
The multivariate normal
Definition
•
MVN 밀도는 다음처럼 정의된다.
•
여기서 는 평균 벡터이고
◦
는 공분산 행렬이다.
◦
정규화 상수 는 pdf 적분이 1이 되도록 하기 위한 것이다.
◦
지수 내부의 식(의 계수 무시)는 데이터 벡터 와 평균 벡터 사이의 제곱된 Mahalanobis 거리이다. 다음처럼 주어진다.
Gaussian shells
•
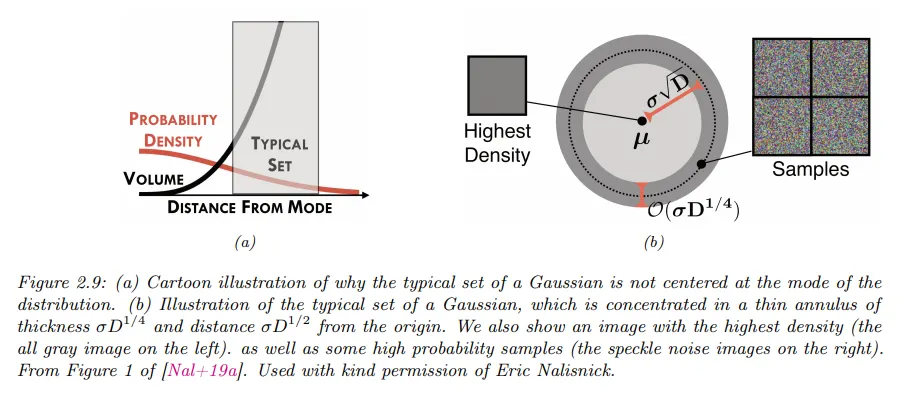
다변량 가우시안은 고차원에서 직관과 다르게 행동한다. 예컨대 에서 샘플을 추출한다고 할 때, (여기서 는 차원의 수이다) 의 대부분이 어디에 있을지 예상할 수 있을까?
◦
pdf의 peak(mode)가 원점이기 때문에 대부분의 샘플이 원점 근처에 있다고 생각하는 것은 자연스럽지만 고차원에서 가우시안 집합의 일반적인 형태는 원점으로부터의 거리가 이고 두께(thickness)가 인 얇은 shell(껍데기) 또는 annulus(고리) 모양이다.
•
이것의 직관적인 이유는 다음과 같다.
◦
밀도는 원점으로부터 로 감소하지만 구(sphere)의 부피(volume)는 로 증가한다. 질량은 밀도 곱하기 부피이므로 대부분의 점이 이 두 항이 ‘균형을 이루는’ 이 고리 안에 있게 된다.
◦
이를 ‘가우시안 비누 방울(Gaussian soap bubble)’ 현상이라고 하며, 아래 그림에 설명되어 있다.
•
가우시안에 대한 일반적인 집합이 왜 반경 의 얇은 고리(annulus)에 모이는지 보기 위해 원점으로부터 점 의 제곱 거리를 다음과 같이 생각하자.
◦
아래에서
•
이에 대한 기대 제곱 거리와 분산 제곱 거리는 다음과 같이 주어진다.
•
(차원)가 커짐에 따라 변동 계수(coefficient of variation)는 0으로 간다.
•
따라서 기대 제곱 거리는 주위에 모여들게 된다. 따라서 기대 거리는 주위에 모여들게 된다.
Marginals and conditionals of an MVN
•
랜덤 변수 의 벡터를 과 2개의 부분으로 분할한다. 따라서
•
이 분포의 marginal은 다음과 같이 주어짐을 보일 수 있다.
•
조건부 분포는 다음의 형식을 가짐을 보일 수 있다.
•
의 posterior 평균이 의 선형 함수임에 유의하라. 그러나 posterior 공분산은 에 독립이다. 이것은 가우시안 분포의 기이한(peculiar) 속성이다.
Information (canonical) form
•
평균 벡터 와 공분산 행렬 의 측면에서 MVN을 파라미터화하는 것이 일반적이다. 그러나 canonical(표준) parameter 또는 natural(자연) parameter를 사용하여 가우시안 분포를 표현하는 것이 유용할 수 있다. 다음처럼 정의한다.
•
행렬 은 정밀도(precision) 행렬이라 하고, 벡터 는 precision-weighted 평균이라 한다.
•
다음을 사용하여 더 친숙한 moment 파라미터로 다시 변환할 수 있다.
•
따라서 MVN을 다음처럼 canonical form으로(또는 information form이라고 한다) 작성할 수 있다.
•
여기서 표준 파라미터화 된 와 구분하기 위해 표기법을 사용했다.
•
information 형식에서 marginalization과 conditioning 공식을 유도하는 것도 가능하다. marginal에 대해 다음이 성립한다.
•
조건부에 대해 다음이 성립한다.
•
고로 moment 형식에서는 marginalization이 더 쉽고, information 형식에서는 conditioning이 더 쉽다는 것을 알 수 있다.
