Exponential distribution
•
exponential distribution은 감마 분포의 특별한 경우로 다음과 같이 정의된다.
•
이 분포는 푸아송 프로세스 즉, 사건이 상수 average rate 로 연속적이고 독립적으로 발생하는 프로세스에서 사건 사이의 시간을 설명한다.
Chi-squared distribution
•
chi-squared 분포는 감마 분포의 특별한 경우로 다음과 같이 정의된다.
•
여기서 는 자유도(degrees of freedom)이다. 이 분포는 제곱 가우시안 확률 변수의 합이다.
◦
더 정확하게 이고 이면 이다. 따라서 이면 .
◦
이고 이기 때문에 다음이 성립한다.
Inverse gamma
•
inverse gamma 분포는 을 가정하여 의 분포이다. 로 표기한다. pdf는 다음과 같이 정의된다.
•
평균은 일 때만 존재하고 분산은 일 때만 존재한다.
•
scaled inverse chi-squared 분포는 inverse gamma 분포의 reparametrization 한 것이다.
•
로 작성되는 일반 inverse chi-squared 분포는 인 특별한 경우이다. (즉 ). 이것은 에 해당한다.
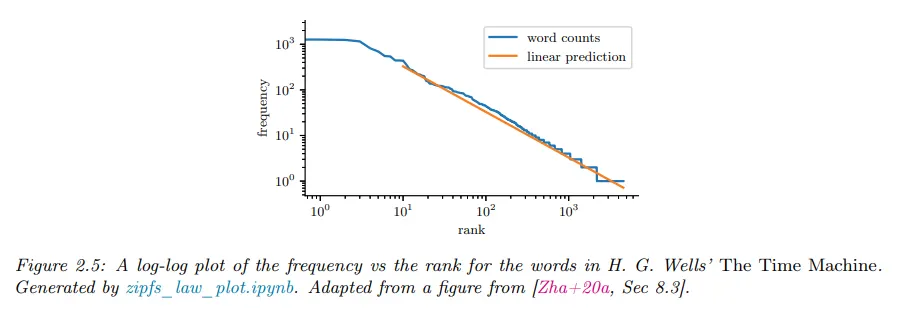
Pareto distribution
•
Pareto 분포는 다음의 pdf을 갖는다.
•
아래 그림 (a) 참조. 가 최소값 보다 크지만 그 이후에는 pdf가 급격히 감소하는 것을 볼 수 있다.
◦
log-log scale로 분포를 plot 하면 직선 가 된다. 여기서 이고 . 아래 그림 (b) 참조.
•
에서 분포는 형식을 갖고 이것은 멱 법칙(power law)이라고 한다.
◦
이면 분포는 형식이 되는데, 를 주파수로 해석하면 이것은 함수라고 부른다.
•
파레토 분포는 대부분의 값은 작지만 작은 수의 매우 큰 값이 존재하는 heavy tails나 long tails가 나타나는 수량의 분포를 모델링하는데 유용하다. 많은 데이터의 형식이 이 속성을 나타낸다.
◦
많은 데이터셋이 다양한 latent factor에 의해 생성되며, 이러한 요인들이 함께 섞이면 자연스럽게 무거운 꼬리를 가진 분포가 만들어지기 때문이라고 주장하기도 한다.
•
파레토 분포는 이탈리아의 경제학자이자 사회학자인 Vilfredo Pareto의 이름을 따서 붙여졌다. 그는 여러 나라에 걸쳐 부의 분포를 모델링하기 위해 이것을 만들었다.
◦
사실 경제학에서 파라미터 는 Pareto Index라 불린다. 을 설정하면 80-20 rule을 커버한다. 이것은 한 사회의 부의 80%를 인구의 20%가 보유한다는 뜻이다.
•
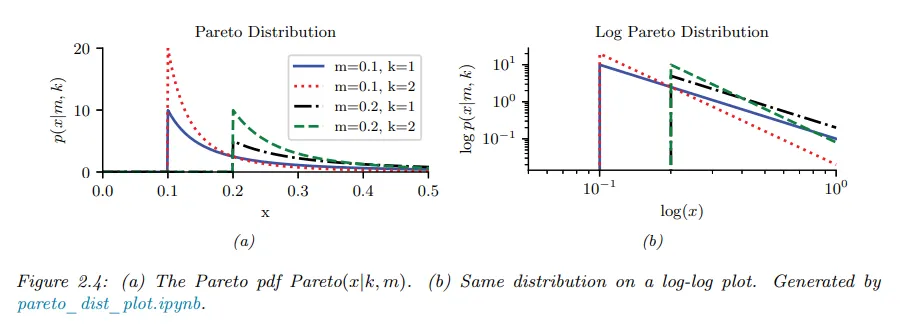
Zipf’s 법칙에 따르면 언어에서 가장 빈번하게 사용되는 단어는 (’the’ 같은) 2번째로 빈번하게 사용되는 단어 (’of’ 같은)에 대해 약 2배가 되고, 2번째 빈번하게 사용되는 단어는 다시 4번째로 사용되는 단어의 2배가 되는 현상이 나타난다. 이것은 다음 형식의 파레토 분포에 해당한다.
•
여기서 은 빈도수로 정렬했을 때 단어 의 랭크이다. 와 는 상수이다. 을 설정하면 Zipf’s 법칙을 복구한다.
◦
따라서 Zipf’s 법칙은 ‘log 빈도수 단어 vs 그것의 log rank’를 plot 하면 기울기 의 직선이 될 것이라고 예측한다. 이것은 사실이다. 아래 그림 참조.