent 한 특성을 배우기 때문인 것 같다는 추측을 함.
•
그런데 그 후에 나온 모델은 optical flow 없이 좋은 성능을 내서 optical flow는 이 논문 이후로 안 쓰임
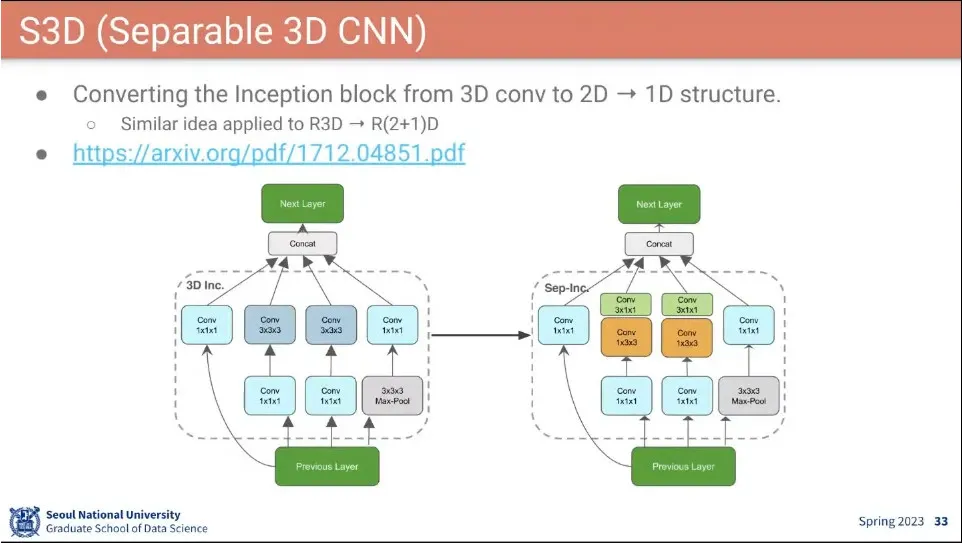
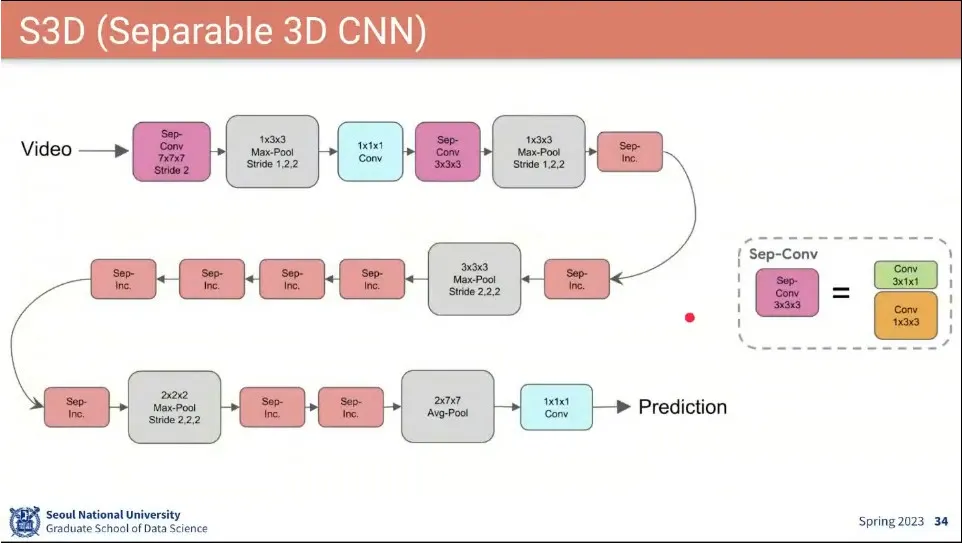
•
I3D랑 비슷한데 Inception에 Conv 부분을 변경한 S3D 모델이 나옴.
◦
Conv 3x3x3을 Conv3x1x1과 Conv1x3x3으로 분리
◦
I3D에 대해 모델이 가벼워지고 속도도 빨라지고 성능도 더 좋아짐. 그래서 이후에 I3D 대체 함.
◦
그래서 I3D를 대체함.
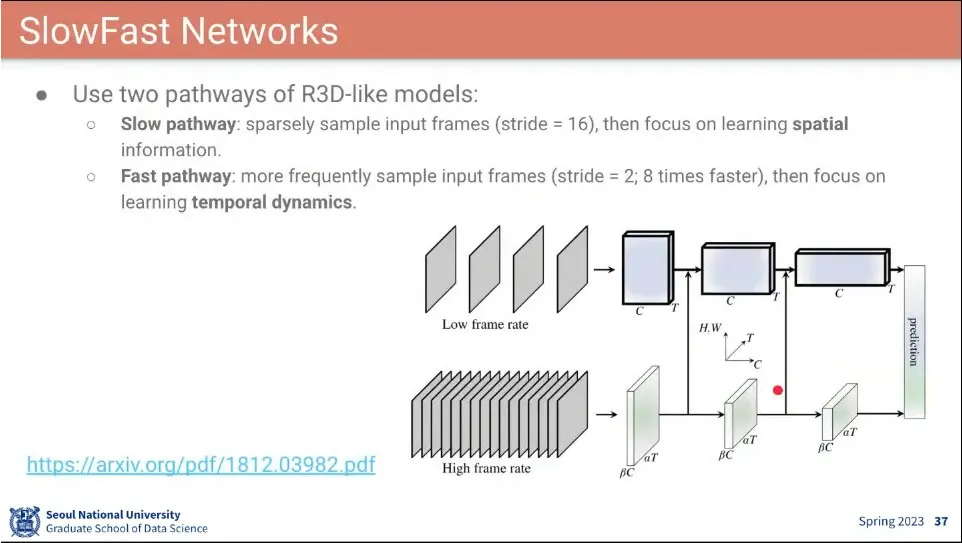
•
Optical Flow를 없애고 비슷한 효과를 내는 것을 목표로 함.
◦
Slow Pathway, Fast Pathway를 나눠서 처리
◦
Slow Pathway는 stride를 적용해서 frame을 띄엄 띄엄 가져와서 공간적인 부분에만 초점을 맞춤.
◦
Fast Pathway는 2장에 한 장씩 뽑아서 action 정보를 추출하는데 초점을 맞춤. 대신 채널의 개수를 줄여서 slow pathway와 계산량이 비슷해지도록 맞춤
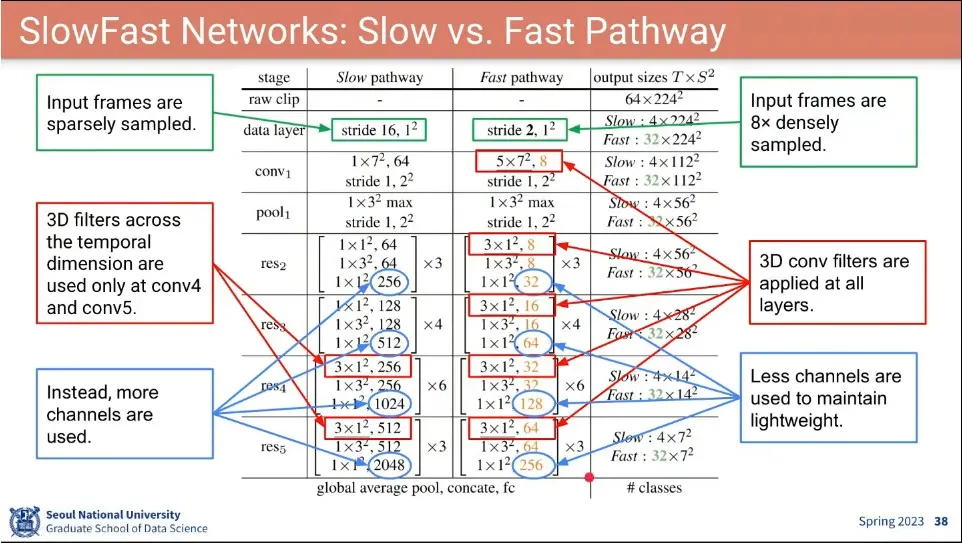
•
모델 상세

•
slow pathway, fast pathway가 각각 학습한 피처를 다른 path에서도 사용할 수 있게 Lateral connection을 추가함.
◦
feature를 합치려면 dimension이 같아야 하기 때문에 크기를 맞춰 줌.
◦
공간적으로는 크기를 맞출 수 있는데, 시간적으로는 channel을 맞출 수 없어서, stack해서 넣거나 sampling만 하거나 하는 방법을 사용 함.
◦
그런데 fast에서 slow로 가는 것만 도움이 되고 반대는 별 도움 안 되었다고 함.
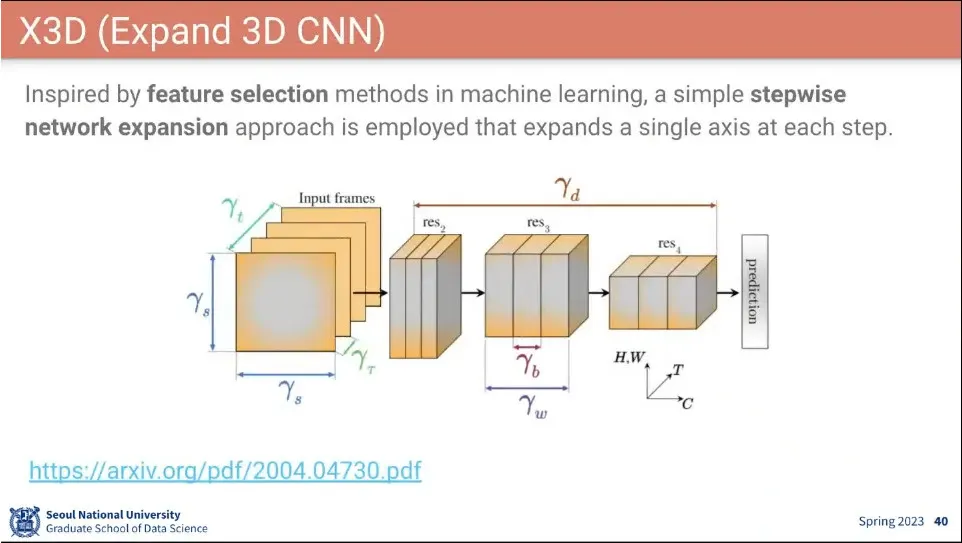
•
모델 아키텍쳐만 설계하고 적절한 하이퍼파라미터를 찾는 노가다를 함.

•
X-Fast, X-Temporal, X-Spatial, X-Depth, X-Width, X-Bottleneck 총 6개의 파라미터에 대한 적당한 값을 실험으로 찾음.
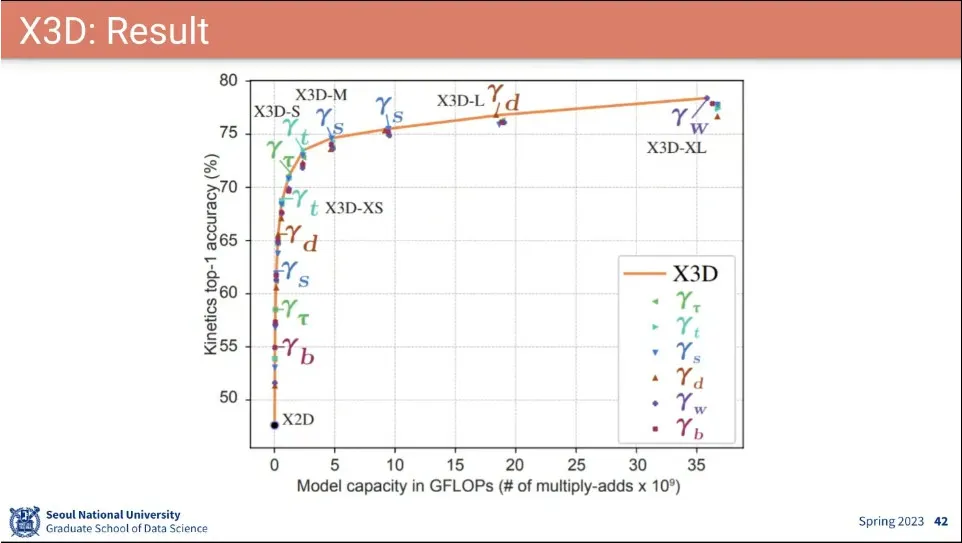
•
파라미터를 아주 작은 값에서 시작해서 조금씩 늘려가며서 좋은 성능을 찾아냄. 이걸 Auto ML이라고 함.
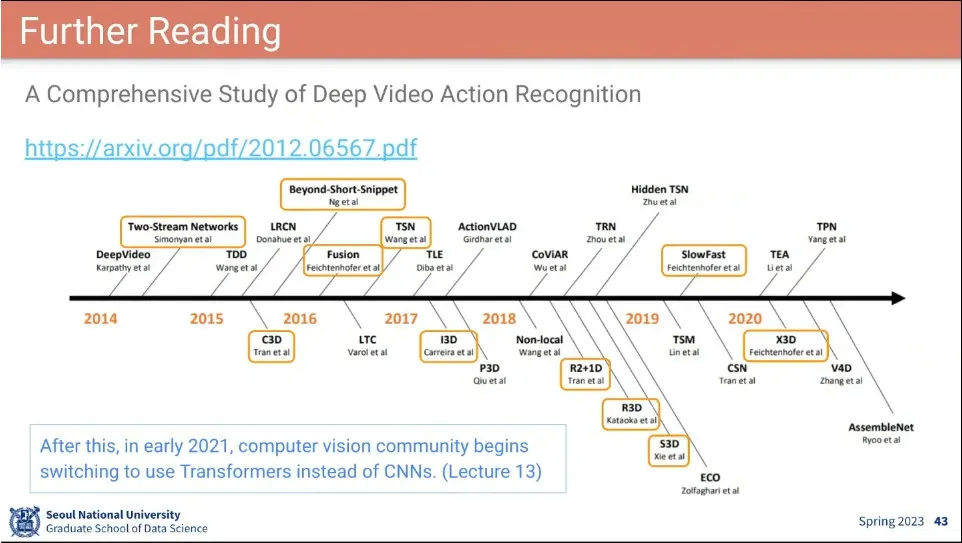
•
그전까지는 CNN 기반으로 모델이 발달해 왔는데, 2021년에 Transformer를 이용한 ViT가 나오면서 Transformer가 주류가 됨.
