
•
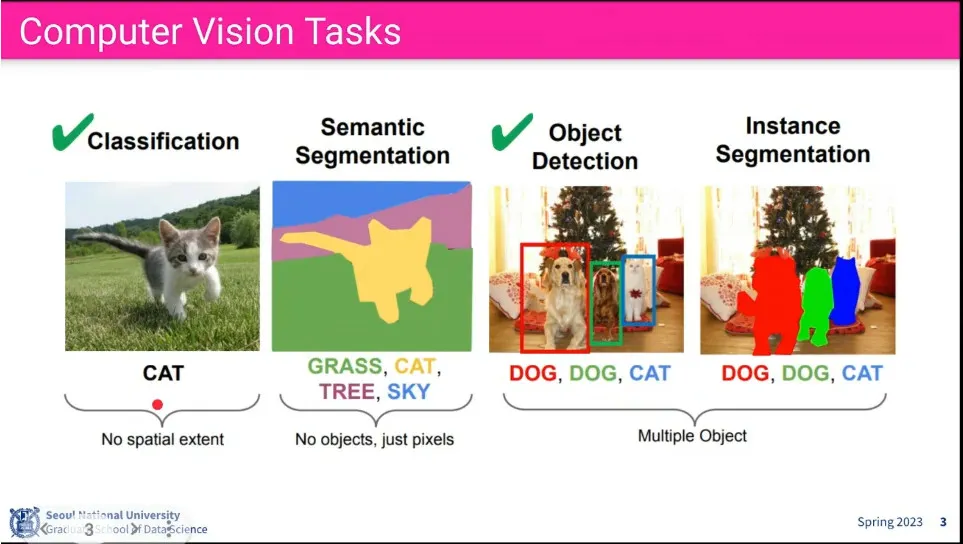
classification은 물체를 인식하는 것.
•
object detection은 그게 어디에 있는지 찾는 것
•
segmentation은 pixel level에서 영역을 찾는 것
•
instance segmentation은 같은 class가 여러 개일 때 구분해서 찾는 것

•
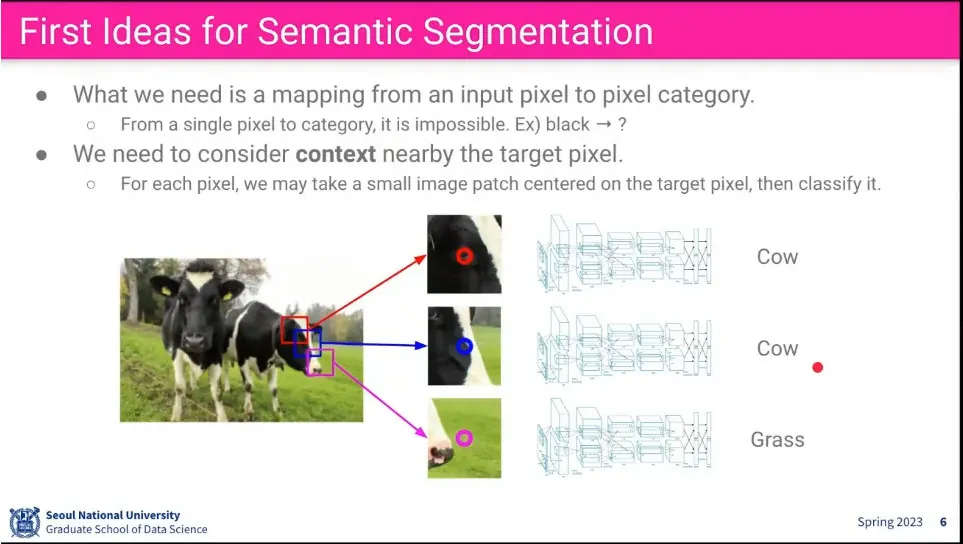
pixel 레벨에서 분류한다.
•
모든 pixel 별로 주위 pixel을 보고 class를 예측하게 한다.

•
이렇게 하면 너무 연산 비용이 비쌈.

•
그럼 feature를 뽑고 그걸 통해 segmentation 하게 하자.
•
근데 기존 conv는 입력을 크기를 줄이기 때문에 그걸 할 수가 없음.

•
그러면 conv에서 크기를 줄이지 않으면 될까? → 그렇게 하면 연산 비용이 매우 큼. conv에서 크기를 줄이는 것은 다 이유가 있음.
•
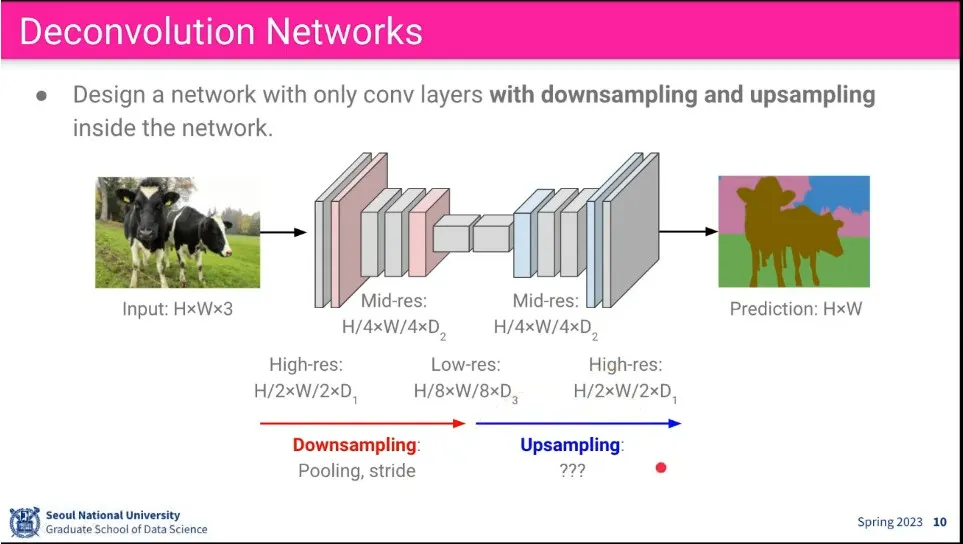
그래서 input과 output의 크기를 맞추고, 그 사이에 크기를 줄이는 과정을 사용함.
◦
이때 크기를 줄이는 부분을 downsampling이라고 하고, 크기를 키우는 것을 upsampling이라고 함.

•
Upsapmling을 위한 방법
◦
nearest neighbor는 가까운 값으로 채우고, bed of nails는 그냥 0으로 채움.
•
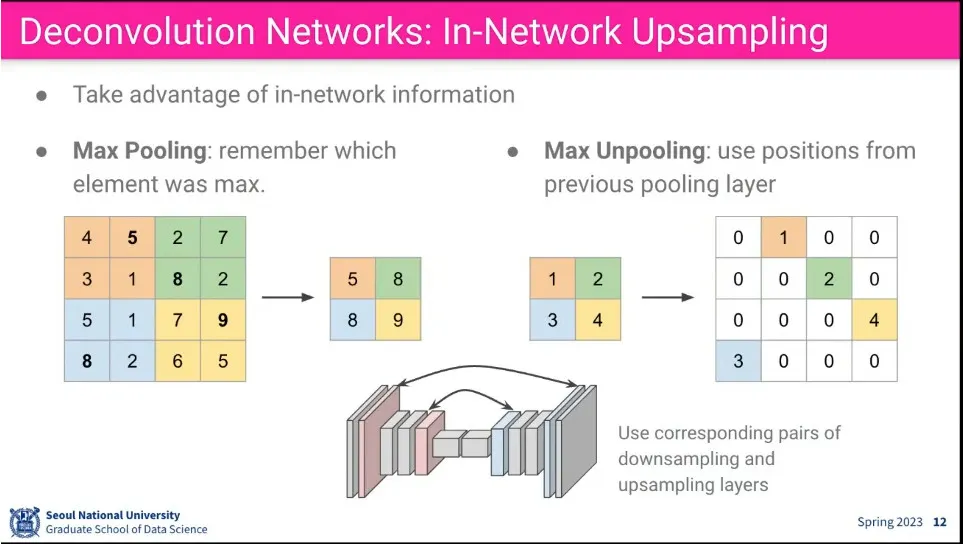
Max Pooling에 대응되게 Max Unpooling을 생각할 수 있음.
◦
줄일 때, 어디서 값을 가져왔는지 기억했다가 Unpooling 할 때 그 위치로 되돌림.

•
기존 convolution 과정.
•
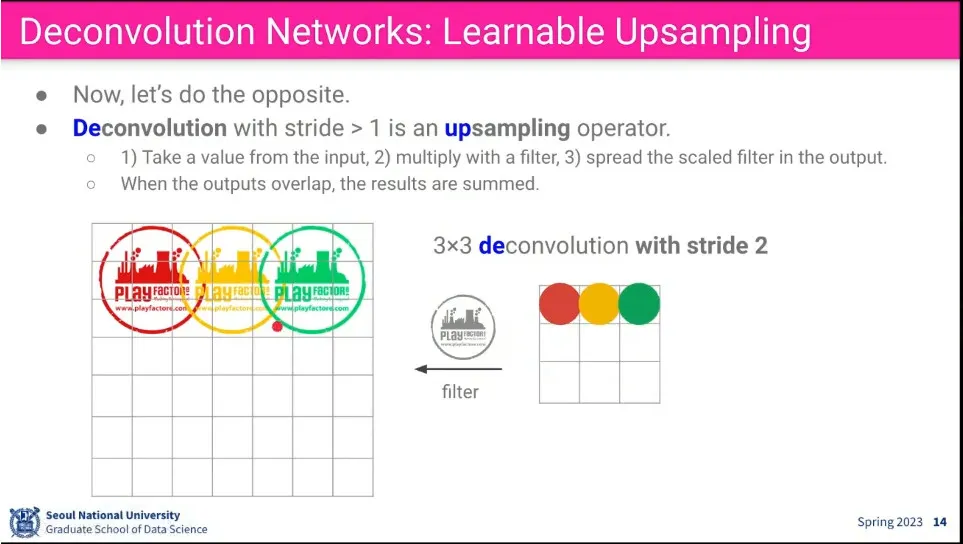
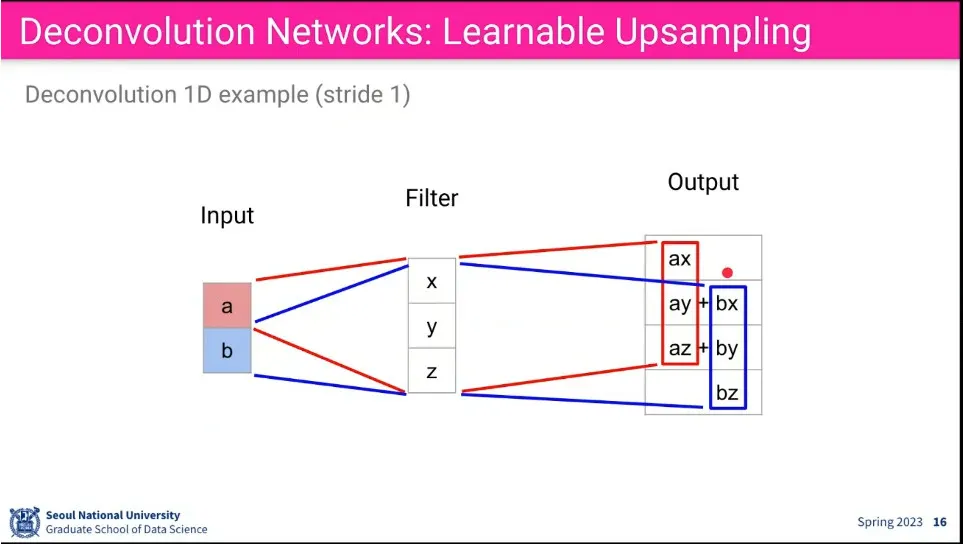
convolution의 역 방향으로 filter에 곱해서 upsampling 할 수 있게 하면, 학습이 가능함.
•
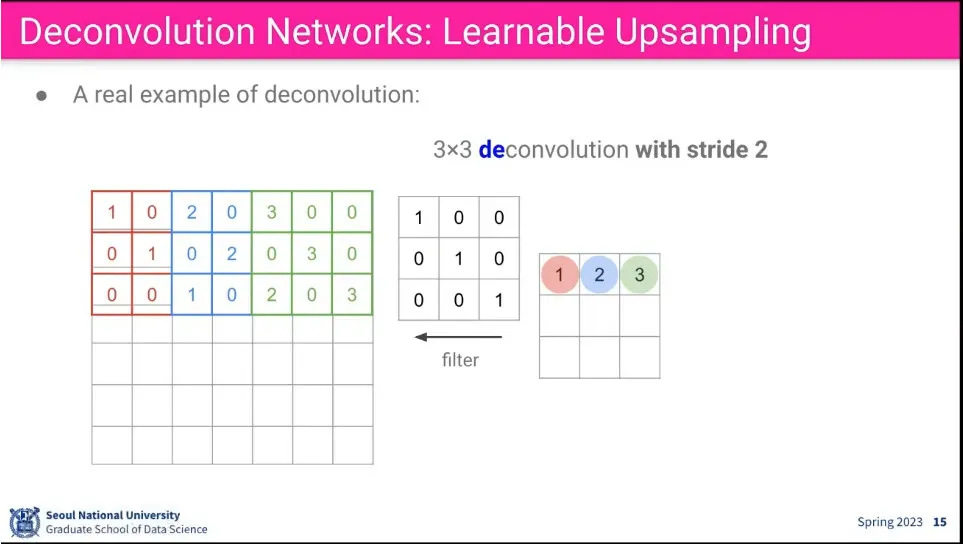
upsampling의 예
•
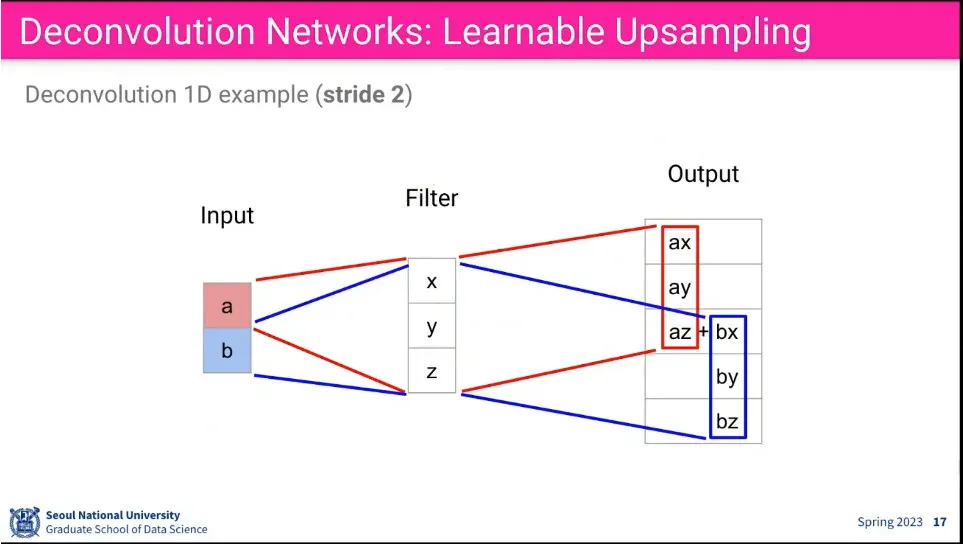
stride도 적용할 수 있다.

•
Deconvolution은 수학적으로 볼때 Transpose Convolution이라고 볼 수 있음.
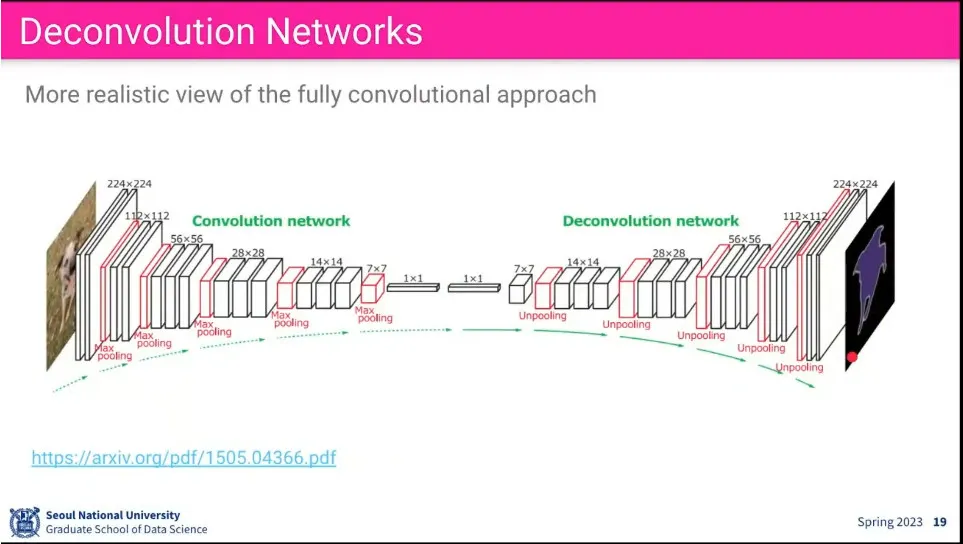
•
전체 구조

•
Downsampling-Upsampling에서 보다 좀 더 많이 쓰이는게 U-Net
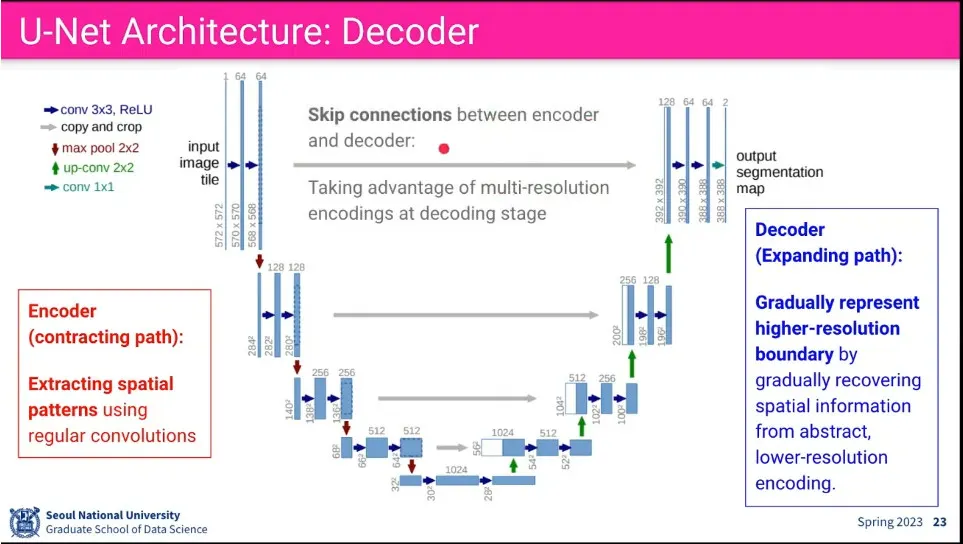
•
Downsample, Upsample 하면서 U 모양을 만듦.
◦
입력과 출력의 크기가 다른데, 실제 원하는 크기는 출력의 크기고, 입력은 출력의 크기에 대해 padding을 붙여서 사용함.
◦
upsample 단계에서 그냥 복원하면 잘 안되기 때문에 downsample에서 있었던 정보를 가져와서 붙여주는데 이걸 skip connection이라고 함.
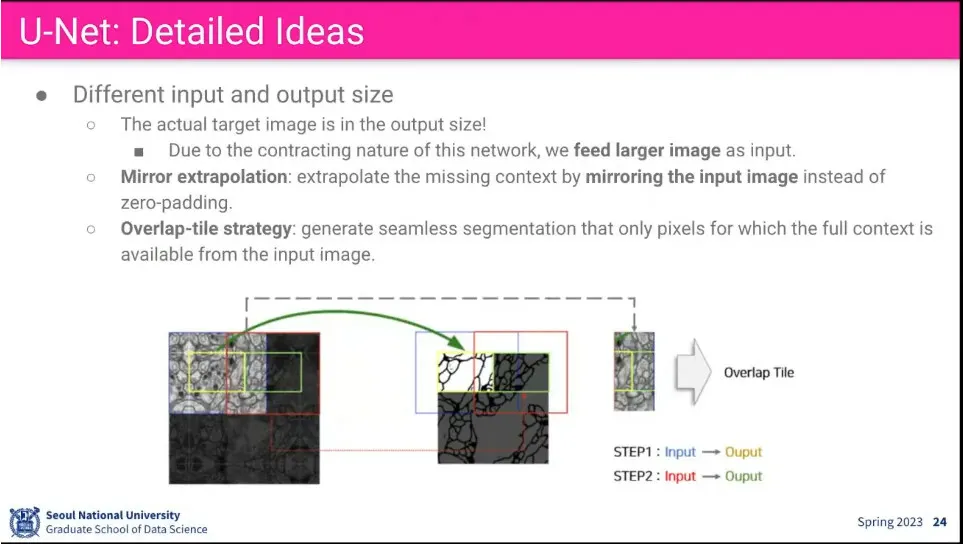
•
Input에서 padding을 0을 넣지 않고, 테두리 쪽의 이미지를 거울 반사 시켜서 넣음.
◦
실제 이미지가 있으면 그걸 쓰고, 없으면 현재 이미지를 거울 반사 시켜서 넣음.
•
근데 이후에 쓰는 사람들은 그냥 zero padding을 씀. 별 차이 없더라.

•
UNet의 Loss는 기본적으로 정답과 pixel-by-pixel로 비교해서 cross entropy loss를 줌.
◦
추가로 가장 자리에 있는 픽셀에 가중치를 주는 함수 w(x)를 곱해 줘서, 가장 자리를 잘 예측하게 함.

•
응용 사례들

•
참고 논문들

•
Instance segmentation은 같은 class의 object도 분리하는게 목표
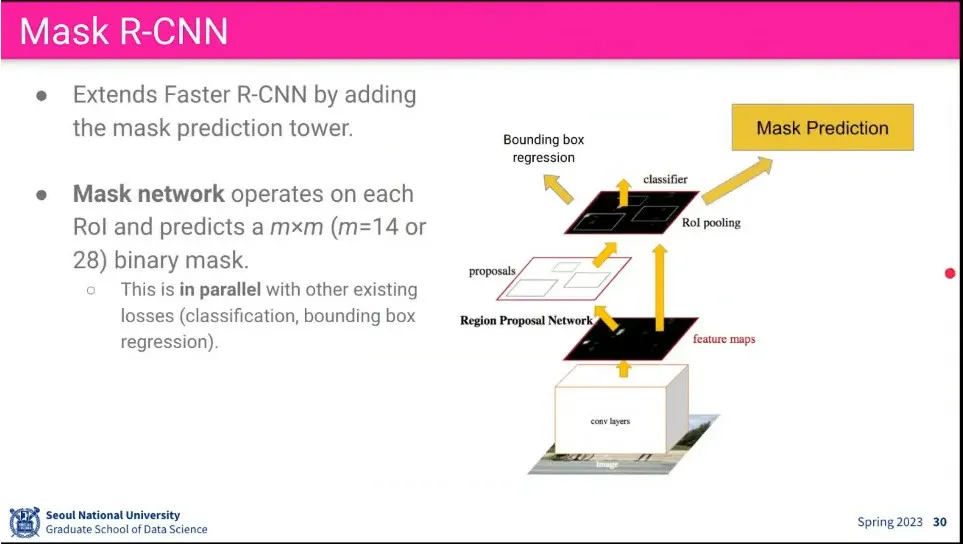
•
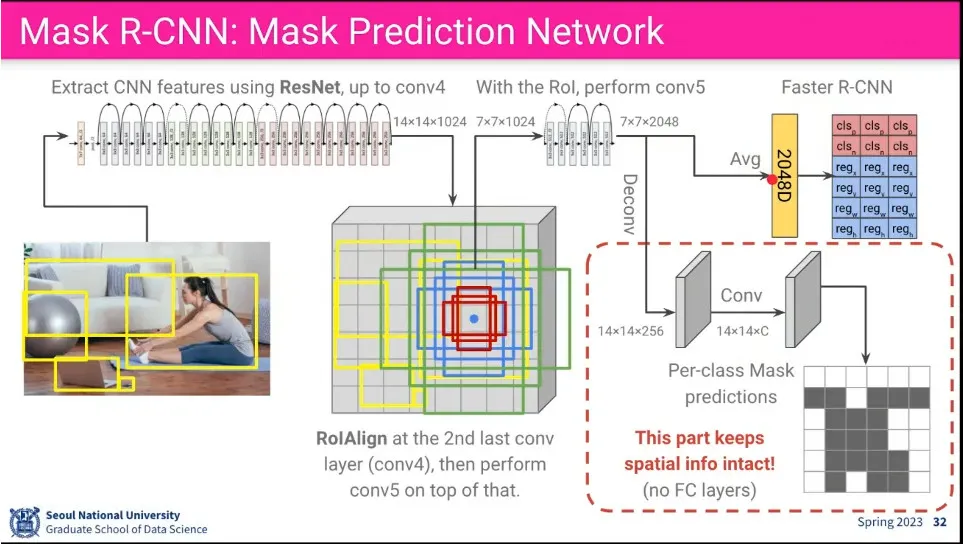
Mask R-CNN은 Faster R-CNN을 segment 단위로 확장 시킨 것. 기존 Faster R-CNN에 Mask Prediction을 추가 함

•
pooling 할 때 가중합을 사용하는 Roi Align을 사용함
•
기존 Faster R-CNN에 Deconv-Conv를 통해 Mask를 예측하는 것을 추가 함.

•
Faster R-CNN의 Class, bounding box loss에 추가로 pixel level로 Mask를 예측하는 loss를 추가함.
◦
이때 물체가 실제로 존재하는지도 반영함. —object가 없는데 mask를 씌울 필요는 없으므로

•
사례
•
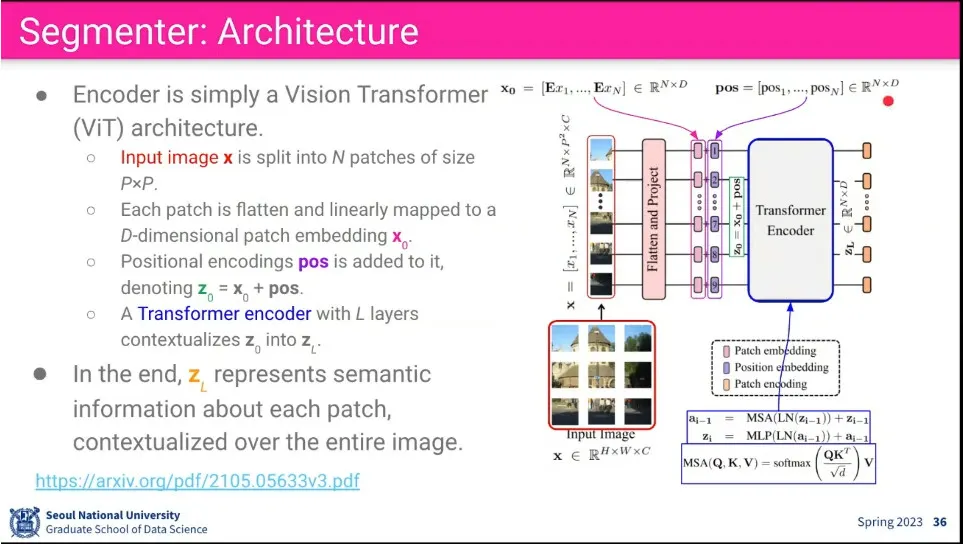
Segmenter는 ViT를 이용한 Segmentation 모델
◦
encoder는 기존 ViT와 유사함
•
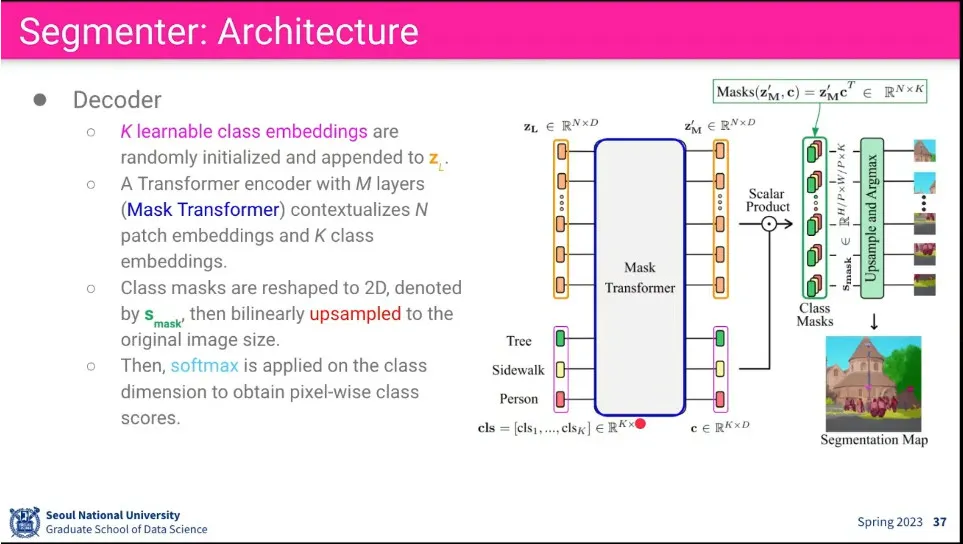
Decoder에는 segmentation을 위해 Class token를 추가해서 입력으로 사용함
◦
Transformer block을 돈 후에 나온 output에 대해 외적(out product)를 돌림.
◦
그 후에 upsampling 하고 argmax를 해서 정답과 loss를 비교한 후 backpropagation 수행
•
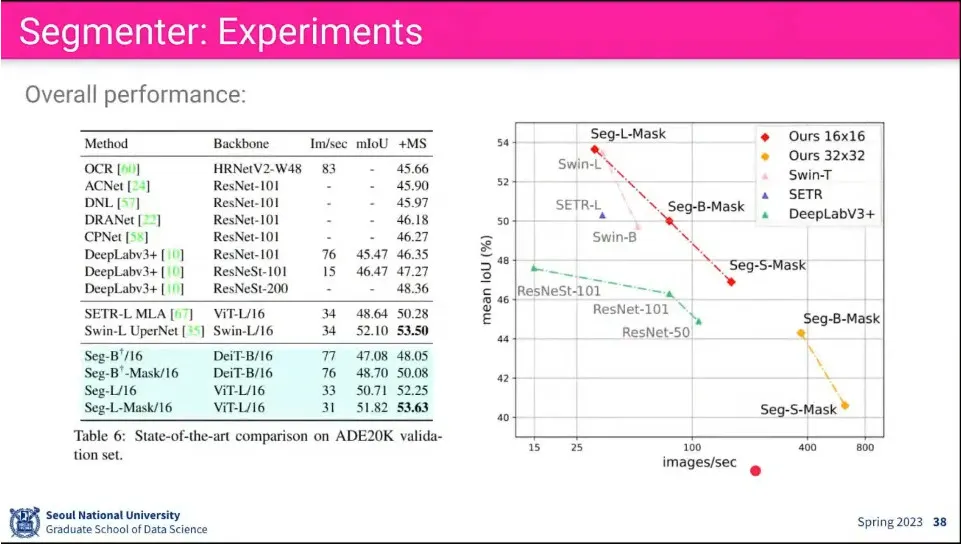
기존 모델들 보다 성능이 좋다고 함
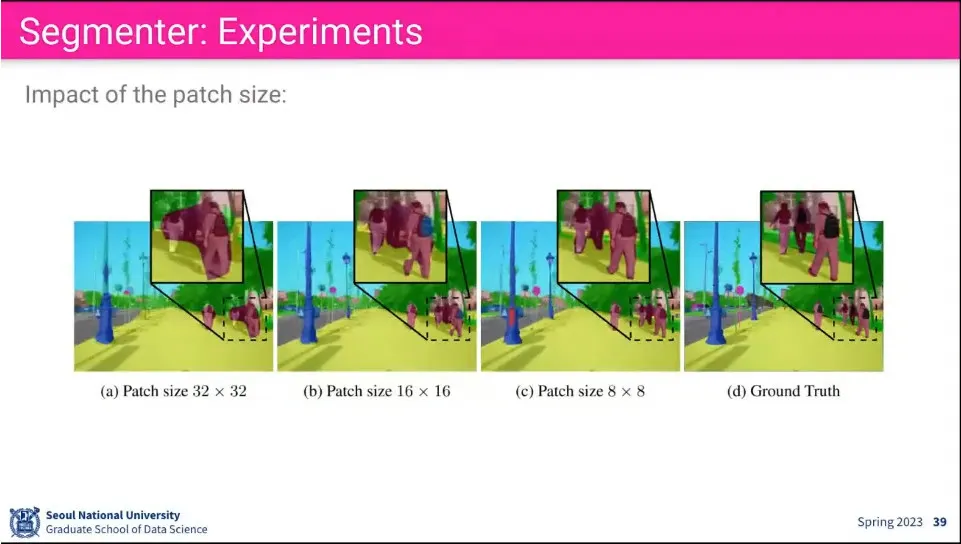
•
patch size를 잘게 쪼갤 수록 성능이 잘 나옴.
◦
당연히 그만큼 계산량도 많음.
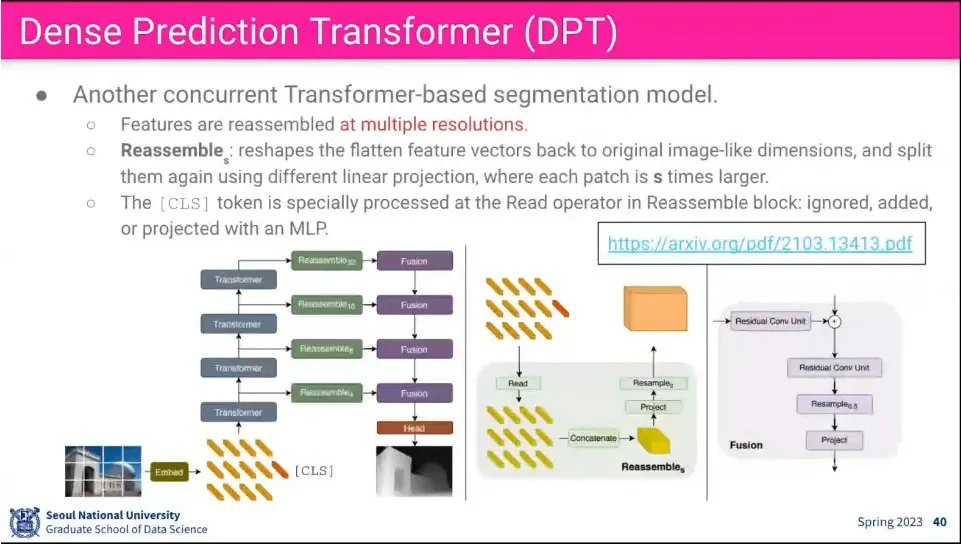
•
Dense Prediction Transformer도 ViT를 사용하는 부분은 동일.
◦
feature들이 여러 resolution 단계에서 reassemble 하는게 차이.

•
DPT 예
◦
Segmentation 뿐만 아니라 Depth Estimation에도 사용 가능하다고 함.
•
Facebook에서 만든 MiDaS(Depth Estimation)나 SAM(Instance Segmentation)도 참고
