

•
단어를 숫자로 표현하는게 word embedding
◦
단어를 d차원 유클리드 공간의 벡터로 표현한다.
◦
의미상으로 비슷한 단어들이 비슷한 영역에 모여있도록 하는게 핵심
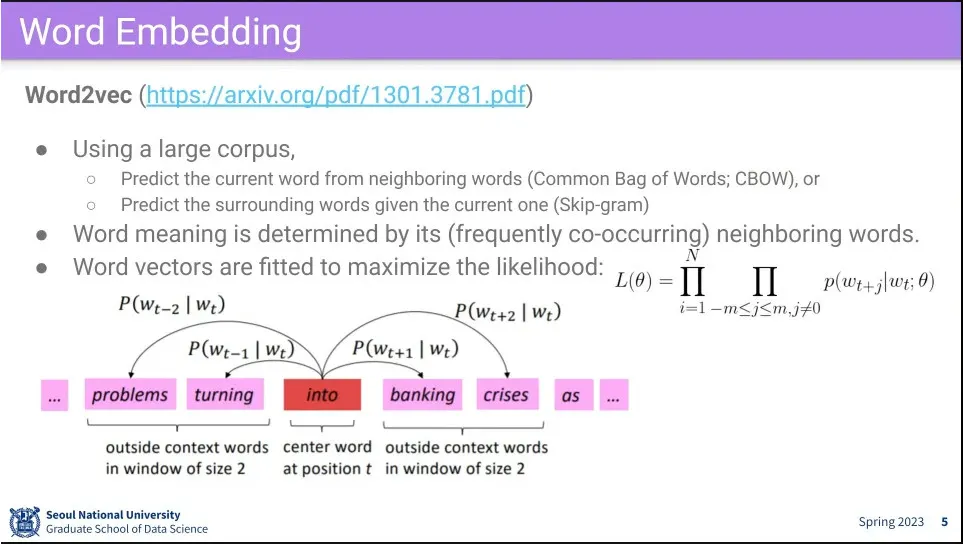
•
딥러닝 초기에 나온 단어를 임베팅한 모델이 Word Embedding
◦
단어의 정의를 보지 않고, 문장에서 어떤 단어들과 함께 쓰이는지를 보고 Embedding 함.
◦
주변 단어를 보고 현재 단어를 보는 것, 또는 현재 단어를 보고 주변 단어를 예측하는 것을 훈련 함.

•
그 다음으로 나온 word embedding 모델이 GloVe
◦
단어의 관계를 표현하고 있다는게 특징

•
단어의 관계가 표현이 되서 단어간의 연산이 가능함.
◦
queen에서 woman을 빼고 man을 더하면 king이 된다.
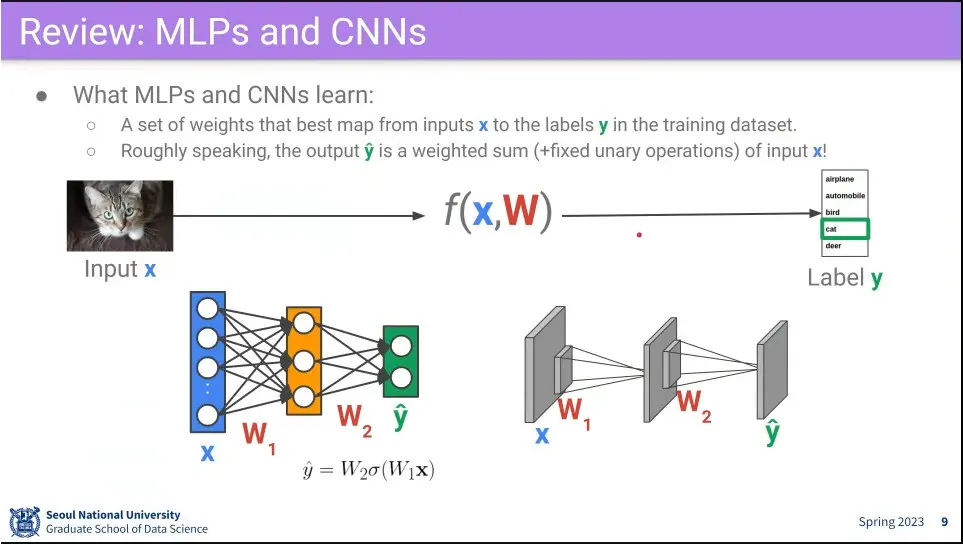

•
Fully-connected, CNN, RNN의 동작 방식
◦
결국 input에 대해 적절한 weight sum을 해주는 과정이고, 목표는 weight 값을 찾는 것
•
Transformer에서는 input을 유기적으로 결합되어 있는 더 작은 element의 집합이나 sequence로 봄.
◦
예컨대 사람은 사회 관계에서 정의되고, 단어는 문장 안에서 의미가 나옴
•
그래서 attention을 self에 대해 함.
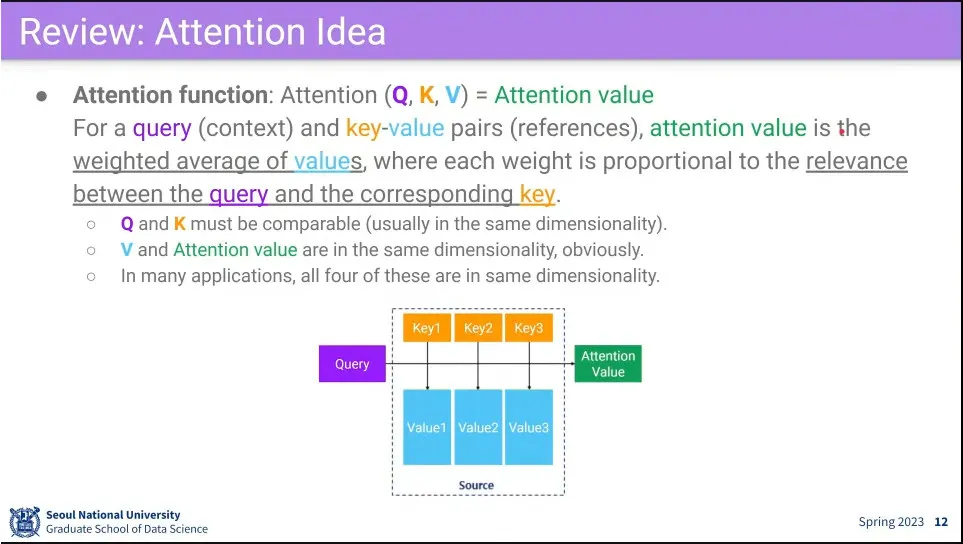
•
attention 구조
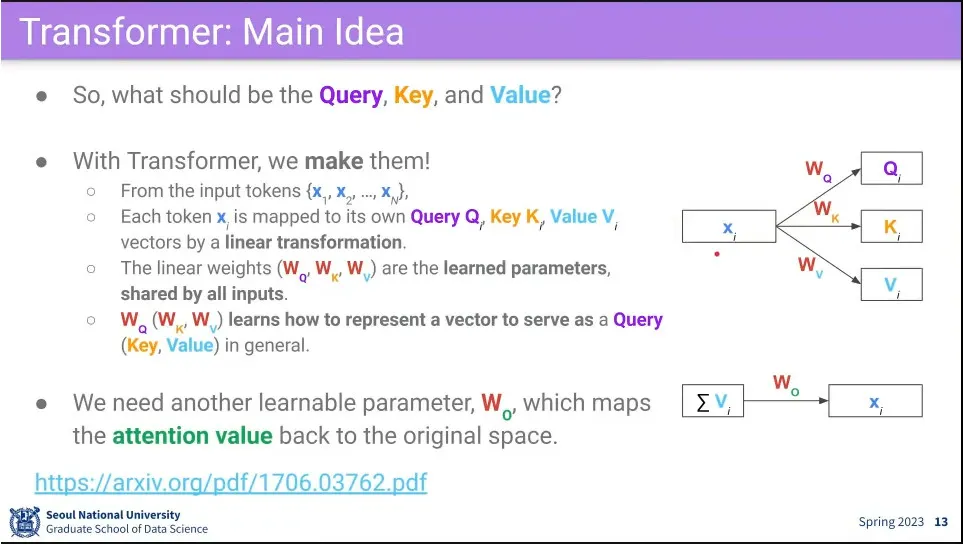
•
self-attention을 위해 input 자신을 query, key, value로 매핑해 주는 를 만들어 줌.
◦
그렇게 해서 input이 query, key, value로 어떻게 쓰이는지를 배우게 됨.
•
그렇게 만들어진 로 연산을 하고 처음 크기로 되돌려 주기 위해 추가로 를 만들어 줌.
•
최종적으로 4가지를 학습하게 됨.
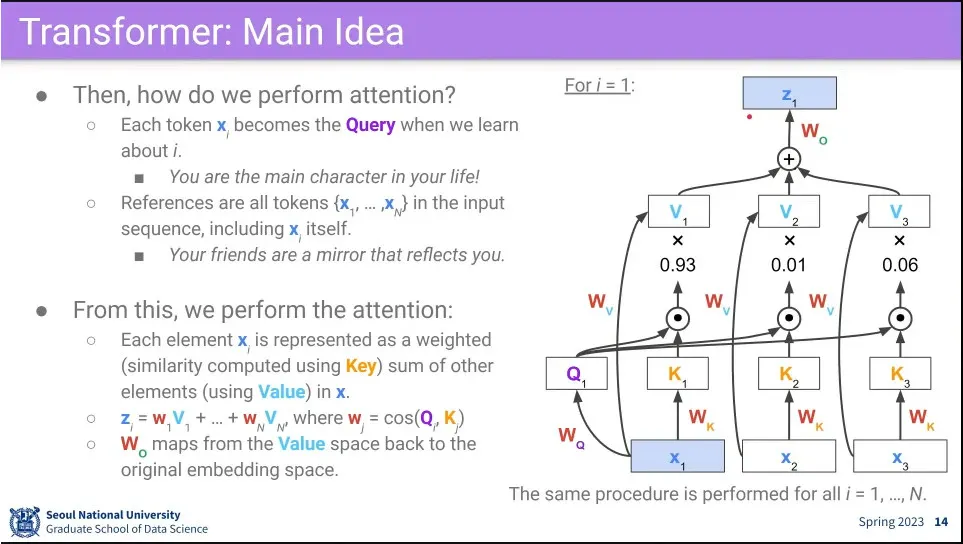
•
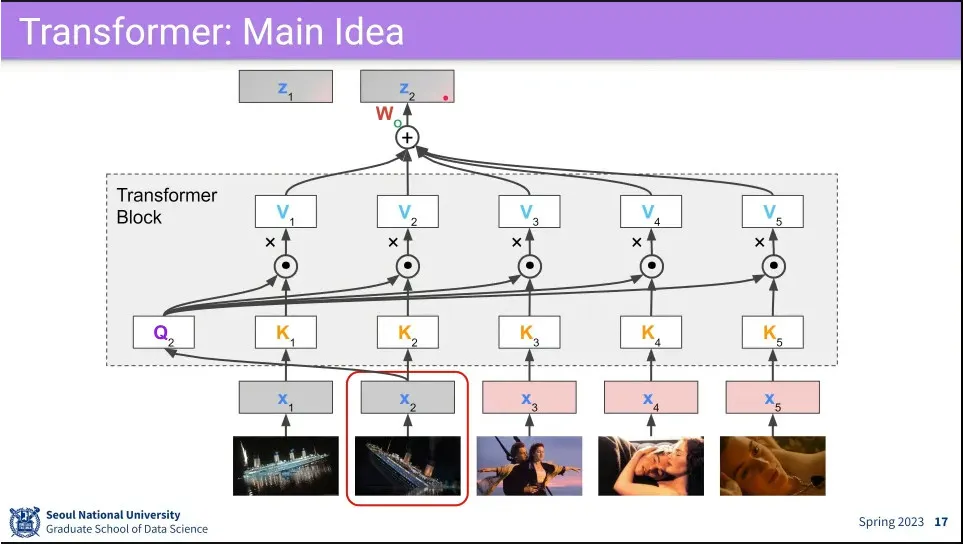
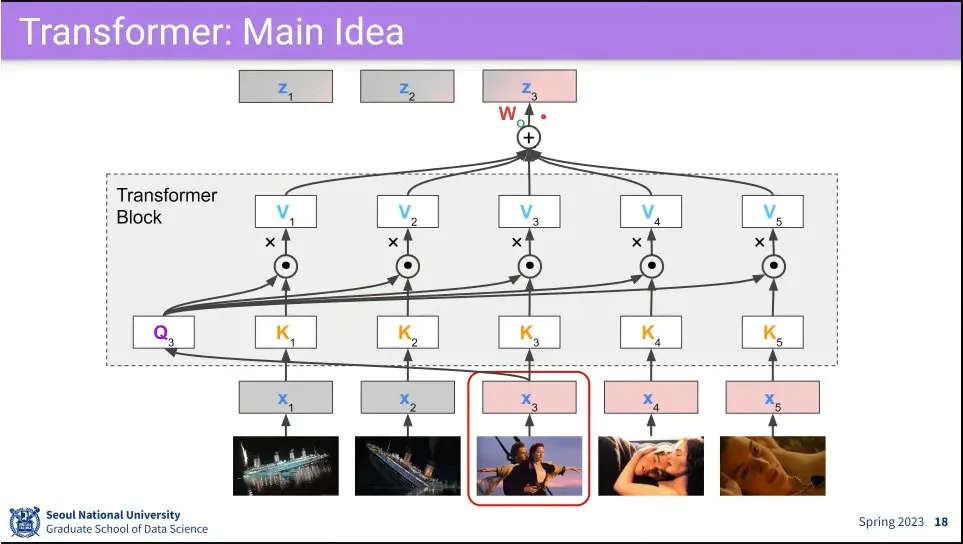
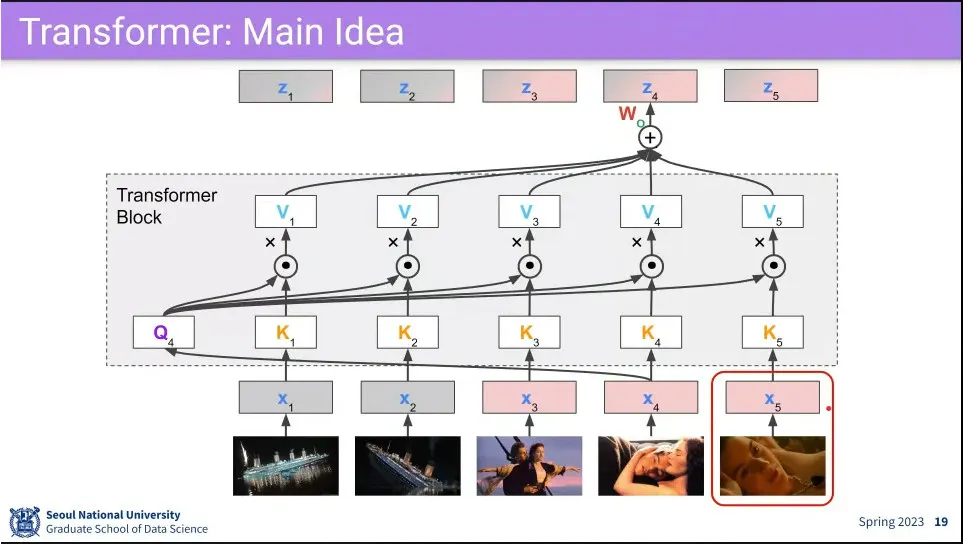
Self-attention 과정
1.
최초 모든 input 에 대해 를 곱해서 각각 를 만들어 둠.
2.
먼저 을 모든 와 내적을 함.
3.
그렇게 만들어진 각각의 결과에 대해 softmax를 씌움.
4.
3의 각각의 결과에 대해 을 내적 함.
5.
4의 모든 결과를 concatenate 한 뒤 를 곱해서 최초 input 크기로 되돌림
6.
2번으로 되돌아가서 에 대해 반복
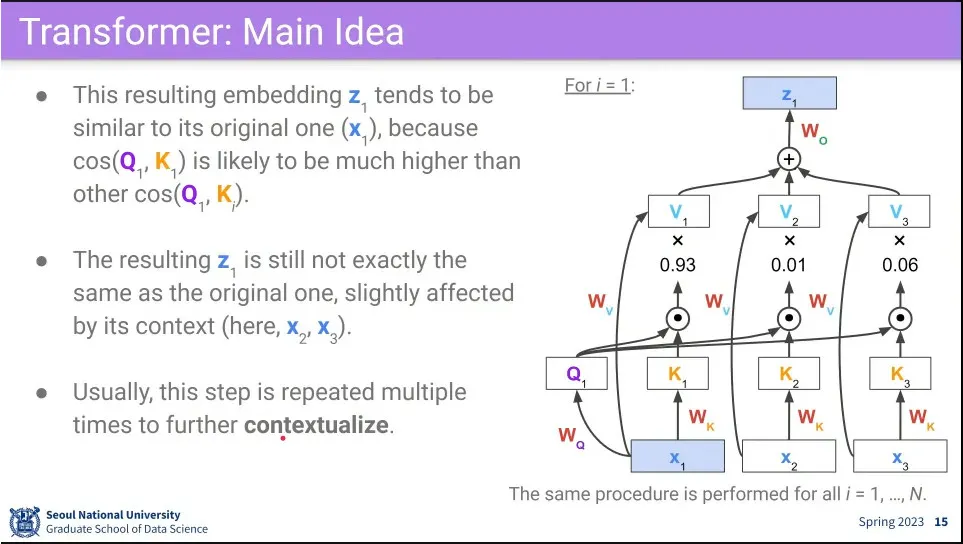
•
위 과정을 통해 은 으로 바뀌게 되는데, 이 과정에서 여전히 자기 자신에 대해 가장 높은 가중치를 갖지만 주변 input들의 정보가 조금씩 반영 되게 됨.
◦
이렇게 변환한다는 뜻에서 Transformer라고 함.
◦
최초 input에 주위 문맥을 섞는 것이 되기 때문에 contextualize라고 함.
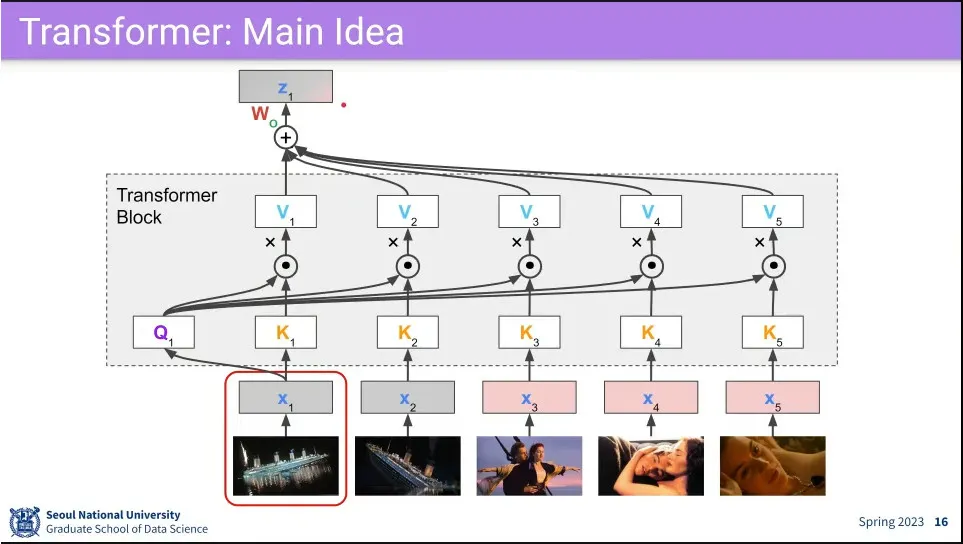
•
예시
◦
최종적으로 에 회색과 핑크색이 조금씩 뭍어서 나옴.
•
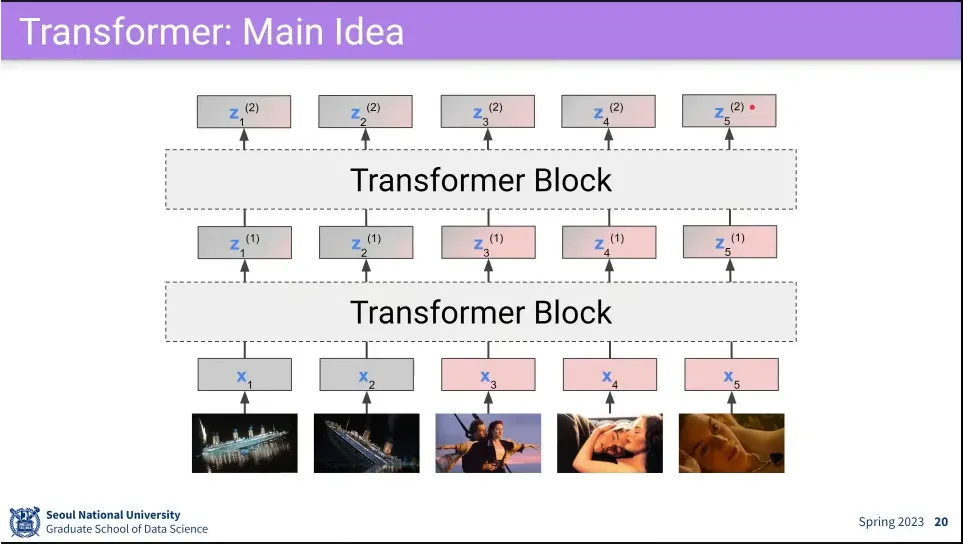
transformer를 block으로 만들고 여러 층을 쌓을 수 있음.

•
세부 구현을 위한 질문들
•
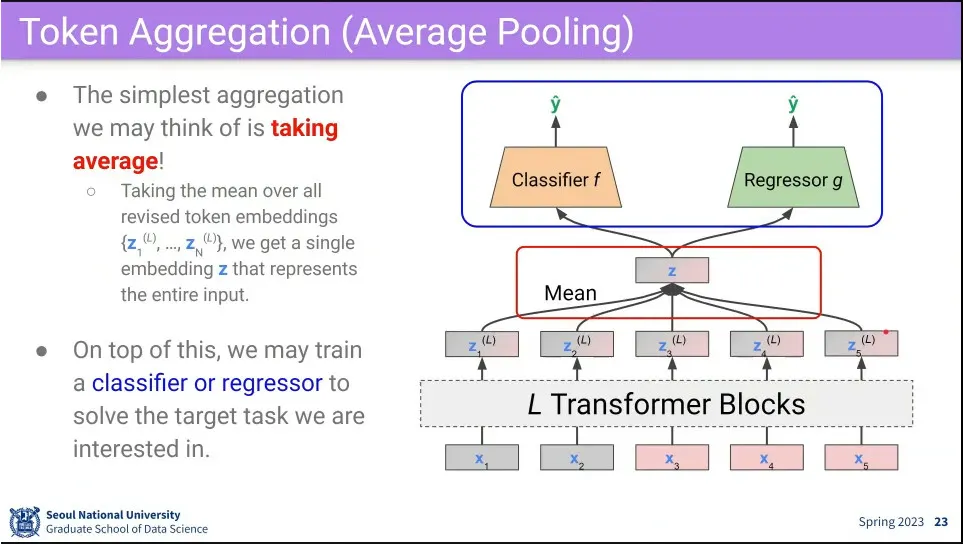
transformer 결과에 대해 평균내고 classifier나 regressor를 달아서 처리할 수 있음.
•
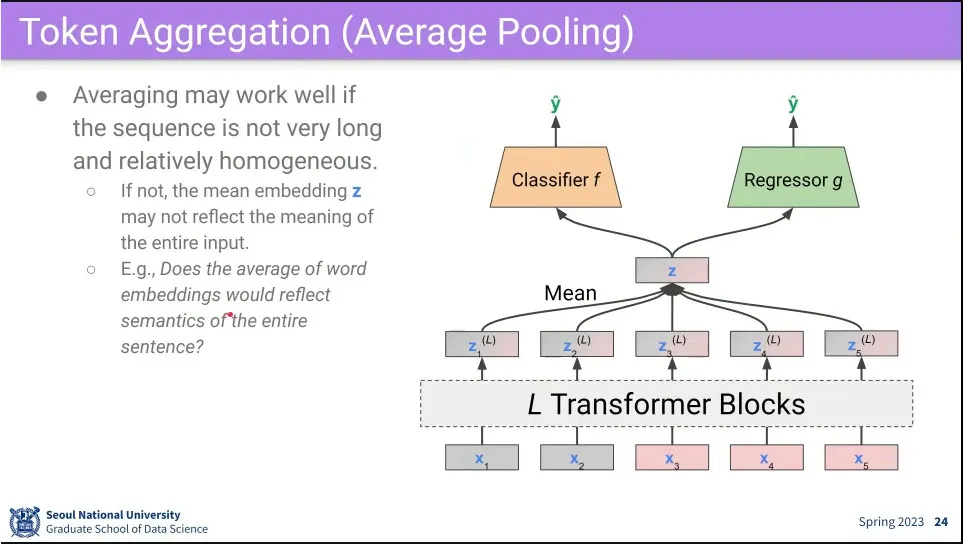
input이 짧으면 잘 동작 하지만, input이 길면 단순 평균 내는게 애매 함.
•
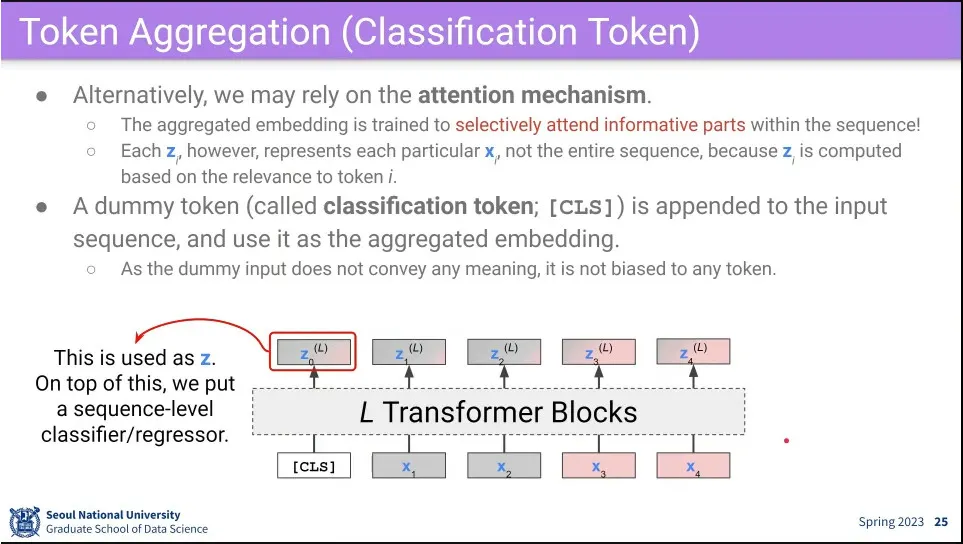
그래서 아예 dummy로 token을 만들어서 Transformer Block을 돌리면, input 중 어디에 attention 할지를 배우게 할 수 있음.
•
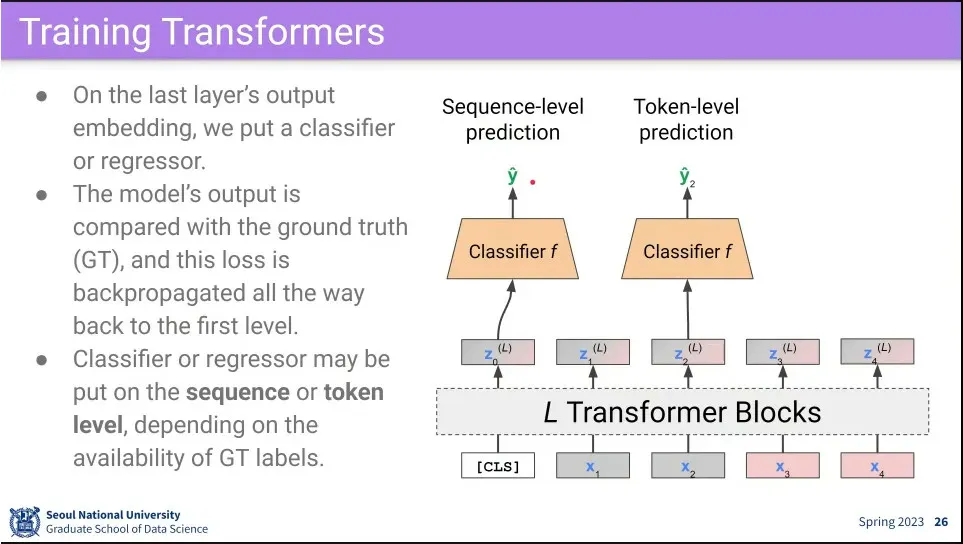
dummy token이 input 전체를 대표하기 때문에 거기에 classifier를 달면 input 전체에 대한 분류가 가능하고, 개별 input 마다 classifier를 달면 token level로 분류가 가능함.
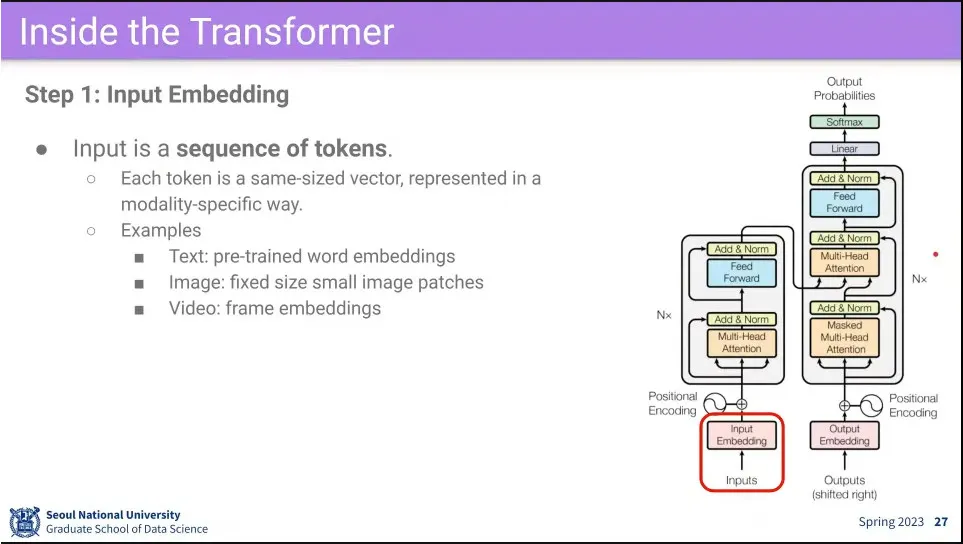
•
최초 Transformer 모델 모습. seq2seq 문제를 풀기 위해 encoder와 decoder로 구분됨.
•
가장 먼저 input에 대해 embedding을 함.
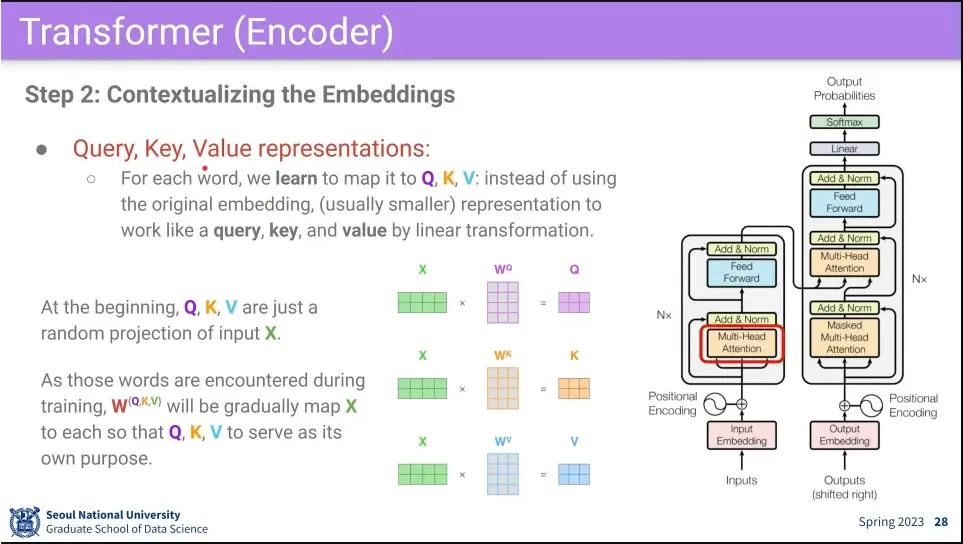
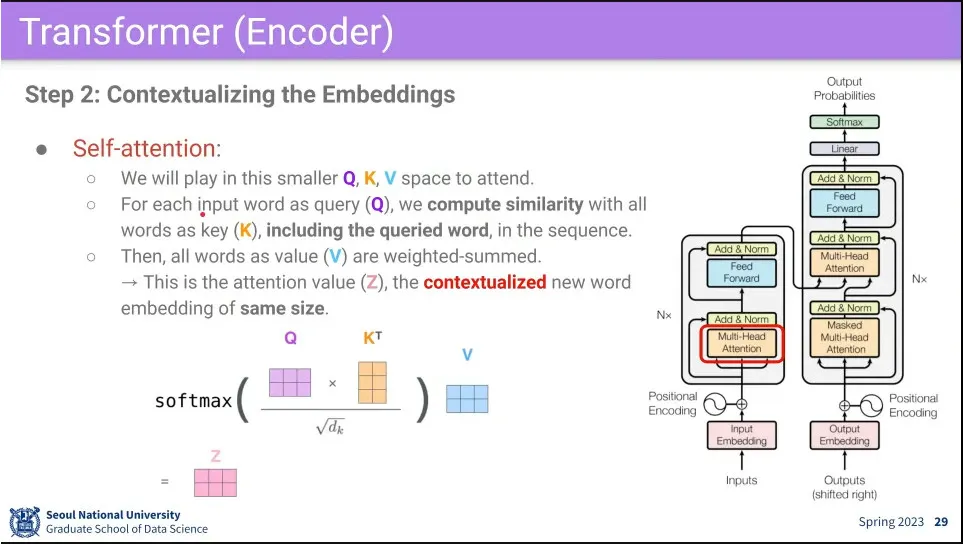
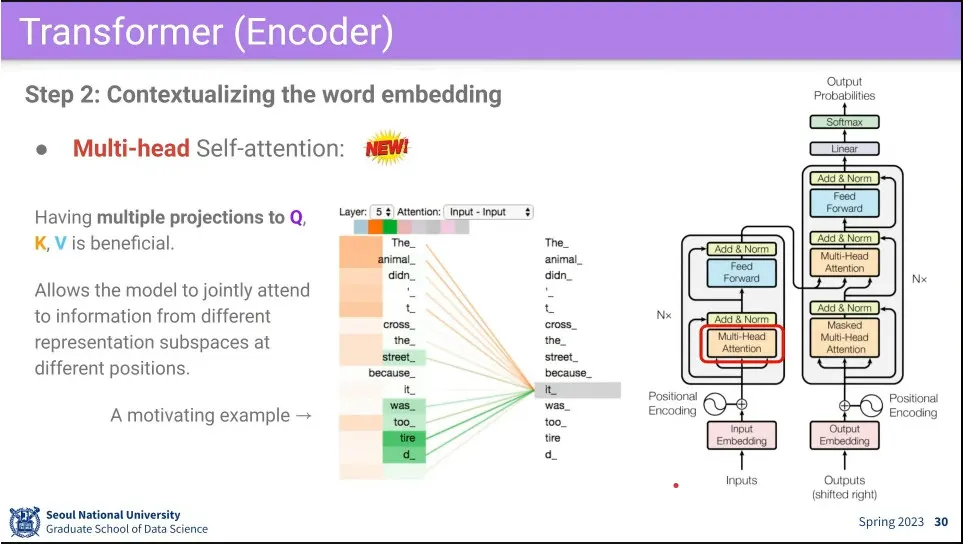
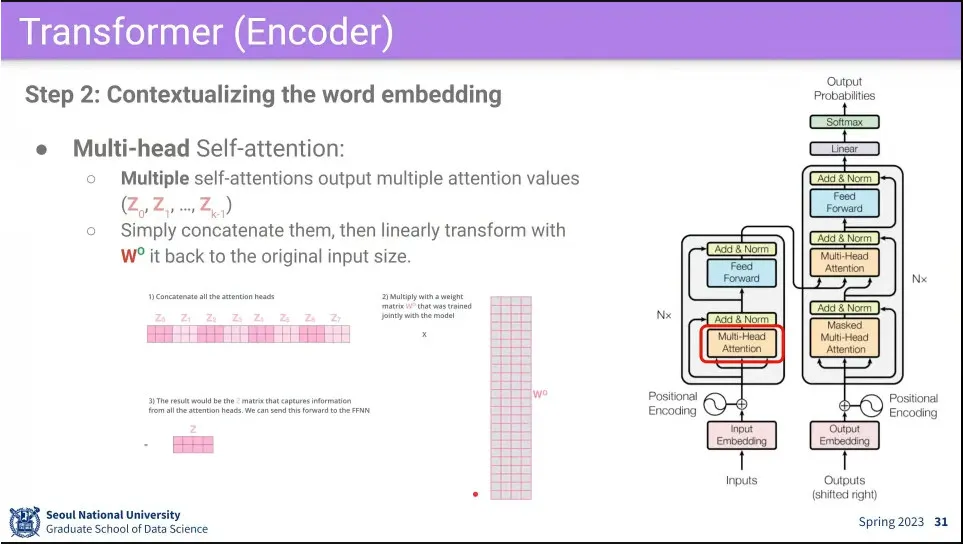
•
다음으로 embedding 된 input에 대해 multi-head self-attention을 수행함
◦
의 곱이 너무 커지지 않도록 그 곱의 결과를 로 나눈 후에 softmax를 통과함.
•
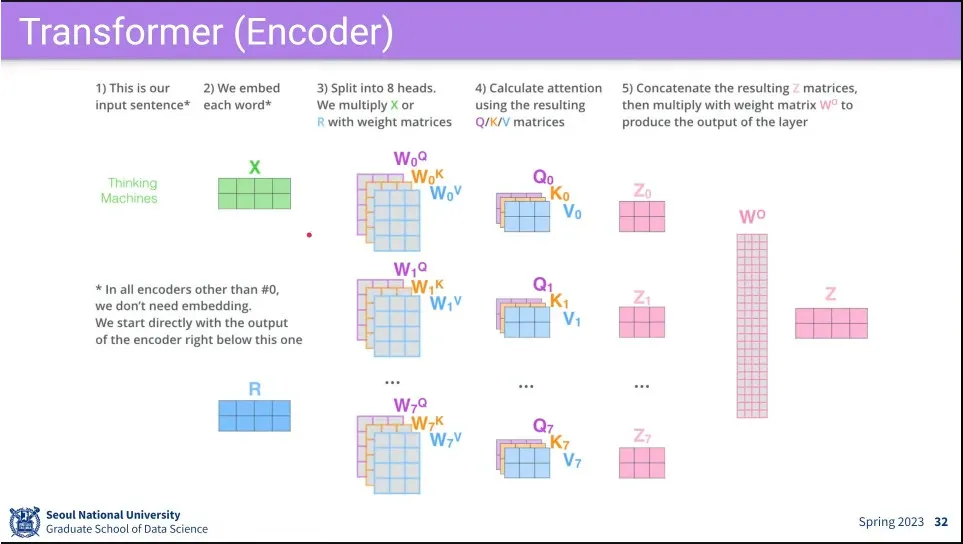
Multi-Head은 head를 여러 개 주고 attention 여러 번 돌린다는 뜻.
◦
보통은 8개, 4개를 두고 돌린다.
◦
(쉬운 이해를 위해 설명에는 Multi-Head에서 마치 크기가 head만큼 커진 후에 원래 크기로 줄어드는 것으로 설명되는데, 실제 구현할 때는 거꾸로 head로 나눈 크기로 줄인 후에 원래 크기로 늘리는 식으로 쓴다. 계산량과 메모리 효율을 위함. 실제 성능은 동일하다고 함)
•
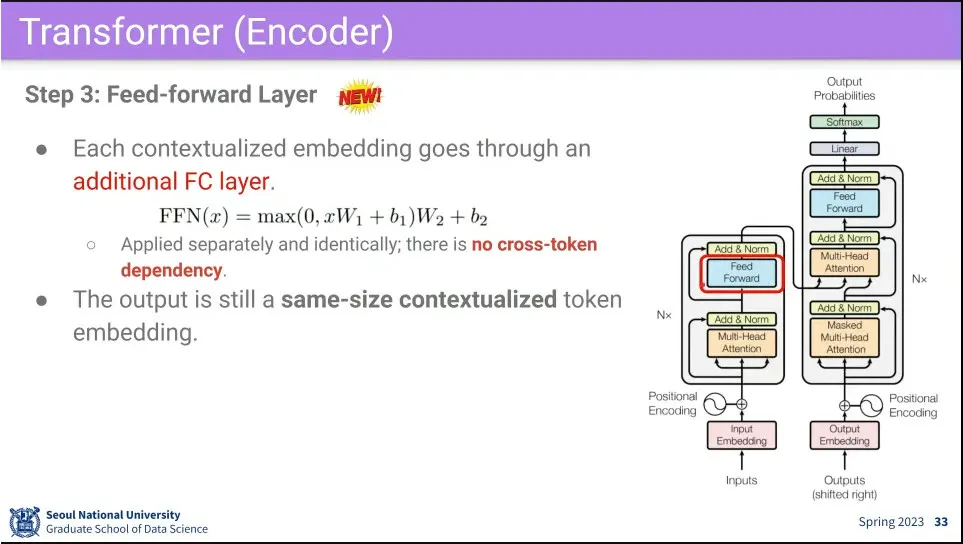
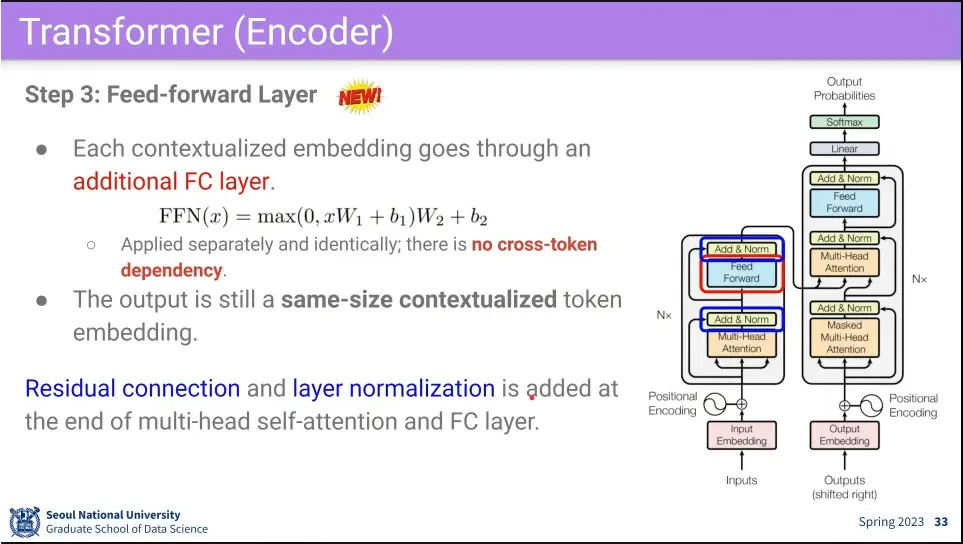
Multi-Head Attention을 지난 후에는 Fully-Connected를 통한다.
•
Attention block과 fully-connected 다음에는 residual connection과 layer norm을 해준다.
◦
residual connection은 block를 깊게 쌓기 위해 필
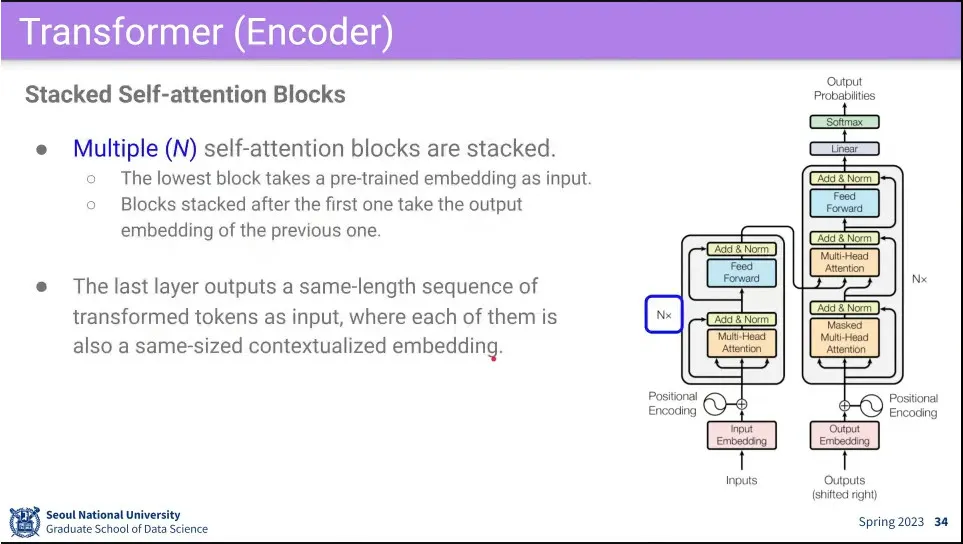
•
이 전체 과정을 N번 쌓는다.
•
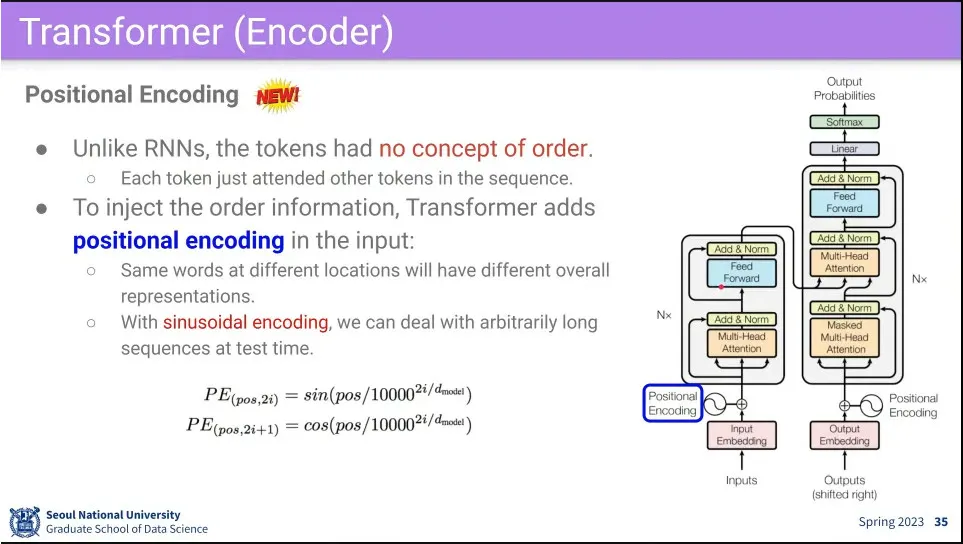
Transformer는 순서에 무관하기 때문에, input에 순서가 중요한 경우, 순서 정보를 반영하기 위해 positional encoding을 해 줌
•
수식 설명
◦
일단 짝수는 sin 곡선을 쓰고, 홀수는 cos 곡선을 씀.
◦
은 모델 설계 때 정해진 값 64 거나 32 거나 등.
◦
i는 0부터 까지 반복
◦
위의 설정으로 은 0에서 1까지의 값을 갖게 됨.
◦
고로 은 1부터 0까지의 값을 갖게 되는데, i가 작을수록 값의 빠르게 증가하고, i가 클수록 작게 증가함.
◦
단어의 위치 (pos)를 그렇게 구한 값으로 나눈 후 최종적으로 sin, cos 함수를 씌움.
•
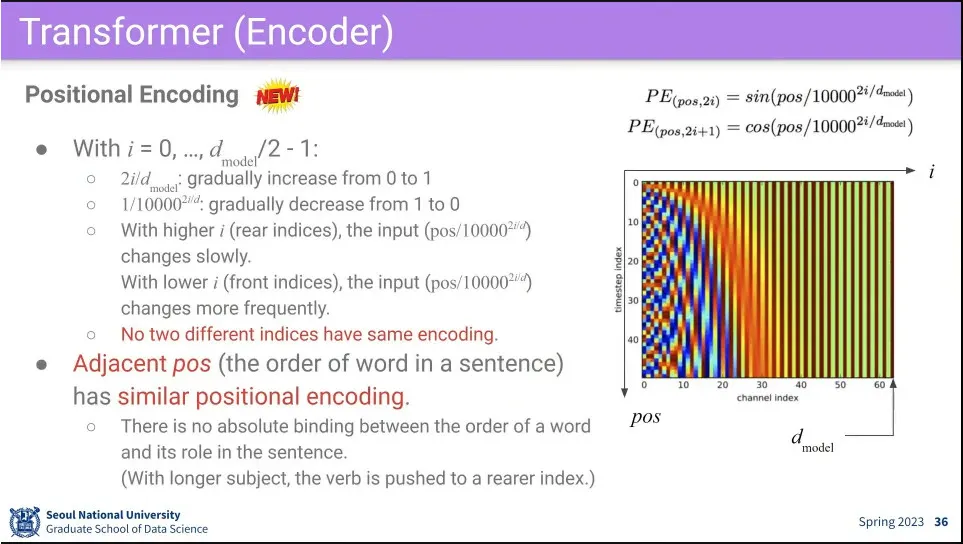
그냥 sin, cos 함수만 씌우면 두 함수는 주기성을 갖기 때문에 같은 값을 갖는 position이 나올 수 있음. 따라서 을 이용해서 앞쪽에서는 값이 빠르게 증가하고, 뒤로 갈수록 값이 느리게 증가하도록 설정해서 전체적으로 position이 unique한 값을 갖도록 만들어 줌.
◦
position 값이 선형적으로 증가 혹은 감소하는 값이 아니라 unique한 값을 만들어준다는게 중요.
•
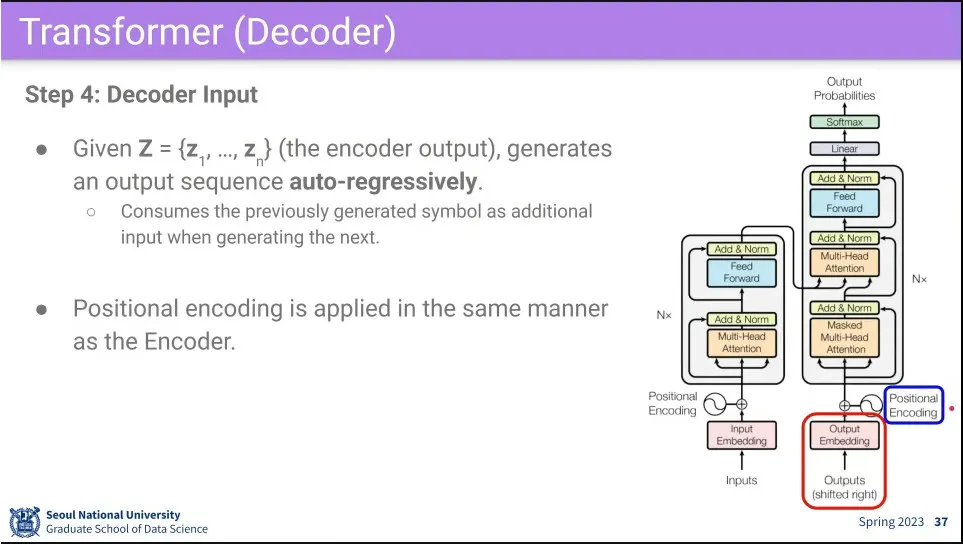
decoder의 input은 decoder의 output을 auto-regressively 하게 사용한다.
◦
그 input에도 똑같이 positional encoding을 추가해 줌.
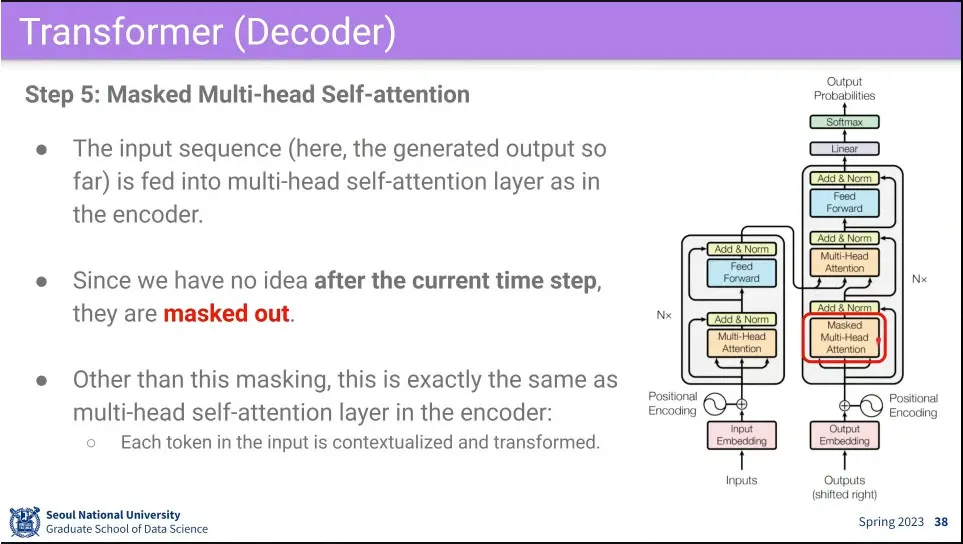
•
그 다음으로 Input과 비슷한 Multi-Head Self-Attention을 수행함.
◦
다만 input에 mask를 씌워서 처리 함.
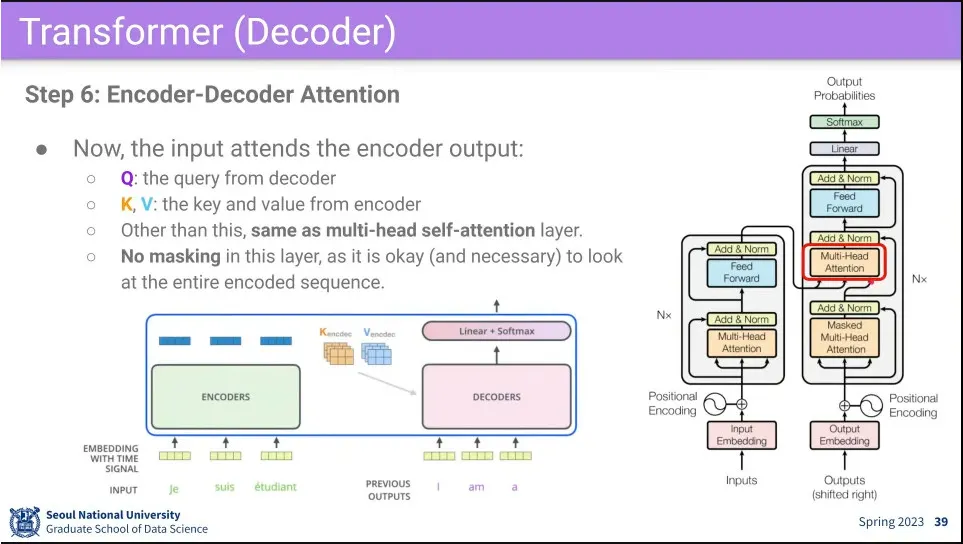
•
그 다음에 Attention block을 한 번 더 돌리는데, 이때 encoder의 데이터를 참조해서 처리하는게 다름.
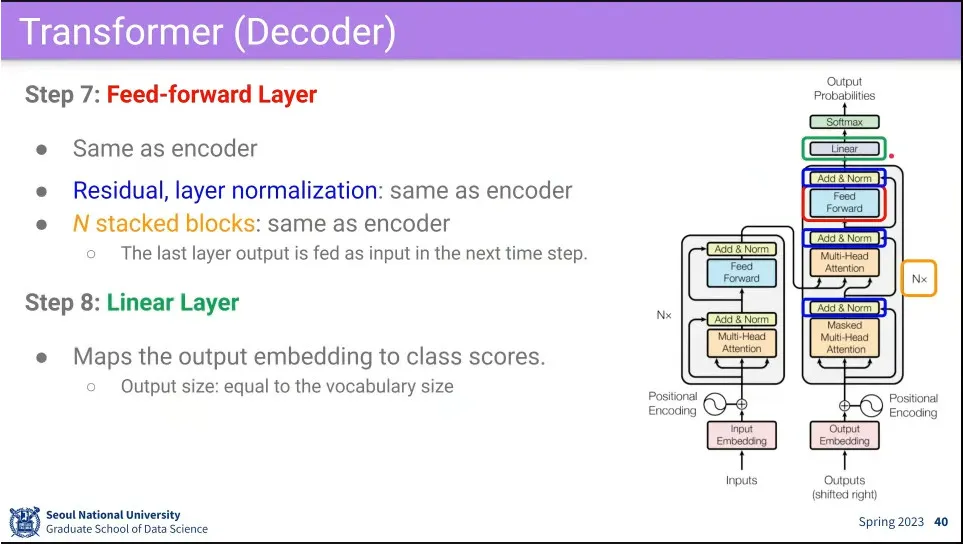
•
fully-connected, residual, layer norm 모두 동일하고, N번 반복.
•
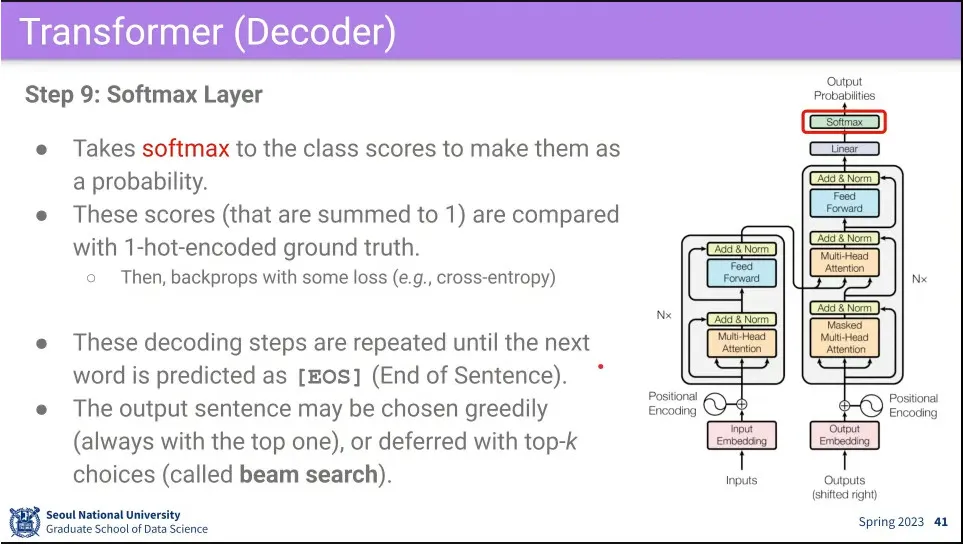
최종적으로 Linear를 통과시킨 후 softmax를 씌워서 output을 출력한다.
•
Decoder는 [EOS](end of sentence)라는 토큰이 나올 때까지 반복한다.
•
출력을 항상 최고 값만 쓰면 (greedy) 한 단어라도 틀렸을 때 이후가 다 틀릴 수 있기 때문에, 상위 몇 개를 유지하는게 beam search)

•
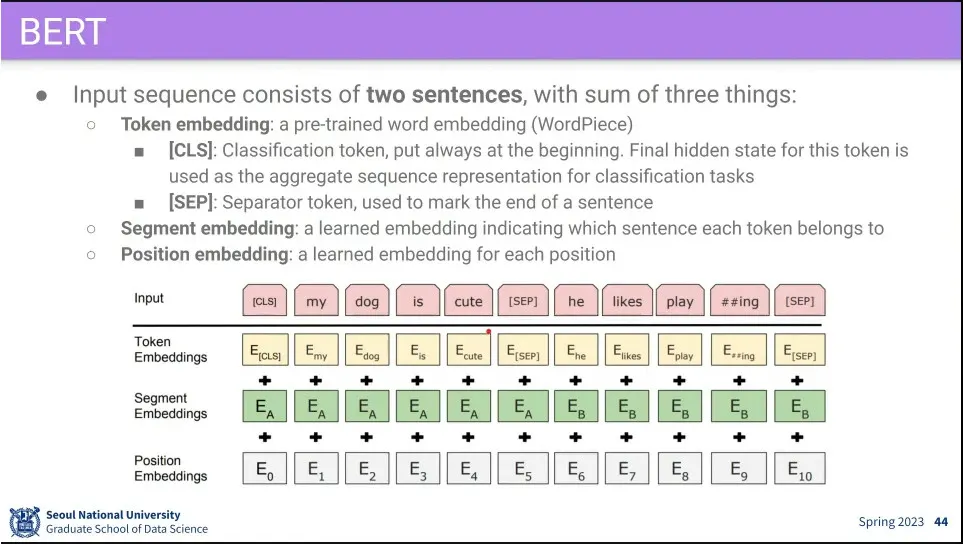
BERT는 transformer의 encoder 부분을 이용한 embedder.
◦
요즘에는 BERT Embedder를 쓰고 이전의 embedding은 잘 안 쓴다고 함.
•
BERT에는 Token, Segment(어느 문장에 속하는지), Position Embedding을 사용한다.

•
문장에 빈칸을 주고 단어를 맞추게 하는 식으로 훈련 시키는 것이 Masked Language Modeling(MLM)이라고 함.
◦
이것의 효과가 매우 큼.

•
다음 문장을 예측하게 하는게 NSP
◦
문장과 문장 사이의 관계를 배우게 하기 위함.
•
논문에서는 둘 다 중요하다고 했는데, 이후 다른 논문들에서는 NSP는 보조적이거나 별 영향이 없는 걸로 밝혀지고 MLM이 매우 중요하다고 밝혀짐
