
•
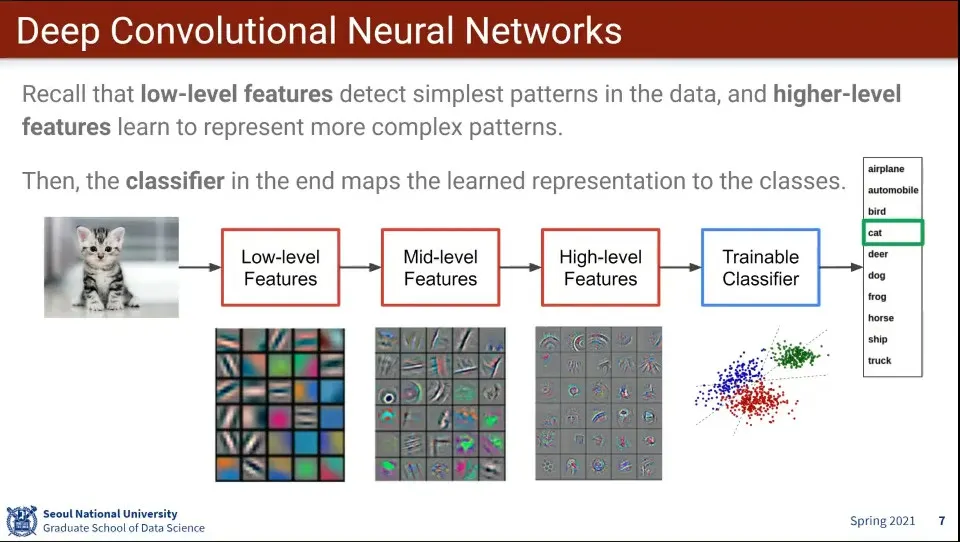
CNN 예

•
만일 기존 모델을 사용하는데, 데이터셋이 달라지면 어떻게 될까?
◦
같은 cat 라벨이지만 index가 다르고, apple은 없던 것이 생김.

•
만일 위와 같이 항공기 내에서 기종만 다르게 분류하고자 한다면 어떻게 될까?

•
데이터셋이 충분하지 않을 때 다른 모델을 가져와서 학습을 시켜서 사용할 수 있다.
•
Transfer Learning이랑 기존 모델을 이용해서 fine-tuning 하는 것을 말함
◦
목표로 하는 타겟이 아닌 큰 데이터셋으로 학습하는 것을 pre-training이라고 함. 그런 모델을 pretrained model이라고 함.
◦
그렇게 학습된 모델을 자신이 목표로하는 데이터 class에 맞게 output layer 쪽만 조금 변형하는 것을 fine-tuning이라고 함.
•
이미 공개된 pre-trained 된 모델을 가져다가 fine-tuning 하여 원하는 모델을 만든다.
•
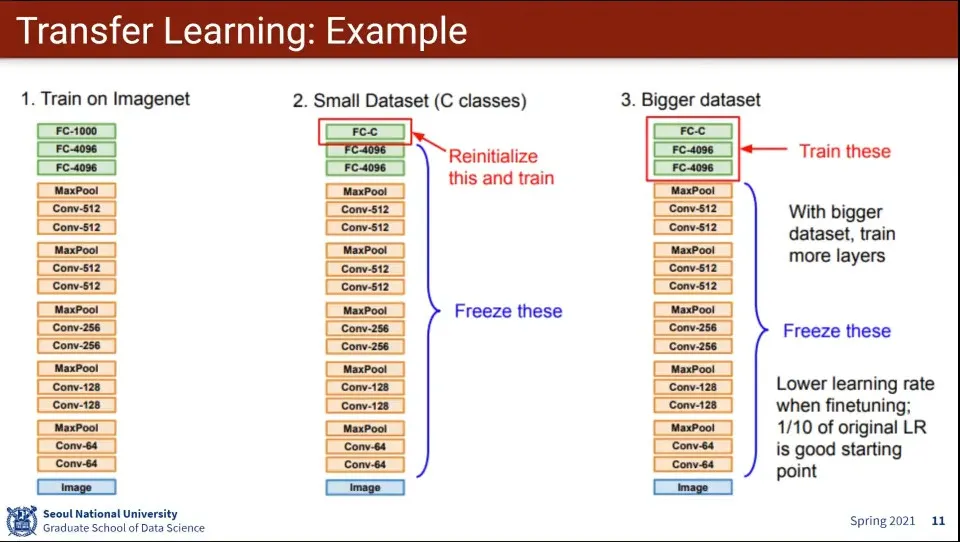
ImageNet 예제
◦
기존에 학습되어 있는 ImageNet 모델을 가져와서
◦
데이터셋이 작다면 마지막 레이어만 고치고 나머지 레이어는 고정 시켜놓고 다시 학습 시킴
◦
만일 데이터셋이 좀 많다면 뒷 부분의 몇 개의 레이어를 학습 시킴
◦
이때 재학습하려는 layer는 초기화한 후 학습함. random initialize 한다.
•
앞부분은 이미지의 feature를 뽑는 단계이기 때문에 그대로 사용하고, 마지막 부분이 분류하는 부분이기 때문에 그 부분만 다시 학습 함
•
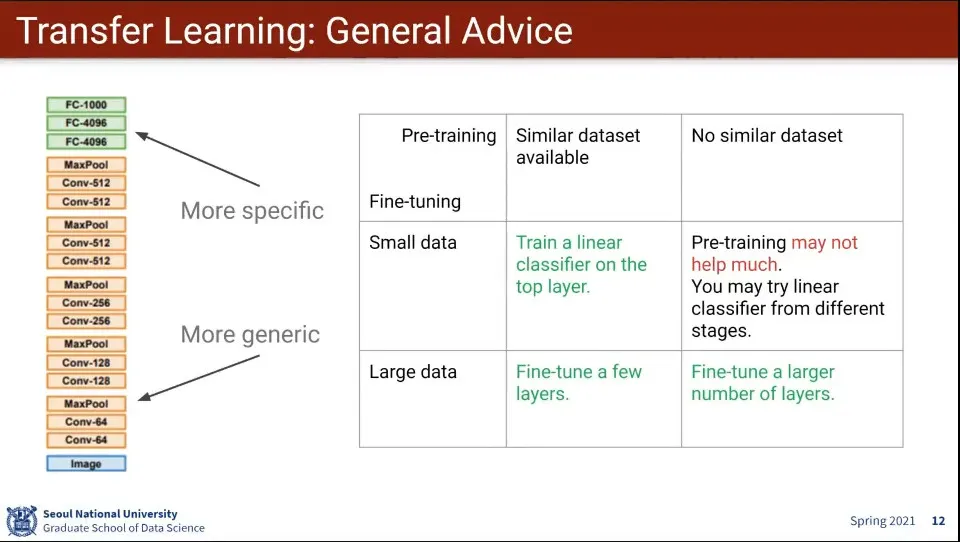
레이어의 아래로 갈수록 일반화 된 feature를 학습하고, 위로 갈수록 특수화 된 feature를 학습함
•
Pre-training 할 만한 유사한 데이터가 있는 상태
◦
데이터셋이 많음
▪
위의 몇 개 레이어를 학습 시킴
◦
데이터셋이 적음
▪
최상위의 분류 레이어만 학습 시킴
•
Pre-training 할 만한 유사한 데이터가 없는 상태
◦
데이터셋이 많음
▪
상위에서 다수의 레이어를 학습 시킴
◦
데이터셋이 적음
▪
pre-training 은 도움이 안 됨. 다른 단계에 선형 분류기를 시도해 보라
•
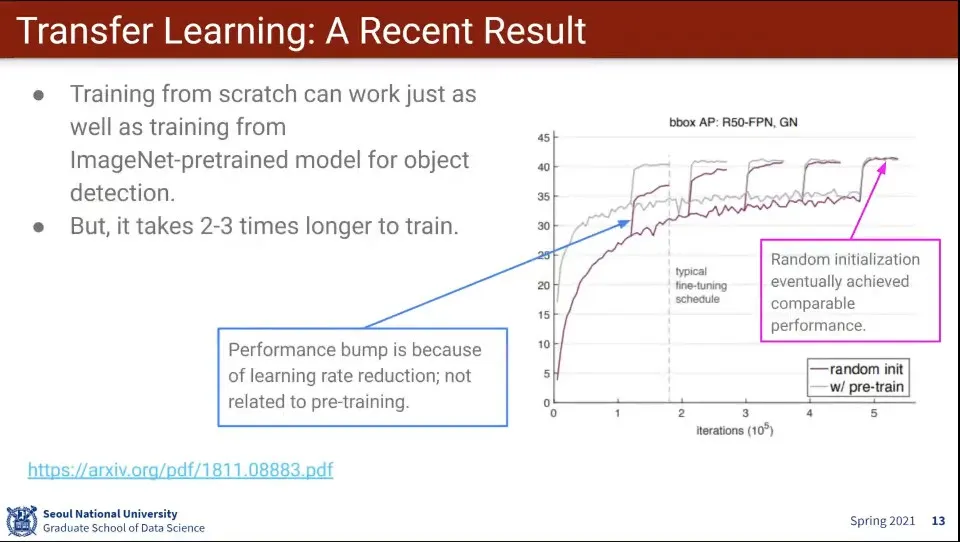
최근에 pretrained 모델은 빨리 수렴하는 것일 뿐, 최종 목표를 높이지는 못한다는 논문이 나옴.

•
데이터셋이 충분히 많지 않다면, 비슷한 성격을 가진 다른 모델을 찾아서 fine-tuning 하는게 좋다.
•
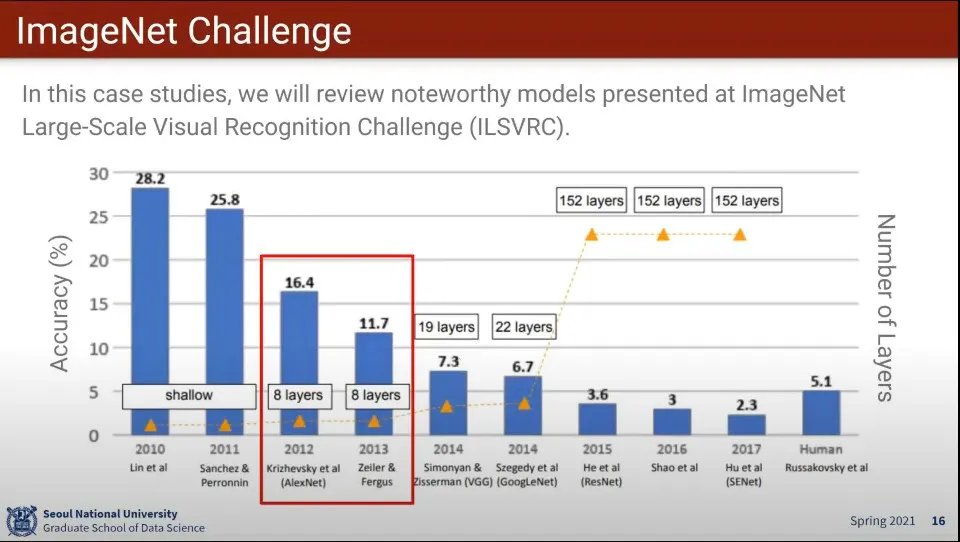
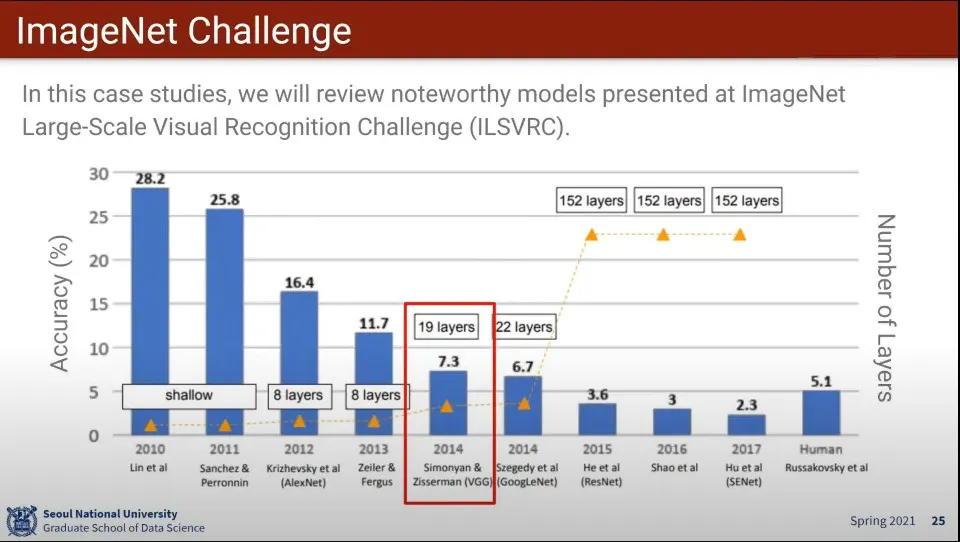
AlexNet는 2012년에 나옴
•
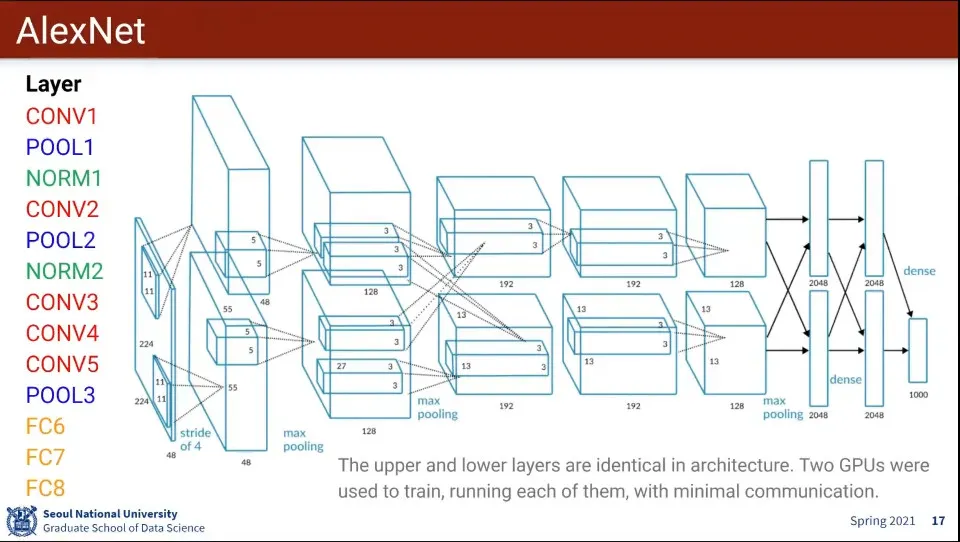
AlexNet은 위와 같이 생김
◦
일반적으로 Conv-Pool-Norm 가 하나의 Set으로 사용 됨
◦
이렇게 만들어진 Layer는 별다른 이유가 없고 경험적임 (Art의 영역임)
•
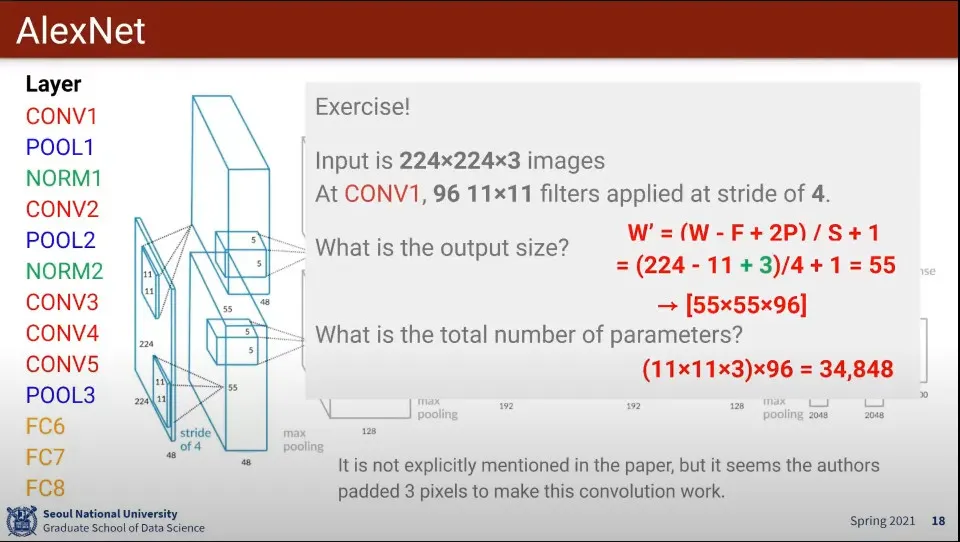
AlexNet의 Conv1 구조는 위와 같다.

•
AlexNet의 Pool1 구조는 위와 같다.

•
AlexNet의 구조 연습

•
AlexNet의 특징들
◦
AlexNet이 최초의 CNN 기반 우승 모델인데 이때 이미 SGD에 Momentum을 사용했네. decay도
•
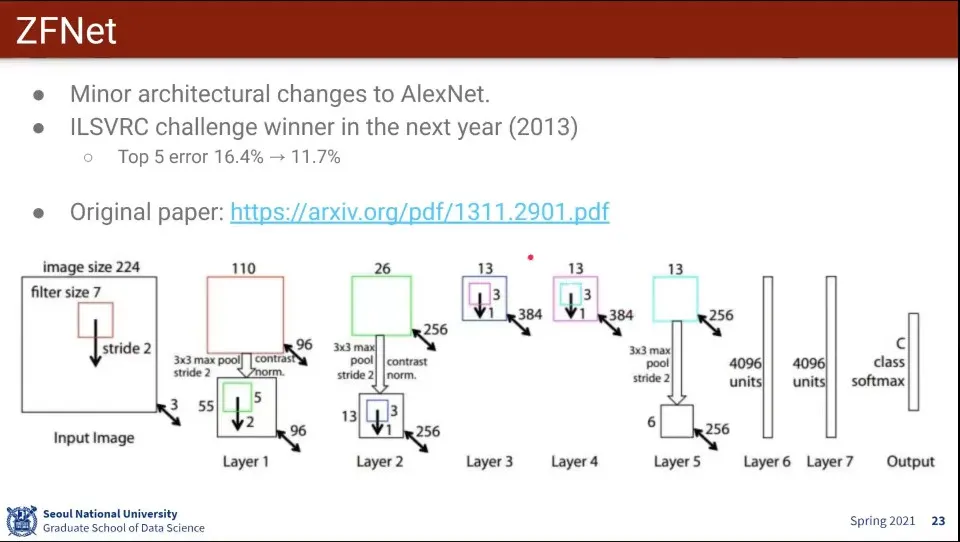
AlexNet에 비해 좀 더 최적화를 잘한 모델이 ZFNet
•
VGG는 2014년에 나왔는데, 기존 모델에 비해 레이어가 2배 이상 늘고, 정확도도 크게 개선 됨
◦
VGG는 옥스포드에서 나온 모델

•
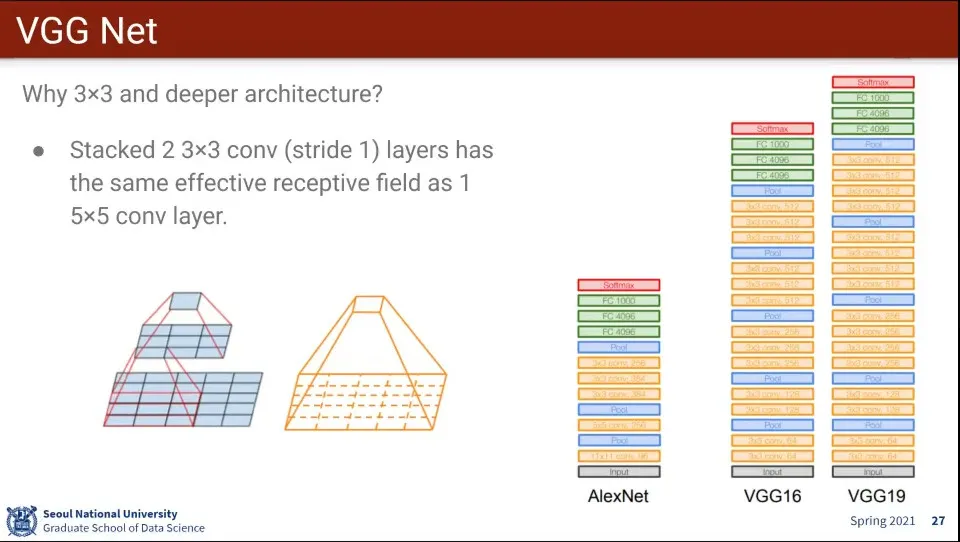
VGG는 3x3 filter만 사용하고 대신 layer를 더 깊게 쌓음 —AlexNet은 11x11, 5x5도 사용함
◦
layer 개수를 셀 때는 pooling layer와 input, output은 세지 않음
•
3x3을 2개 층으로 쌓으면, 5x5 크기를 학습한 게 됨
◦
다시 말해 3x3을 2개 층으로 쌓으면 5x5 1개층을 학습한 것과 동일 함
•
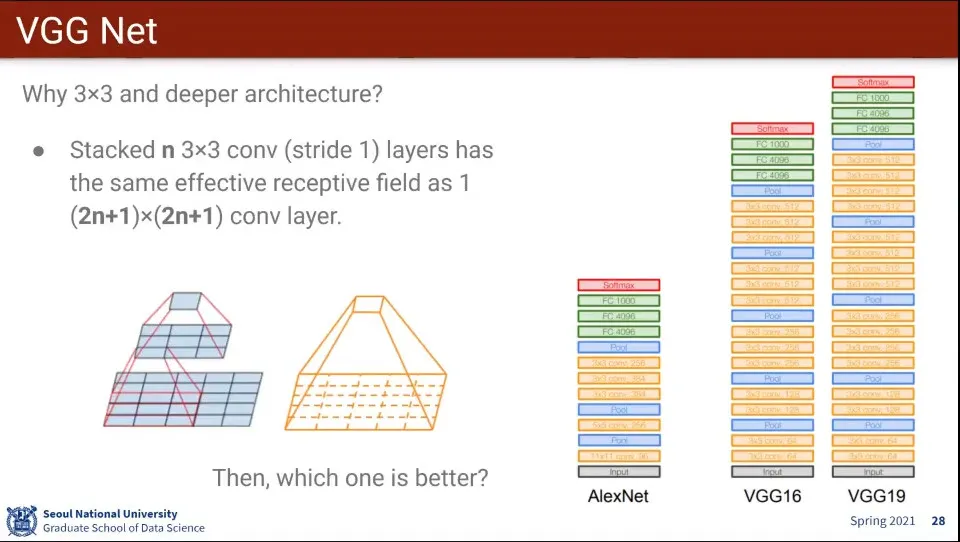
같은 식으로 3x3을 3개 층으로 쌓으면 7x7 크기를 학습한 효과가 남

•
만일 7x7 filter로 1개 layer를 쌓으면 의 파라미터를 갖게 되는데,
◦
3x3으로 3개층을 쌓으면 개의 파라미터만 갖게 됨.
◦
다시 말해 학습은 동일한데 filter의 크기가 커지면 점점 Fully-conntected Layer와 가까워지면서 연산량이 많아짐
•
더불어 layer를 여러층 쌓으면 layer마다 activation function이 들어가기 때문에, 복잡한 관계를 표현하는데 유연해 지는 장점도 있음
◦
때문에 단순히 3x3이 3개층이라고 7x7 1개층과 완전히 동일하지 않음
◦
작은 것을 deep 하게 쌓는게 좋다. 이게 딥러닝의 핵심

•
VGG의 구조
◦
메모리의 크기는 결국 layer 크기를 모두 곱한 것 초반에 사용하는게 많고 뒤로 갈수록 작아진다.
◦
224x224짜리 이미지를 학습하는데 96mb의 메모리가 필요하다.
◦
parameter는 filter의 크기라서 뒤로 갈수록 커짐

•
VGG 특징
◦
VGG19과 VGG16은 Layer의 차이인데 성능 차이는 크지 않았음. 메모리만 더 먹고 성능은 살짝 좋았음
•
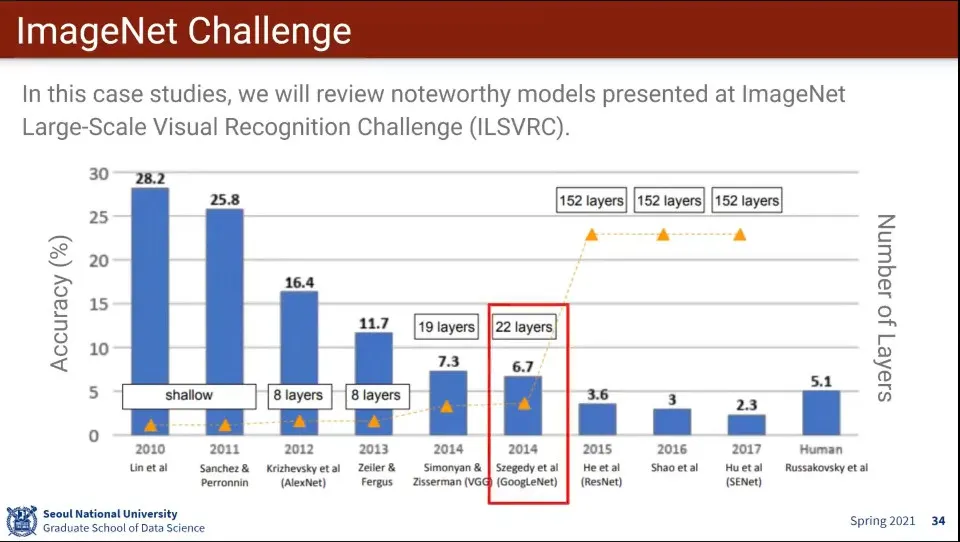
VGG 다음에 우승한게 GoogLeNet

•
GoogLeNet은 Inception이라는 아이디어를 차용한 모델
◦
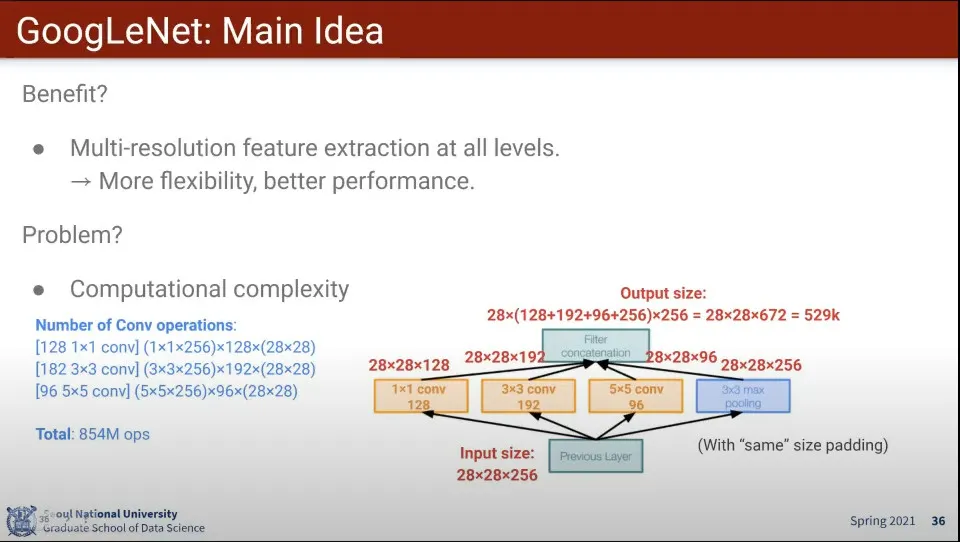
아이디어는 Layer에 적용하는 Filter Size를 여러 개 쓰자는 것
◦
1x1, 3x3, 5x5를 동시 적용하고 합침
•
Multi-resolution feature 추출이 모든 레벨에서 이루어지기 때문에 더 유연해지지만,
•
계산량이 많아짐

•
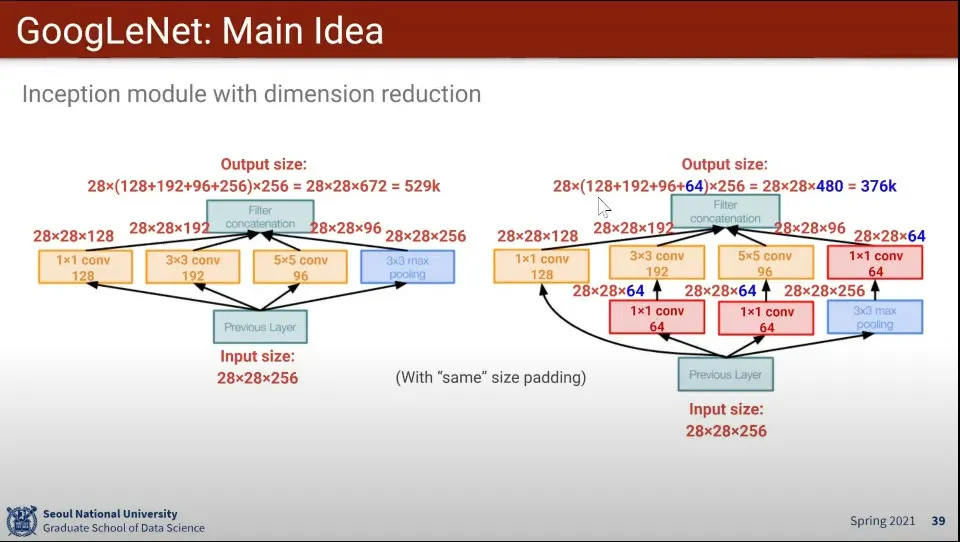
계산량 문제를 해결하기 위해 1x1 Conv를 이용해서 Dimension 줄여서 처리 함
◦
1x1을 Dimension을 늘리기 위해 사용하는 경우도 가끔 있음
•
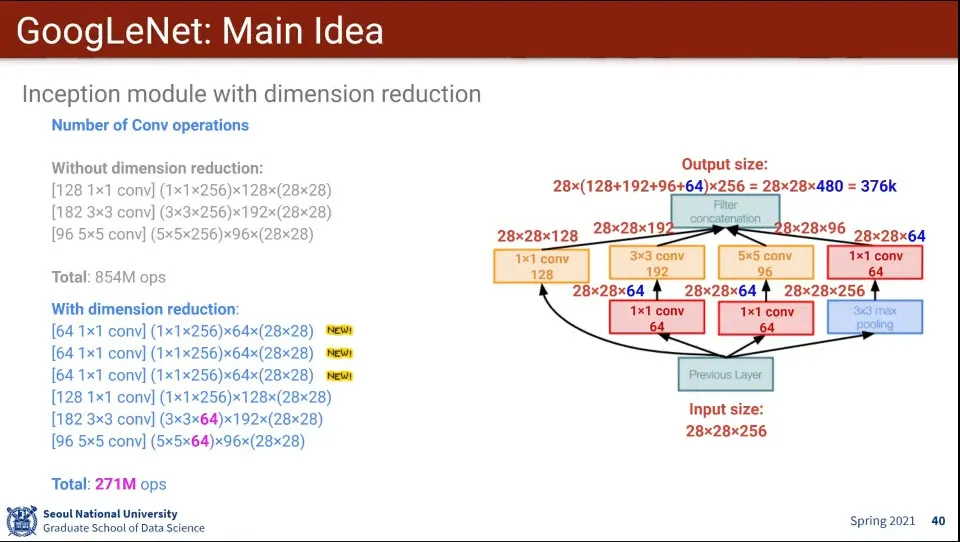
1x1 Conv에서는 굳이 할 필요 없으니 제외하고 3x3과 5x5에 1x1 Conv를 적용하면 계산량을 많이 줄일 수 있음
•
계산량은 많이 준다.
•
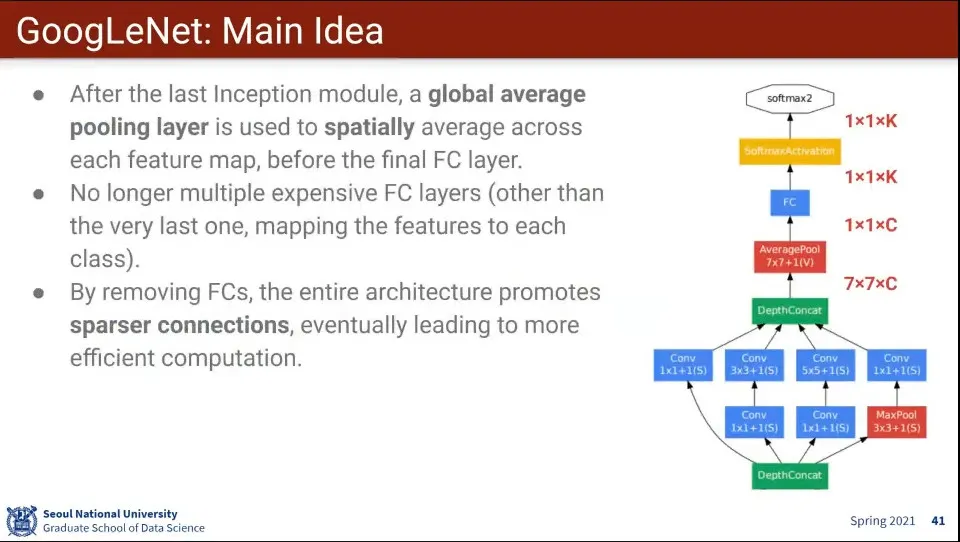
마지막 Fully-Connected의 크기가 큰데, 이것을 평균 내서 크기를 또 줄임.
•
이런 식으로 파라미터 수를 줄이고 계산량을 줄였다.
•
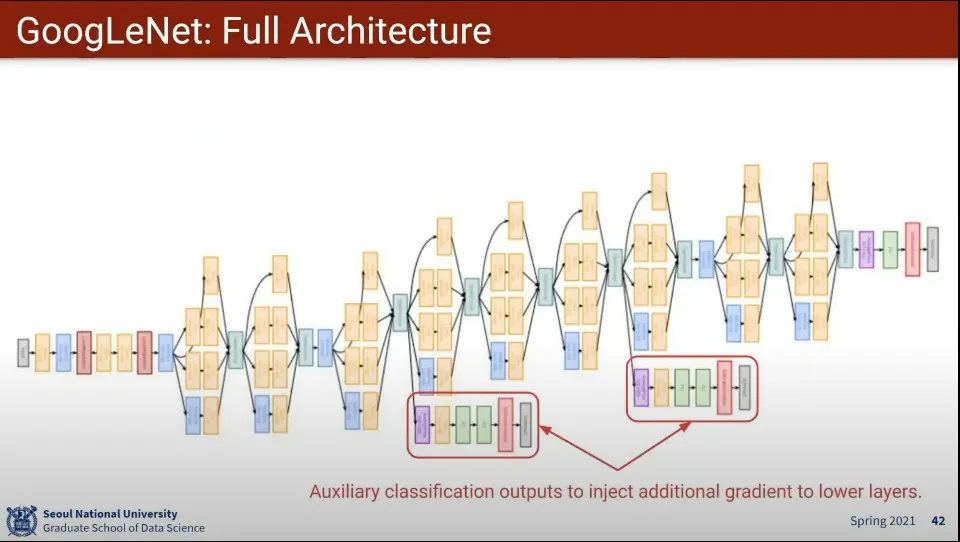
GoogLeNet의 구조
◦
3층과 6층에 classification loss를 계산해 주는 layer를 하나 더 추가해 주는게 특징
◦
layer가 깊다보니 앞부분 layer에 vanishing gradient 문제가 발생함. 그걸 보완해 주기 위해 위의 auxiliary layer를 추가함. 대신 가중치를 줄여서 적용

•
GoogLeNet 특징
•
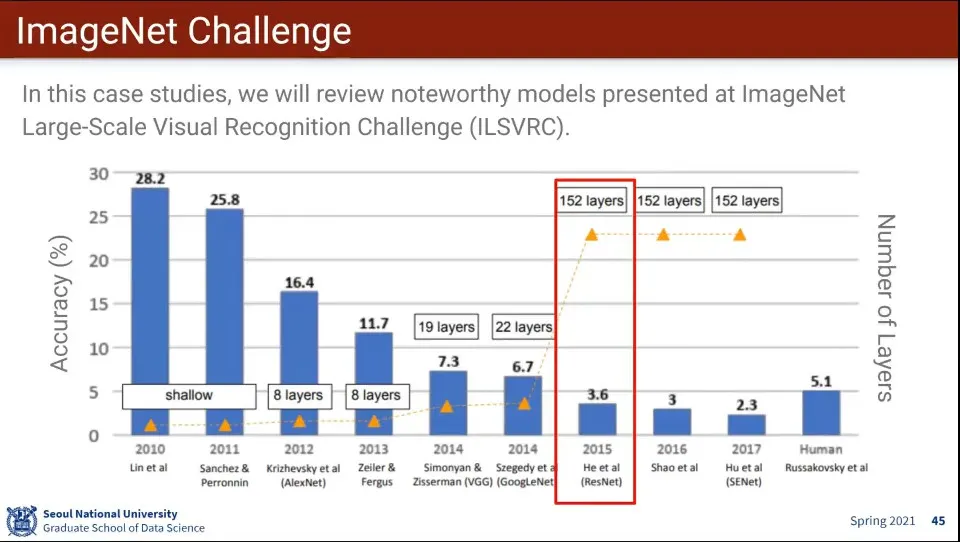
ResNet은 MS에서 만든 모델
◦
기존 모델에 비해 Layer가 크게 늘었고, 인간의 인식 능력을 넘어섬
◦
역사적으로 중요해서 이후 ResNet의 개념을 많이 차용함
•
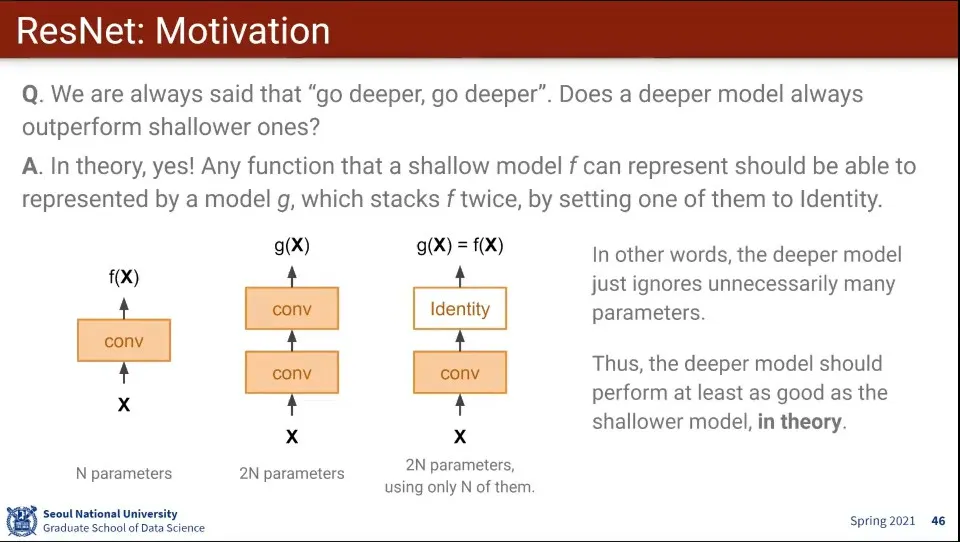
무조건 Layer를 깊게 쌓으면 좋은가?
◦
이론적으로는 그렇다. Layer가 깊으면 최소한 적은 Layer 이상의 성능이 나와야 함.
•
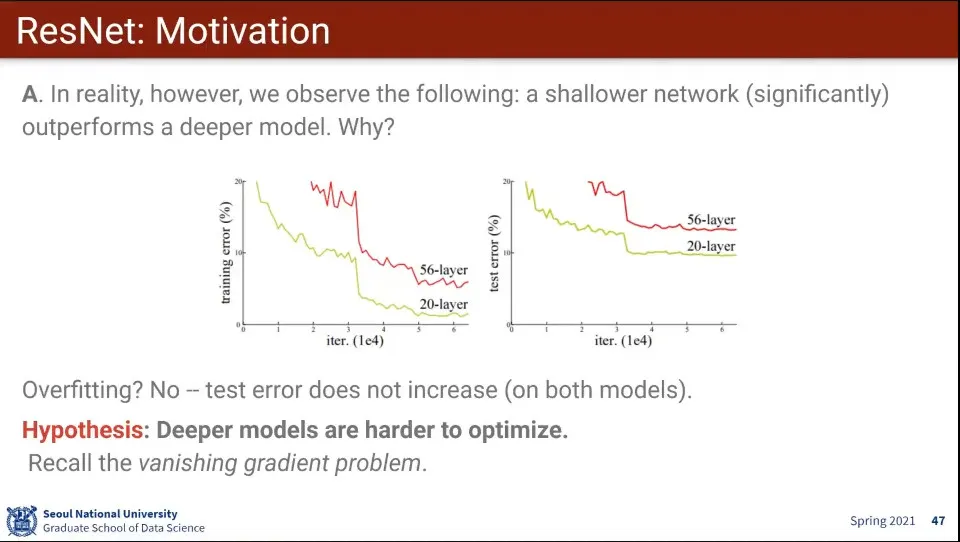
근데 실제로 돌려보면 레이어가 적은게 성능이 더 좋게 나오는 경우가 있음
◦
Overfitting 문제는 아님. 레이어가 적을 때도 비슷한 그래프를 그림
•
진짜 문제는 Training 자체가 힘들다는 것
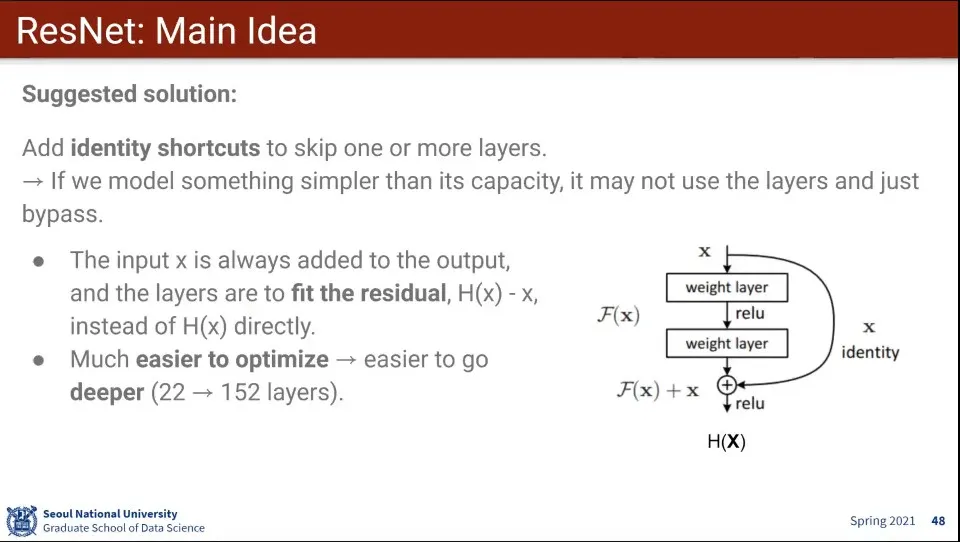
•
ResNet는 Layer를 점프하는 아이디어를 사용
•
Jump하는 것 자체는 모델이 알아서 하도록 함
•
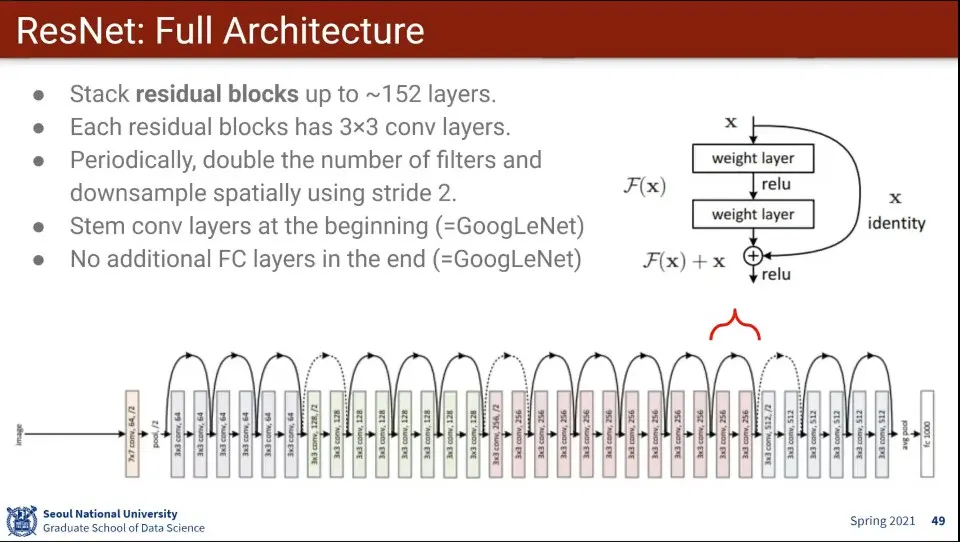
residual block을 통해 학습하다가 건너 뛸 수 있게 함. 그렇게 해서 layer 수를 왕창 늘림
◦
건너 뛰는건 모델이 학습을 통해 스스로 알게 함
•
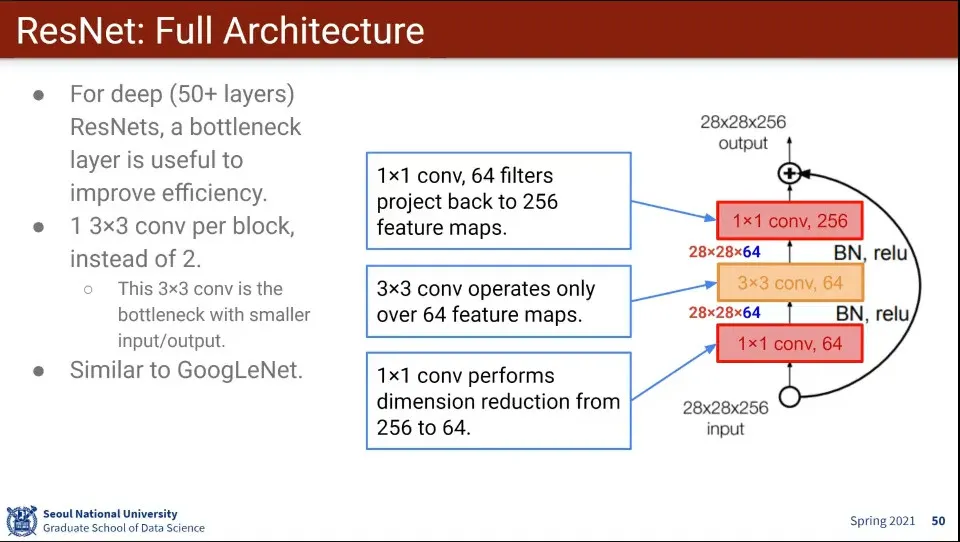
계산량이 많기 때문에 GoogLeNet 처럼 1x1 conv layer를 이용하여 사이즈를 줄이는 것을 사용함
◦
다만 사이즈가 바뀌면 안되기 때문에 계산이 끝나면 1x1 conv layer를 이용해서 사이즈를 다시 늘림

•
ResNet 특징
◦
처음으로 사람을 이긴 모델
◦
bath normalization을 본격적으로 사용함. 대신 dropout을 사용 안 함
◦
xavier initialization도 사용함
•
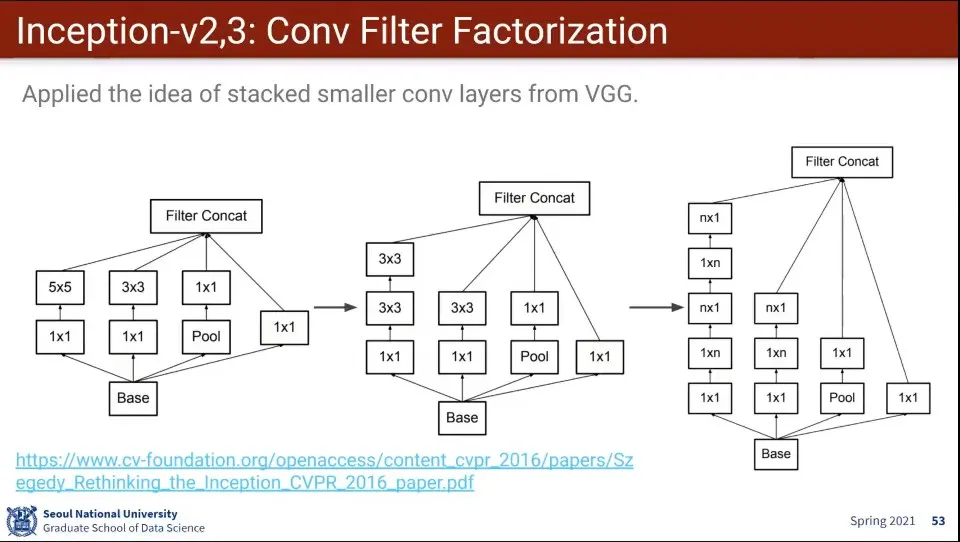
GoogLeNet의 Inception 모델이 처음 나오고 나서 이후 v2, 3이 계속 나옴
◦
v1에서는 5x5를 썼던거를 v2에서 3x3 2개로 바꿈
◦
v3에서는 그것을 다시 3x1 과 1x3으로 쪼갬 - 가로 방향으로 한 번, 세로 방향으로 한 번
◦
이렇게 하면 5x5를 3x3 2개로 줄인 것과 같이 같은 효과를 지니면서 파라미터를 줄일 수 있음
◦
v2와 v3는 위 레이어 계층만 다르고 나머지는 다 동일
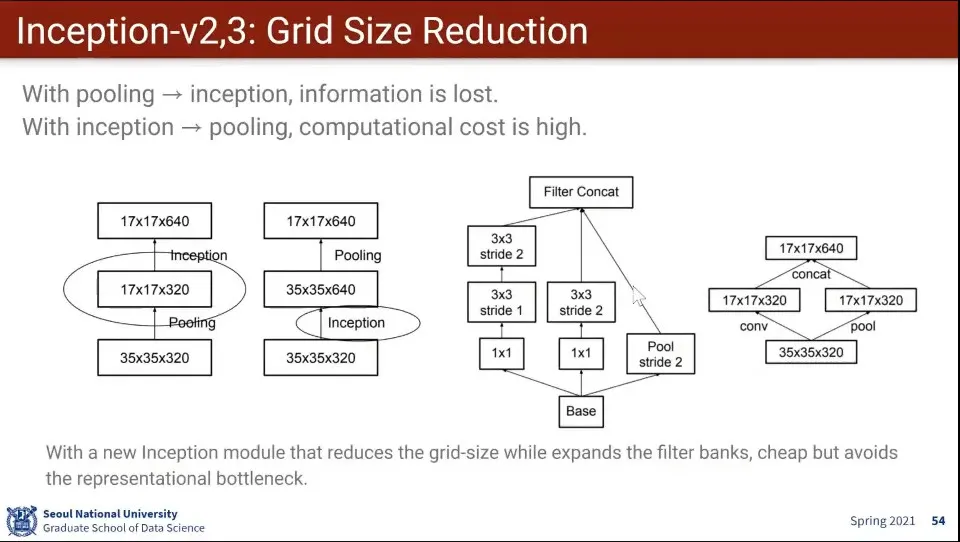
•
Grid Size 수정도 있었음
◦
풀링을 먼저하고 inception 하면 정보 손실이 발생하고, 인셉션 먼저하고 풀링을 하면 계산 비용이 비쌈
◦
그걸 해결하기 위해 conv와 pooling을 쪼개고 다시 합침으로써 처리 함
•
그리고 앞선 버전에 있었던 auxiliary layer가 큰 도움이 안되서 없앰
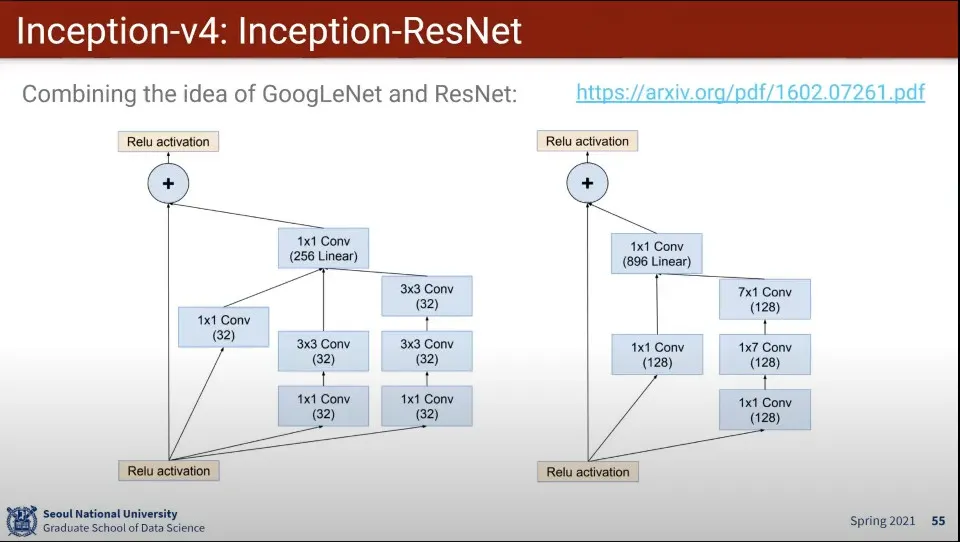
•
Inception v4에서는 ResNet의 아이디어를 차용해서 집대성 함
◦
중간에 건너뛸 수 있게
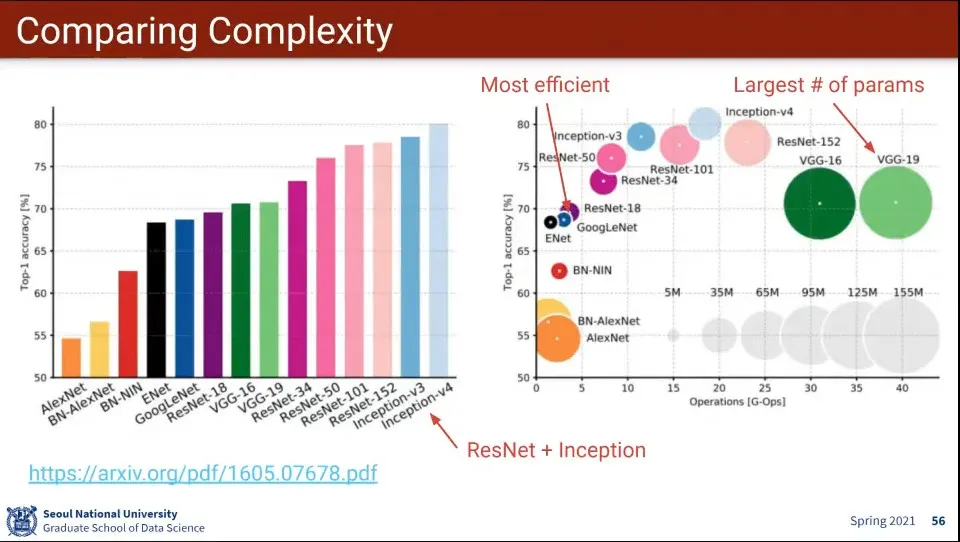
•
지금까지 나온 모델들의 성능
◦
왼쪽은 성능이고 오른쪽은 계산 비용을 고려한 성능
◦
Inception과 ResNet이 계산 비용과 성능이 모두 좋다.
•
최신 모델 경향은 정확도를 높이기 보다는 경량화에 있음
•
최신 경향은 모델 경량화
